mirror of
https://github.com/facebookresearch/pytorch3d.git
synced 2026-03-01 17:56:00 +08:00
Compare commits
530 Commits
v0.3.0
...
classner-p
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
e7c1f026ea | ||
|
|
cb49550486 | ||
|
|
36edf2b302 | ||
|
|
78bb6d17fa | ||
|
|
54c75b4114 | ||
|
|
3783437d2f | ||
|
|
b2dc520210 | ||
|
|
8597d4c5c1 | ||
|
|
38fd8380f7 | ||
|
|
67840f8320 | ||
|
|
9b2e570536 | ||
|
|
0f966217e5 | ||
|
|
379c8b2780 | ||
|
|
8e0c82b89a | ||
|
|
8ba9a694ee | ||
|
|
36ba079bef | ||
|
|
b95ec190af | ||
|
|
55f67b0d18 | ||
|
|
4261e59f51 | ||
|
|
af55ba01f8 | ||
|
|
d3b7f5f421 | ||
|
|
4ecc9ea89d | ||
|
|
8d10ba52b2 | ||
|
|
aa8b03f31d | ||
|
|
57a40b3688 | ||
|
|
522e5f0644 | ||
|
|
e8390d3500 | ||
|
|
4300030d7a | ||
|
|
00acf0b0c7 | ||
|
|
a94f3f4c4b | ||
|
|
efb721320a | ||
|
|
40fb189c29 | ||
|
|
4e87c2b7f1 | ||
|
|
771cf8a328 | ||
|
|
0dce883241 | ||
|
|
ae35824f21 | ||
|
|
f4dd151037 | ||
|
|
7ce8ed55e1 | ||
|
|
7e0146ece4 | ||
|
|
0e4c53c612 | ||
|
|
879495d38f | ||
|
|
5c1ca757bb | ||
|
|
3e4fb0b9d9 | ||
|
|
731ea53c80 | ||
|
|
2e42ef793f | ||
|
|
81d63c6382 | ||
|
|
28c1afaa9d | ||
|
|
cba26506b6 | ||
|
|
65f667fd2e | ||
|
|
7978ffd1e4 | ||
|
|
ea4f3260e4 | ||
|
|
023a2369ae | ||
|
|
c0f88e04a0 | ||
|
|
6275283202 | ||
|
|
1d43251391 | ||
|
|
1fb268dea6 | ||
|
|
8bc0a04e86 | ||
|
|
5cd70067e2 | ||
|
|
5b74a2cc27 | ||
|
|
49ed7b07b1 | ||
|
|
c6519f29f0 | ||
|
|
a42a89a5ba | ||
|
|
c31bf85a23 | ||
|
|
fbd3c679ac | ||
|
|
34f648ede0 | ||
|
|
f625fe1f8b | ||
|
|
7c25d34d22 | ||
|
|
c5a83f46ef | ||
|
|
1702c85bec | ||
|
|
90d00f1b2b | ||
|
|
d27ef14ec7 | ||
|
|
2d1c6d5d93 | ||
|
|
9fe15da3cd | ||
|
|
0f12c51646 | ||
|
|
79c61a2d86 | ||
|
|
69c6d06ed8 | ||
|
|
73dc109dba | ||
|
|
9ec9d057cc | ||
|
|
cd7b885169 | ||
|
|
f632c423ef | ||
|
|
f36b11fe49 | ||
|
|
ea5df60d72 | ||
|
|
4372001981 | ||
|
|
61e2b87019 | ||
|
|
0143d63ba8 | ||
|
|
899a3192b6 | ||
|
|
3b2300641a | ||
|
|
b5f3d3ce12 | ||
|
|
2c1901522a | ||
|
|
90ab219d88 | ||
|
|
9e57b994ca | ||
|
|
e767c4b548 | ||
|
|
e85fa03c5a | ||
|
|
47d06c8924 | ||
|
|
bef959c755 | ||
|
|
c21ba144e7 | ||
|
|
d737a05e55 | ||
|
|
2374d19da5 | ||
|
|
1f3953795c | ||
|
|
a6dada399d | ||
|
|
5c59841863 | ||
|
|
2c64635daa | ||
|
|
ec9580a1d4 | ||
|
|
44cb00e468 | ||
|
|
44ca5f95d9 | ||
|
|
a51a300827 | ||
|
|
2bd65027ca | ||
|
|
11635fbd7d | ||
|
|
a268b18e07 | ||
|
|
7ea0756b05 | ||
|
|
96889deab9 | ||
|
|
9f443ed26b | ||
|
|
9320100abc | ||
|
|
2edb93d184 | ||
|
|
41c594ca37 | ||
|
|
c3c4495c7a | ||
|
|
34bbb3ad32 | ||
|
|
df08ea8eb4 | ||
|
|
78fd5af1a6 | ||
|
|
0a7c354dc1 | ||
|
|
b79764ea69 | ||
|
|
b1ff9d9fd4 | ||
|
|
22f86072ca | ||
|
|
050f650ae8 | ||
|
|
8596fcacd2 | ||
|
|
7f097b064b | ||
|
|
aab95575a6 | ||
|
|
67fff956a2 | ||
|
|
4b94649f7b | ||
|
|
3809b6094c | ||
|
|
722646863c | ||
|
|
e10a90140d | ||
|
|
4c48beb226 | ||
|
|
4db9fc11d2 | ||
|
|
3b8a33e9c5 | ||
|
|
199309fcf7 | ||
|
|
6473aa316c | ||
|
|
2802fd9398 | ||
|
|
a999fc22ee | ||
|
|
24260130ce | ||
|
|
a54ad2b912 | ||
|
|
b602edccc4 | ||
|
|
21262e38c7 | ||
|
|
e332f9ffa4 | ||
|
|
0c3bed55be | ||
|
|
97894fb37b | ||
|
|
645a47d054 | ||
|
|
8ac5e8f083 | ||
|
|
92f9dfe9d6 | ||
|
|
f2cf9d4d0b | ||
|
|
e2622d79c0 | ||
|
|
c0bb49b5f6 | ||
|
|
05f656c01f | ||
|
|
4c22855a23 | ||
|
|
cdd2142dd5 | ||
|
|
0e377c6850 | ||
|
|
e64f25c255 | ||
|
|
c85673c626 | ||
|
|
3de3c13a0f | ||
|
|
9b5a3ffa6c | ||
|
|
1701b76a31 | ||
|
|
57a33b25c1 | ||
|
|
c371a9a6cc | ||
|
|
4a1f176054 | ||
|
|
16d0aa82c1 | ||
|
|
69b27d160e | ||
|
|
84a569c0aa | ||
|
|
471b126818 | ||
|
|
4d043fc9ac | ||
|
|
f816568735 | ||
|
|
0e88b21de6 | ||
|
|
1cbf80dab6 | ||
|
|
ee71c7c447 | ||
|
|
3de41223dd | ||
|
|
967a099231 | ||
|
|
feb5d36394 | ||
|
|
db1f7c4506 | ||
|
|
59972b121d | ||
|
|
c8f3d6bc0b | ||
|
|
2a1de3b610 | ||
|
|
ef21a6f6aa | ||
|
|
12f20d799e | ||
|
|
47c0997227 | ||
|
|
e9fb6c27e3 | ||
|
|
c2862ff427 | ||
|
|
5053142363 | ||
|
|
67778caee8 | ||
|
|
3eb4233844 | ||
|
|
174738c33e | ||
|
|
45d096e219 | ||
|
|
39bb2ce063 | ||
|
|
9e2bc3a17f | ||
|
|
fddd6a700f | ||
|
|
85cdcc252d | ||
|
|
fc4dd80208 | ||
|
|
9640560541 | ||
|
|
6726500ad3 | ||
|
|
d6a12afbe7 | ||
|
|
49f93b6388 | ||
|
|
741777b5b5 | ||
|
|
9eeb456e82 | ||
|
|
7660ed1876 | ||
|
|
52c71b8816 | ||
|
|
f9a26a22fc | ||
|
|
d67662d13c | ||
|
|
28ccdb7328 | ||
|
|
cc3259ba93 | ||
|
|
b51be58f63 | ||
|
|
7449951850 | ||
|
|
262c1bfcd4 | ||
|
|
eb2bbf8433 | ||
|
|
1152a93b72 | ||
|
|
315f2487db | ||
|
|
ccfb72cc50 | ||
|
|
069c9fd759 | ||
|
|
9eec430f1c | ||
|
|
f8fe9a2be1 | ||
|
|
d049cd2e01 | ||
|
|
1edc624d82 | ||
|
|
6ea6314792 | ||
|
|
093999e71f | ||
|
|
a22b1e32a4 | ||
|
|
9c9d9440f9 | ||
|
|
c65af9ef5a | ||
|
|
70acb3e415 | ||
|
|
bf3bc6f8e3 | ||
|
|
cff4876131 | ||
|
|
a0e2d2e3c3 | ||
|
|
a6508ac3df | ||
|
|
d9f709599b | ||
|
|
e4456dba2f | ||
|
|
7fa333f632 | ||
|
|
a0247ea6bd | ||
|
|
a8cb7fa862 | ||
|
|
7ce18f38cd | ||
|
|
5fbdb99aec | ||
|
|
1836c786fe | ||
|
|
cac6cb1b78 | ||
|
|
bfeb82efa3 | ||
|
|
73a14d7266 | ||
|
|
bee31c48d3 | ||
|
|
29417d1f9b | ||
|
|
57b9c729b8 | ||
|
|
7c111f7379 | ||
|
|
3953de47ee | ||
|
|
1a7442a483 | ||
|
|
16ebf54e69 | ||
|
|
14dd2611ee | ||
|
|
34b1b4ab8b | ||
|
|
2f2466f472 | ||
|
|
53d99671bd | ||
|
|
6d36c1e2b0 | ||
|
|
6dfa326922 | ||
|
|
b26f4bc33a | ||
|
|
8fa438cbda | ||
|
|
815a93ce89 | ||
|
|
23ef666db1 | ||
|
|
d7d740abe9 | ||
|
|
9585a58d10 | ||
|
|
364a7dcaf4 | ||
|
|
1360d69ffb | ||
|
|
4281df19ce | ||
|
|
ee2b2feb98 | ||
|
|
9ad98c87c3 | ||
|
|
0dfc6e0eb8 | ||
|
|
c7c6deab86 | ||
|
|
4ad8576541 | ||
|
|
a5cbb624c1 | ||
|
|
720bdf60f5 | ||
|
|
1aab192706 | ||
|
|
dd76b41014 | ||
|
|
1b1ba5612f | ||
|
|
ff8d4762f4 | ||
|
|
53266ec9ff | ||
|
|
2293f1fed0 | ||
|
|
5b89c4e3bb | ||
|
|
d0ca3b9e0c | ||
|
|
9a737da83c | ||
|
|
860b742a02 | ||
|
|
cb170ac024 | ||
|
|
fe5bfa5994 | ||
|
|
dbfb3a910a | ||
|
|
526df446c6 | ||
|
|
bd04ffaf77 | ||
|
|
d9f7611c4b | ||
|
|
3b7d78c7a7 | ||
|
|
a0d76a7080 | ||
|
|
46f727cb68 | ||
|
|
c3d7808868 | ||
|
|
bbc7573261 | ||
|
|
eed68f457d | ||
|
|
62dbf371ae | ||
|
|
f2c44e3540 | ||
|
|
a9b0d50baf | ||
|
|
fc156b50c0 | ||
|
|
835e662fb5 | ||
|
|
1b8d86a104 | ||
|
|
1251446383 | ||
|
|
d2bbd0cdb7 | ||
|
|
6c416b319c | ||
|
|
77fa5987b8 | ||
|
|
fadec970c9 | ||
|
|
1ea2b7272a | ||
|
|
7d7d00f288 | ||
|
|
b481cfbd01 | ||
|
|
46cf1970ac | ||
|
|
5491b46511 | ||
|
|
ae1387b523 | ||
|
|
b0dd0c8821 | ||
|
|
103da63393 | ||
|
|
e5c58a8a8b | ||
|
|
64faedfd57 | ||
|
|
9db70400d8 | ||
|
|
804117833e | ||
|
|
4046677cf1 | ||
|
|
addbe49de1 | ||
|
|
4d2c0600f6 | ||
|
|
5ecce83217 | ||
|
|
55aaec4d83 | ||
|
|
0c32f094af | ||
|
|
9a14f54e8b | ||
|
|
5eec5e289e | ||
|
|
e794d062e8 | ||
|
|
1872e0249c | ||
|
|
9e8d91ebf9 | ||
|
|
bcee361d04 | ||
|
|
2f668ecefe | ||
|
|
0c02ae907e | ||
|
|
fa44a05567 | ||
|
|
75432a0695 | ||
|
|
fef5bcd8f9 | ||
|
|
44d2a9b623 | ||
|
|
10eb3892da | ||
|
|
68a35543d5 | ||
|
|
4426a9d12c | ||
|
|
62ff77b49a | ||
|
|
61754b2fac | ||
|
|
5615f072d7 | ||
|
|
14f7fe4a65 | ||
|
|
b8790474f1 | ||
|
|
5284de6e97 | ||
|
|
f593bfd3c2 | ||
|
|
542e2e7c07 | ||
|
|
64289a491d | ||
|
|
35855bf860 | ||
|
|
07a5a68d50 | ||
|
|
da9974b416 | ||
|
|
e4039aa570 | ||
|
|
de72049fe5 | ||
|
|
279f4a154d | ||
|
|
2a0660baab | ||
|
|
c538725885 | ||
|
|
c639198c97 | ||
|
|
bbc12e70c4 | ||
|
|
639f05a190 | ||
|
|
8f4ddb5a1f | ||
|
|
af93f34834 | ||
|
|
7e43f29d52 | ||
|
|
ce60d4b00e | ||
|
|
31c448a95d | ||
|
|
9c09c0d316 | ||
|
|
354a1808ff | ||
|
|
8006842f2a | ||
|
|
b2ac2655b3 | ||
|
|
9f14e82b5a | ||
|
|
dd45123f20 | ||
|
|
88f5d79088 | ||
|
|
a343cf534c | ||
|
|
029a9da00b | ||
|
|
1b39cebe92 | ||
|
|
a8610e9da4 | ||
|
|
c75ca04cf7 | ||
|
|
bc8361fa47 | ||
|
|
9de627e01b | ||
|
|
780e231536 | ||
|
|
a0f79318c5 | ||
|
|
ef16253953 | ||
|
|
1cd1436460 | ||
|
|
c4fc4666fc | ||
|
|
44508ed0db | ||
|
|
626bf3fe23 | ||
|
|
1f9661e150 | ||
|
|
1db40ac566 | ||
|
|
633d66f1f0 | ||
|
|
13a0110b69 | ||
|
|
48faf8eb7e | ||
|
|
07da36d4c8 | ||
|
|
02650672f6 | ||
|
|
a15c33a3cc | ||
|
|
ac6c07fa43 | ||
|
|
f00ef66727 | ||
|
|
7204a4ca64 | ||
|
|
c710d8c101 | ||
|
|
d76c00721c | ||
|
|
f14c0236f0 | ||
|
|
36b451a49b | ||
|
|
070ec550d3 | ||
|
|
7fd7de4451 | ||
|
|
280fed3c76 | ||
|
|
f63e49d245 | ||
|
|
ab73f8c3fd | ||
|
|
fe39cc7b80 | ||
|
|
4efadaecfc | ||
|
|
ed6983ea84 | ||
|
|
0e85652f07 | ||
|
|
61e38de034 | ||
|
|
e12a08133f | ||
|
|
cd5af2521a | ||
|
|
c9dea62162 | ||
|
|
0ca839cc32 | ||
|
|
e3624b4e9d | ||
|
|
5241b7dd4e | ||
|
|
34163326b2 | ||
|
|
d17b121d9d | ||
|
|
6fa66f5534 | ||
|
|
b314beeda1 | ||
|
|
66b97a0c28 | ||
|
|
2bbca5f2a7 | ||
|
|
502f15aca7 | ||
|
|
17633808d8 | ||
|
|
e9f4e0d086 | ||
|
|
6c3fe952d1 | ||
|
|
097b0ef2c6 | ||
|
|
6053d0e46f | ||
|
|
b538f10796 | ||
|
|
04d318d88f | ||
|
|
eb04a488c5 | ||
|
|
8660db9806 | ||
|
|
1c45ec9770 | ||
|
|
42016bc067 | ||
|
|
4a9e294436 | ||
|
|
c18ee9d40a | ||
|
|
124bb5e391 | ||
|
|
c2e62a5087 | ||
|
|
dd8343922e | ||
|
|
1216b5765a | ||
|
|
24ee279005 | ||
|
|
7c0d307142 | ||
|
|
cc08c6b288 | ||
|
|
6c4151a820 | ||
|
|
8e1bcd5568 | ||
|
|
1b6182bac2 | ||
|
|
ff9c6612b4 | ||
|
|
4bb3fff52b | ||
|
|
9c161d1d04 | ||
|
|
13429640d3 | ||
|
|
0345f860d4 | ||
|
|
4bfe7158b1 | ||
|
|
5ac2f42184 | ||
|
|
e13e63a811 | ||
|
|
17468e2862 | ||
|
|
3c15a6c246 | ||
|
|
340662e98e | ||
|
|
838b73d3b6 | ||
|
|
39f49c22cd | ||
|
|
23279c5f1d | ||
|
|
db6fbfad90 | ||
|
|
e0753f0b0d | ||
|
|
3463f418b8 | ||
|
|
cd9786e787 | ||
|
|
3c0b31a2b8 | ||
|
|
51de308b80 | ||
|
|
2628fb56f2 | ||
|
|
dc28b615ae | ||
|
|
9751f1f185 | ||
|
|
5b74911881 | ||
|
|
0666848338 | ||
|
|
eb908487b8 | ||
|
|
bf633ab556 | ||
|
|
1e82341da7 | ||
|
|
7cbda3ec17 | ||
|
|
fba419b7f7 | ||
|
|
f4f3d403f3 | ||
|
|
e42b0c4f70 | ||
|
|
7f62eacdb2 | ||
|
|
00acda7ab0 | ||
|
|
d173a2f8da | ||
|
|
e58a730e6a | ||
|
|
2ee11c7845 | ||
|
|
8eba1684cb | ||
|
|
cf9bb7c48c | ||
|
|
ddebdfbcd7 | ||
|
|
d60c52df4a | ||
|
|
4711665edb | ||
|
|
154ace4ba4 | ||
|
|
b24d89a283 | ||
|
|
da7884cef1 | ||
|
|
95707fba1c | ||
|
|
3b9fbfc08c | ||
|
|
89532a876e | ||
|
|
b183dcb6e8 | ||
|
|
9fc661f8b3 | ||
|
|
01f86ddeb1 | ||
|
|
b466c381da | ||
|
|
e6a32bfc37 | ||
|
|
e6bc960fb5 | ||
|
|
1f9cf91e1b | ||
|
|
1af1a36bd6 | ||
|
|
aa9bcaf04c | ||
|
|
03ee1dbf82 | ||
|
|
1e4a2e8624 | ||
|
|
ac3f8dc833 | ||
|
|
b4dea43963 | ||
|
|
0ba55a83ad | ||
|
|
fc58acb2d4 | ||
|
|
25c065e9da | ||
|
|
b95621573b | ||
|
|
513a6476bc | ||
|
|
0a309ec6c7 | ||
|
|
caa3371376 | ||
|
|
ebac66daeb | ||
|
|
9c6b58c5ad | ||
|
|
01759d8ffb | ||
|
|
3d769a66cb | ||
|
|
569e5229a9 | ||
|
|
19340462e4 | ||
|
|
831e64efb0 | ||
|
|
f248bfc415 | ||
|
|
16a0be790b | ||
|
|
1b82388ab8 | ||
|
|
d6412c94dc | ||
|
|
d07307a451 | ||
|
|
0216e4689a | ||
|
|
a0cd2506f6 | ||
|
|
112959e087 | ||
|
|
fc7a4cacc3 | ||
|
|
6c2fc685de | ||
|
|
5fb63b4520 | ||
|
|
ddb0b1b652 | ||
|
|
faed5405c8 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
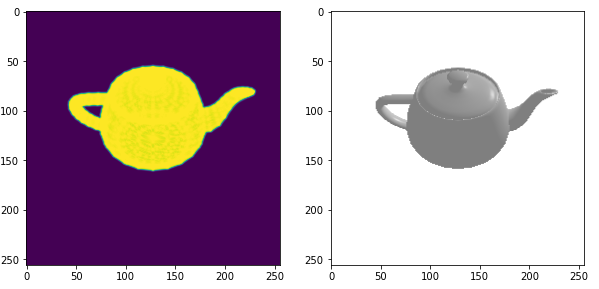{kind=link}
@@ -1,5 +1,9 @@
|
|||||||
#!/usr/bin/env python3
|
#!/usr/bin/env python3
|
||||||
# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
"""
|
"""
|
||||||
Print the number of nightly builds
|
Print the number of nightly builds
|
||||||
|
|||||||
@@ -1,6 +1,13 @@
|
|||||||
#!/bin/bash -e
|
#!/bin/bash -e
|
||||||
# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
# Run this script before committing config.yml to verify it is valid yaml.
|
# Run this script before committing config.yml to verify it is valid yaml.
|
||||||
|
|
||||||
python -c 'import yaml; yaml.safe_load(open("config.yml"))' && echo OK
|
python -c 'import yaml; yaml.safe_load(open("config.yml"))' && echo OK - valid yaml
|
||||||
|
|
||||||
|
msg="circleci not installed so can't check schema"
|
||||||
|
command -v circleci > /dev/null && (cd ..; circleci config validate) || echo "$msg"
|
||||||
|
|||||||
@@ -18,19 +18,12 @@ setupcuda: &setupcuda
|
|||||||
working_directory: ~/
|
working_directory: ~/
|
||||||
command: |
|
command: |
|
||||||
# download and install nvidia drivers, cuda, etc
|
# download and install nvidia drivers, cuda, etc
|
||||||
wget --no-verbose --no-clobber -P ~/nvidia-downloads http://developer.download.nvidia.com/compute/cuda/10.2/Prod/local_installers/cuda_10.2.89_440.33.01_linux.run
|
wget --no-verbose --no-clobber -P ~/nvidia-downloads https://developer.download.nvidia.com/compute/cuda/11.3.1/local_installers/cuda_11.3.1_465.19.01_linux.run
|
||||||
sudo sh ~/nvidia-downloads/cuda_10.2.89_440.33.01_linux.run --silent
|
sudo sh ~/nvidia-downloads/cuda_11.3.1_465.19.01_linux.run --silent
|
||||||
echo "Done installing CUDA."
|
echo "Done installing CUDA."
|
||||||
pyenv versions
|
pyenv versions
|
||||||
nvidia-smi
|
nvidia-smi
|
||||||
pyenv global 3.7.0
|
pyenv global 3.9.1
|
||||||
|
|
||||||
gpu: &gpu
|
|
||||||
environment:
|
|
||||||
CUDA_VERSION: "10.2"
|
|
||||||
machine:
|
|
||||||
image: default
|
|
||||||
resource_class: gpu.medium # tesla m60
|
|
||||||
|
|
||||||
binary_common: &binary_common
|
binary_common: &binary_common
|
||||||
parameters:
|
parameters:
|
||||||
@@ -54,41 +47,41 @@ binary_common: &binary_common
|
|||||||
description: "Wheel only: what docker image to use"
|
description: "Wheel only: what docker image to use"
|
||||||
type: string
|
type: string
|
||||||
default: "pytorch/manylinux-cuda101"
|
default: "pytorch/manylinux-cuda101"
|
||||||
|
conda_docker_image:
|
||||||
|
description: "what docker image to use for docker"
|
||||||
|
type: string
|
||||||
|
default: "pytorch/conda-cuda"
|
||||||
environment:
|
environment:
|
||||||
PYTHON_VERSION: << parameters.python_version >>
|
PYTHON_VERSION: << parameters.python_version >>
|
||||||
BUILD_VERSION: << parameters.build_version >>
|
BUILD_VERSION: << parameters.build_version >>
|
||||||
PYTORCH_VERSION: << parameters.pytorch_version >>
|
PYTORCH_VERSION: << parameters.pytorch_version >>
|
||||||
CU_VERSION: << parameters.cu_version >>
|
CU_VERSION: << parameters.cu_version >>
|
||||||
|
TESTRUN_DOCKER_IMAGE: << parameters.conda_docker_image >>
|
||||||
|
|
||||||
jobs:
|
jobs:
|
||||||
main:
|
main:
|
||||||
<<: *gpu
|
environment:
|
||||||
|
CUDA_VERSION: "11.3"
|
||||||
|
resource_class: gpu.nvidia.small.multi
|
||||||
machine:
|
machine:
|
||||||
image: ubuntu-1604:201903-01
|
image: ubuntu-2004:202101-01
|
||||||
steps:
|
steps:
|
||||||
- checkout
|
- checkout
|
||||||
- <<: *setupcuda
|
- <<: *setupcuda
|
||||||
- run: pip3 install --progress-bar off imageio wheel matplotlib 'pillow<7'
|
- run: pip3 install --progress-bar off imageio wheel matplotlib 'pillow<7'
|
||||||
- run: pip3 install --progress-bar off torch torchvision
|
- run: pip3 install --progress-bar off torch==1.10.0+cu113 torchvision==0.11.1+cu113 -f https://download.pytorch.org/whl/cu113/torch_stable.html
|
||||||
# - run: conda create -p ~/conda_env python=3.7 numpy
|
# - run: conda create -p ~/conda_env python=3.7 numpy
|
||||||
# - run: conda activate ~/conda_env
|
# - run: conda activate ~/conda_env
|
||||||
# - run: conda install -c pytorch pytorch torchvision
|
# - run: conda install -c pytorch pytorch torchvision
|
||||||
|
|
||||||
- run: pip3 install --progress-bar off 'git+https://github.com/facebookresearch/fvcore'
|
- run: pip3 install --progress-bar off 'git+https://github.com/facebookresearch/fvcore'
|
||||||
- run:
|
- run: pip3 install --progress-bar off 'git+https://github.com/facebookresearch/iopath'
|
||||||
name: get cub
|
|
||||||
command: |
|
|
||||||
cd ..
|
|
||||||
wget --no-verbose https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz
|
|
||||||
tar xzf 1.10.0.tar.gz
|
|
||||||
# This expands to a directory called cub-1.10.0
|
|
||||||
- run:
|
- run:
|
||||||
name: build
|
name: build
|
||||||
command: |
|
command: |
|
||||||
export LD_LIBRARY_PATH=$LD_LIBARY_PATH:/usr/local/cuda-10.2/lib64
|
export LD_LIBRARY_PATH=$LD_LIBARY_PATH:/usr/local/cuda-11.3/lib64
|
||||||
export CUB_HOME=$(realpath ../cub-1.10.0)
|
|
||||||
python3 setup.py build_ext --inplace
|
python3 setup.py build_ext --inplace
|
||||||
- run: LD_LIBRARY_PATH=$LD_LIBARY_PATH:/usr/local/cuda-10.2/lib64 python -m unittest discover -v -s tests
|
- run: LD_LIBRARY_PATH=$LD_LIBARY_PATH:/usr/local/cuda-11.3/lib64 python -m unittest discover -v -s tests -t .
|
||||||
- run: python3 setup.py bdist_wheel
|
- run: python3 setup.py bdist_wheel
|
||||||
|
|
||||||
binary_linux_wheel:
|
binary_linux_wheel:
|
||||||
@@ -112,7 +105,7 @@ jobs:
|
|||||||
binary_linux_conda:
|
binary_linux_conda:
|
||||||
<<: *binary_common
|
<<: *binary_common
|
||||||
docker:
|
docker:
|
||||||
- image: "pytorch/conda-cuda"
|
- image: "<< parameters.conda_docker_image >>"
|
||||||
auth:
|
auth:
|
||||||
username: $DOCKERHUB_USERNAME
|
username: $DOCKERHUB_USERNAME
|
||||||
password: $DOCKERHUB_TOKEN
|
password: $DOCKERHUB_TOKEN
|
||||||
@@ -121,7 +114,10 @@ jobs:
|
|||||||
- checkout
|
- checkout
|
||||||
# This is building with cuda but no gpu present,
|
# This is building with cuda but no gpu present,
|
||||||
# so we aren't running the tests.
|
# so we aren't running the tests.
|
||||||
- run: MAX_JOBS=15 TEST_FLAG=--no-test packaging/build_conda.sh
|
- run:
|
||||||
|
name: build
|
||||||
|
no_output_timeout: 20m
|
||||||
|
command: MAX_JOBS=15 TEST_FLAG=--no-test packaging/build_conda.sh
|
||||||
- store_artifacts:
|
- store_artifacts:
|
||||||
path: /opt/conda/conda-bld/linux-64
|
path: /opt/conda/conda-bld/linux-64
|
||||||
- persist_to_workspace:
|
- persist_to_workspace:
|
||||||
@@ -132,79 +128,38 @@ jobs:
|
|||||||
binary_linux_conda_cuda:
|
binary_linux_conda_cuda:
|
||||||
<<: *binary_common
|
<<: *binary_common
|
||||||
machine:
|
machine:
|
||||||
image: ubuntu-1604:201903-01
|
image: ubuntu-1604-cuda-10.2:202012-01
|
||||||
resource_class: gpu.medium
|
resource_class: gpu.nvidia.small.multi
|
||||||
steps:
|
steps:
|
||||||
- checkout
|
- checkout
|
||||||
- run:
|
|
||||||
name: Setup environment
|
|
||||||
command: |
|
|
||||||
set -e
|
|
||||||
|
|
||||||
curl -L https://packagecloud.io/circleci/trusty/gpgkey | sudo apt-key add -
|
|
||||||
curl -L https://dl.google.com/linux/linux_signing_key.pub | sudo apt-key add -
|
|
||||||
|
|
||||||
sudo apt-get update
|
|
||||||
|
|
||||||
sudo apt-get install \
|
|
||||||
apt-transport-https \
|
|
||||||
ca-certificates \
|
|
||||||
curl \
|
|
||||||
gnupg-agent \
|
|
||||||
software-properties-common
|
|
||||||
|
|
||||||
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
|
|
||||||
|
|
||||||
sudo add-apt-repository \
|
|
||||||
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
|
|
||||||
$(lsb_release -cs) \
|
|
||||||
stable"
|
|
||||||
|
|
||||||
sudo apt-get update
|
|
||||||
export DOCKER_VERSION="5:19.03.2~3-0~ubuntu-xenial"
|
|
||||||
sudo apt-get install docker-ce=${DOCKER_VERSION} docker-ce-cli=${DOCKER_VERSION} containerd.io=1.2.6-3
|
|
||||||
|
|
||||||
# Add the package repositories
|
|
||||||
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
|
|
||||||
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
|
|
||||||
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
|
|
||||||
|
|
||||||
export NVIDIA_CONTAINER_VERSION="1.0.3-1"
|
|
||||||
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit=${NVIDIA_CONTAINER_VERSION}
|
|
||||||
sudo systemctl restart docker
|
|
||||||
|
|
||||||
DRIVER_FN="NVIDIA-Linux-x86_64-450.80.02.run"
|
|
||||||
wget "https://us.download.nvidia.com/XFree86/Linux-x86_64/450.80.02/$DRIVER_FN"
|
|
||||||
sudo /bin/bash "$DRIVER_FN" -s --no-drm || (sudo cat /var/log/nvidia-installer.log && false)
|
|
||||||
nvidia-smi
|
|
||||||
|
|
||||||
- run:
|
- run:
|
||||||
name: Pull docker image
|
name: Pull docker image
|
||||||
command: |
|
command: |
|
||||||
|
nvidia-smi
|
||||||
set -e
|
set -e
|
||||||
|
|
||||||
{ docker login -u="$DOCKERHUB_USERNAME" -p="$DOCKERHUB_TOKEN" ; } 2> /dev/null
|
{ docker login -u="$DOCKERHUB_USERNAME" -p="$DOCKERHUB_TOKEN" ; } 2> /dev/null
|
||||||
|
|
||||||
export DOCKER_IMAGE=pytorch/conda-cuda
|
echo Pulling docker image $TESTRUN_DOCKER_IMAGE
|
||||||
echo Pulling docker image $DOCKER_IMAGE
|
docker pull $TESTRUN_DOCKER_IMAGE
|
||||||
docker pull $DOCKER_IMAGE >/dev/null
|
|
||||||
|
|
||||||
- run:
|
- run:
|
||||||
name: Build and run tests
|
name: Build and run tests
|
||||||
|
no_output_timeout: 20m
|
||||||
command: |
|
command: |
|
||||||
set -e
|
set -e
|
||||||
|
|
||||||
cd ${HOME}/project/
|
cd ${HOME}/project/
|
||||||
|
|
||||||
export DOCKER_IMAGE=pytorch/conda-cuda
|
export JUST_TESTRUN=1
|
||||||
export VARS_TO_PASS="-e PYTHON_VERSION -e BUILD_VERSION -e PYTORCH_VERSION -e CU_VERSION"
|
VARS_TO_PASS="-e PYTHON_VERSION -e BUILD_VERSION -e PYTORCH_VERSION -e CU_VERSION -e JUST_TESTRUN"
|
||||||
|
|
||||||
docker run --gpus all --ipc=host -v $(pwd):/remote -w /remote ${VARS_TO_PASS} ${DOCKER_IMAGE} ./packaging/build_conda.sh
|
docker run --gpus all --ipc=host -v $(pwd):/remote -w /remote ${VARS_TO_PASS} ${TESTRUN_DOCKER_IMAGE} ./packaging/build_conda.sh
|
||||||
|
|
||||||
binary_macos_wheel:
|
binary_macos_wheel:
|
||||||
<<: *binary_common
|
<<: *binary_common
|
||||||
macos:
|
macos:
|
||||||
xcode: "9.4.1"
|
xcode: "12.0"
|
||||||
steps:
|
steps:
|
||||||
- checkout
|
- checkout
|
||||||
- run:
|
- run:
|
||||||
@@ -223,39 +178,27 @@ workflows:
|
|||||||
version: 2
|
version: 2
|
||||||
build_and_test:
|
build_and_test:
|
||||||
jobs:
|
jobs:
|
||||||
- main:
|
# - main:
|
||||||
context: DOCKERHUB_TOKEN
|
# context: DOCKERHUB_TOKEN
|
||||||
{{workflows()}}
|
{{workflows()}}
|
||||||
- binary_linux_conda_cuda:
|
- binary_linux_conda_cuda:
|
||||||
name: testrun_conda_cuda_py36_cu101_pyt14
|
name: testrun_conda_cuda_py37_cu102_pyt190
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
python_version: "3.6"
|
|
||||||
pytorch_version: "1.4"
|
|
||||||
cu_version: "cu101"
|
|
||||||
- binary_linux_conda_cuda:
|
|
||||||
name: testrun_conda_cuda_py37_cu102_pyt160
|
|
||||||
context: DOCKERHUB_TOKEN
|
context: DOCKERHUB_TOKEN
|
||||||
python_version: "3.7"
|
python_version: "3.7"
|
||||||
pytorch_version: '1.6.0'
|
pytorch_version: '1.9.0'
|
||||||
cu_version: "cu102"
|
cu_version: "cu102"
|
||||||
- binary_linux_conda_cuda:
|
|
||||||
name: testrun_conda_cuda_py37_cu110_pyt170
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
python_version: "3.7"
|
|
||||||
pytorch_version: '1.7.0'
|
|
||||||
cu_version: "cu110"
|
|
||||||
- binary_macos_wheel:
|
|
||||||
cu_version: cpu
|
|
||||||
name: macos_wheel_py36_cpu
|
|
||||||
python_version: '3.6'
|
|
||||||
pytorch_version: '1.6.0'
|
|
||||||
- binary_macos_wheel:
|
- binary_macos_wheel:
|
||||||
cu_version: cpu
|
cu_version: cpu
|
||||||
name: macos_wheel_py37_cpu
|
name: macos_wheel_py37_cpu
|
||||||
python_version: '3.7'
|
python_version: '3.7'
|
||||||
pytorch_version: '1.6.0'
|
pytorch_version: '1.12.0'
|
||||||
- binary_macos_wheel:
|
- binary_macos_wheel:
|
||||||
cu_version: cpu
|
cu_version: cpu
|
||||||
name: macos_wheel_py38_cpu
|
name: macos_wheel_py38_cpu
|
||||||
python_version: '3.8'
|
python_version: '3.8'
|
||||||
pytorch_version: '1.6.0'
|
pytorch_version: '1.12.0'
|
||||||
|
- binary_macos_wheel:
|
||||||
|
cu_version: cpu
|
||||||
|
name: macos_wheel_py39_cpu
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: '1.12.0'
|
||||||
|
|||||||
@@ -18,19 +18,12 @@ setupcuda: &setupcuda
|
|||||||
working_directory: ~/
|
working_directory: ~/
|
||||||
command: |
|
command: |
|
||||||
# download and install nvidia drivers, cuda, etc
|
# download and install nvidia drivers, cuda, etc
|
||||||
wget --no-verbose --no-clobber -P ~/nvidia-downloads http://developer.download.nvidia.com/compute/cuda/10.2/Prod/local_installers/cuda_10.2.89_440.33.01_linux.run
|
wget --no-verbose --no-clobber -P ~/nvidia-downloads https://developer.download.nvidia.com/compute/cuda/11.3.1/local_installers/cuda_11.3.1_465.19.01_linux.run
|
||||||
sudo sh ~/nvidia-downloads/cuda_10.2.89_440.33.01_linux.run --silent
|
sudo sh ~/nvidia-downloads/cuda_11.3.1_465.19.01_linux.run --silent
|
||||||
echo "Done installing CUDA."
|
echo "Done installing CUDA."
|
||||||
pyenv versions
|
pyenv versions
|
||||||
nvidia-smi
|
nvidia-smi
|
||||||
pyenv global 3.7.0
|
pyenv global 3.9.1
|
||||||
|
|
||||||
gpu: &gpu
|
|
||||||
environment:
|
|
||||||
CUDA_VERSION: "10.2"
|
|
||||||
machine:
|
|
||||||
image: default
|
|
||||||
resource_class: gpu.medium # tesla m60
|
|
||||||
|
|
||||||
binary_common: &binary_common
|
binary_common: &binary_common
|
||||||
parameters:
|
parameters:
|
||||||
@@ -54,41 +47,41 @@ binary_common: &binary_common
|
|||||||
description: "Wheel only: what docker image to use"
|
description: "Wheel only: what docker image to use"
|
||||||
type: string
|
type: string
|
||||||
default: "pytorch/manylinux-cuda101"
|
default: "pytorch/manylinux-cuda101"
|
||||||
|
conda_docker_image:
|
||||||
|
description: "what docker image to use for docker"
|
||||||
|
type: string
|
||||||
|
default: "pytorch/conda-cuda"
|
||||||
environment:
|
environment:
|
||||||
PYTHON_VERSION: << parameters.python_version >>
|
PYTHON_VERSION: << parameters.python_version >>
|
||||||
BUILD_VERSION: << parameters.build_version >>
|
BUILD_VERSION: << parameters.build_version >>
|
||||||
PYTORCH_VERSION: << parameters.pytorch_version >>
|
PYTORCH_VERSION: << parameters.pytorch_version >>
|
||||||
CU_VERSION: << parameters.cu_version >>
|
CU_VERSION: << parameters.cu_version >>
|
||||||
|
TESTRUN_DOCKER_IMAGE: << parameters.conda_docker_image >>
|
||||||
|
|
||||||
jobs:
|
jobs:
|
||||||
main:
|
main:
|
||||||
<<: *gpu
|
environment:
|
||||||
|
CUDA_VERSION: "11.3"
|
||||||
|
resource_class: gpu.nvidia.small.multi
|
||||||
machine:
|
machine:
|
||||||
image: ubuntu-1604:201903-01
|
image: ubuntu-2004:202101-01
|
||||||
steps:
|
steps:
|
||||||
- checkout
|
- checkout
|
||||||
- <<: *setupcuda
|
- <<: *setupcuda
|
||||||
- run: pip3 install --progress-bar off imageio wheel matplotlib 'pillow<7'
|
- run: pip3 install --progress-bar off imageio wheel matplotlib 'pillow<7'
|
||||||
- run: pip3 install --progress-bar off torch torchvision
|
- run: pip3 install --progress-bar off torch==1.10.0+cu113 torchvision==0.11.1+cu113 -f https://download.pytorch.org/whl/cu113/torch_stable.html
|
||||||
# - run: conda create -p ~/conda_env python=3.7 numpy
|
# - run: conda create -p ~/conda_env python=3.7 numpy
|
||||||
# - run: conda activate ~/conda_env
|
# - run: conda activate ~/conda_env
|
||||||
# - run: conda install -c pytorch pytorch torchvision
|
# - run: conda install -c pytorch pytorch torchvision
|
||||||
|
|
||||||
- run: pip3 install --progress-bar off 'git+https://github.com/facebookresearch/fvcore'
|
- run: pip3 install --progress-bar off 'git+https://github.com/facebookresearch/fvcore'
|
||||||
- run:
|
- run: pip3 install --progress-bar off 'git+https://github.com/facebookresearch/iopath'
|
||||||
name: get cub
|
|
||||||
command: |
|
|
||||||
cd ..
|
|
||||||
wget --no-verbose https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz
|
|
||||||
tar xzf 1.10.0.tar.gz
|
|
||||||
# This expands to a directory called cub-1.10.0
|
|
||||||
- run:
|
- run:
|
||||||
name: build
|
name: build
|
||||||
command: |
|
command: |
|
||||||
export LD_LIBRARY_PATH=$LD_LIBARY_PATH:/usr/local/cuda-10.2/lib64
|
export LD_LIBRARY_PATH=$LD_LIBARY_PATH:/usr/local/cuda-11.3/lib64
|
||||||
export CUB_HOME=$(realpath ../cub-1.10.0)
|
|
||||||
python3 setup.py build_ext --inplace
|
python3 setup.py build_ext --inplace
|
||||||
- run: LD_LIBRARY_PATH=$LD_LIBARY_PATH:/usr/local/cuda-10.2/lib64 python -m unittest discover -v -s tests
|
- run: LD_LIBRARY_PATH=$LD_LIBARY_PATH:/usr/local/cuda-11.3/lib64 python -m unittest discover -v -s tests -t .
|
||||||
- run: python3 setup.py bdist_wheel
|
- run: python3 setup.py bdist_wheel
|
||||||
|
|
||||||
binary_linux_wheel:
|
binary_linux_wheel:
|
||||||
@@ -112,7 +105,7 @@ jobs:
|
|||||||
binary_linux_conda:
|
binary_linux_conda:
|
||||||
<<: *binary_common
|
<<: *binary_common
|
||||||
docker:
|
docker:
|
||||||
- image: "pytorch/conda-cuda"
|
- image: "<< parameters.conda_docker_image >>"
|
||||||
auth:
|
auth:
|
||||||
username: $DOCKERHUB_USERNAME
|
username: $DOCKERHUB_USERNAME
|
||||||
password: $DOCKERHUB_TOKEN
|
password: $DOCKERHUB_TOKEN
|
||||||
@@ -121,7 +114,10 @@ jobs:
|
|||||||
- checkout
|
- checkout
|
||||||
# This is building with cuda but no gpu present,
|
# This is building with cuda but no gpu present,
|
||||||
# so we aren't running the tests.
|
# so we aren't running the tests.
|
||||||
- run: MAX_JOBS=15 TEST_FLAG=--no-test packaging/build_conda.sh
|
- run:
|
||||||
|
name: build
|
||||||
|
no_output_timeout: 20m
|
||||||
|
command: MAX_JOBS=15 TEST_FLAG=--no-test packaging/build_conda.sh
|
||||||
- store_artifacts:
|
- store_artifacts:
|
||||||
path: /opt/conda/conda-bld/linux-64
|
path: /opt/conda/conda-bld/linux-64
|
||||||
- persist_to_workspace:
|
- persist_to_workspace:
|
||||||
@@ -132,79 +128,38 @@ jobs:
|
|||||||
binary_linux_conda_cuda:
|
binary_linux_conda_cuda:
|
||||||
<<: *binary_common
|
<<: *binary_common
|
||||||
machine:
|
machine:
|
||||||
image: ubuntu-1604:201903-01
|
image: ubuntu-1604-cuda-10.2:202012-01
|
||||||
resource_class: gpu.medium
|
resource_class: gpu.nvidia.small.multi
|
||||||
steps:
|
steps:
|
||||||
- checkout
|
- checkout
|
||||||
- run:
|
|
||||||
name: Setup environment
|
|
||||||
command: |
|
|
||||||
set -e
|
|
||||||
|
|
||||||
curl -L https://packagecloud.io/circleci/trusty/gpgkey | sudo apt-key add -
|
|
||||||
curl -L https://dl.google.com/linux/linux_signing_key.pub | sudo apt-key add -
|
|
||||||
|
|
||||||
sudo apt-get update
|
|
||||||
|
|
||||||
sudo apt-get install \
|
|
||||||
apt-transport-https \
|
|
||||||
ca-certificates \
|
|
||||||
curl \
|
|
||||||
gnupg-agent \
|
|
||||||
software-properties-common
|
|
||||||
|
|
||||||
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
|
|
||||||
|
|
||||||
sudo add-apt-repository \
|
|
||||||
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
|
|
||||||
$(lsb_release -cs) \
|
|
||||||
stable"
|
|
||||||
|
|
||||||
sudo apt-get update
|
|
||||||
export DOCKER_VERSION="5:19.03.2~3-0~ubuntu-xenial"
|
|
||||||
sudo apt-get install docker-ce=${DOCKER_VERSION} docker-ce-cli=${DOCKER_VERSION} containerd.io=1.2.6-3
|
|
||||||
|
|
||||||
# Add the package repositories
|
|
||||||
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
|
|
||||||
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
|
|
||||||
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
|
|
||||||
|
|
||||||
export NVIDIA_CONTAINER_VERSION="1.0.3-1"
|
|
||||||
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit=${NVIDIA_CONTAINER_VERSION}
|
|
||||||
sudo systemctl restart docker
|
|
||||||
|
|
||||||
DRIVER_FN="NVIDIA-Linux-x86_64-450.80.02.run"
|
|
||||||
wget "https://us.download.nvidia.com/XFree86/Linux-x86_64/450.80.02/$DRIVER_FN"
|
|
||||||
sudo /bin/bash "$DRIVER_FN" -s --no-drm || (sudo cat /var/log/nvidia-installer.log && false)
|
|
||||||
nvidia-smi
|
|
||||||
|
|
||||||
- run:
|
- run:
|
||||||
name: Pull docker image
|
name: Pull docker image
|
||||||
command: |
|
command: |
|
||||||
|
nvidia-smi
|
||||||
set -e
|
set -e
|
||||||
|
|
||||||
{ docker login -u="$DOCKERHUB_USERNAME" -p="$DOCKERHUB_TOKEN" ; } 2> /dev/null
|
{ docker login -u="$DOCKERHUB_USERNAME" -p="$DOCKERHUB_TOKEN" ; } 2> /dev/null
|
||||||
|
|
||||||
export DOCKER_IMAGE=pytorch/conda-cuda
|
echo Pulling docker image $TESTRUN_DOCKER_IMAGE
|
||||||
echo Pulling docker image $DOCKER_IMAGE
|
docker pull $TESTRUN_DOCKER_IMAGE
|
||||||
docker pull $DOCKER_IMAGE >/dev/null
|
|
||||||
|
|
||||||
- run:
|
- run:
|
||||||
name: Build and run tests
|
name: Build and run tests
|
||||||
|
no_output_timeout: 20m
|
||||||
command: |
|
command: |
|
||||||
set -e
|
set -e
|
||||||
|
|
||||||
cd ${HOME}/project/
|
cd ${HOME}/project/
|
||||||
|
|
||||||
export DOCKER_IMAGE=pytorch/conda-cuda
|
export JUST_TESTRUN=1
|
||||||
export VARS_TO_PASS="-e PYTHON_VERSION -e BUILD_VERSION -e PYTORCH_VERSION -e CU_VERSION"
|
VARS_TO_PASS="-e PYTHON_VERSION -e BUILD_VERSION -e PYTORCH_VERSION -e CU_VERSION -e JUST_TESTRUN"
|
||||||
|
|
||||||
docker run --gpus all --ipc=host -v $(pwd):/remote -w /remote ${VARS_TO_PASS} ${DOCKER_IMAGE} ./packaging/build_conda.sh
|
docker run --gpus all --ipc=host -v $(pwd):/remote -w /remote ${VARS_TO_PASS} ${TESTRUN_DOCKER_IMAGE} ./packaging/build_conda.sh
|
||||||
|
|
||||||
binary_macos_wheel:
|
binary_macos_wheel:
|
||||||
<<: *binary_common
|
<<: *binary_common
|
||||||
macos:
|
macos:
|
||||||
xcode: "9.4.1"
|
xcode: "12.0"
|
||||||
steps:
|
steps:
|
||||||
- checkout
|
- checkout
|
||||||
- run:
|
- run:
|
||||||
@@ -223,308 +178,561 @@ workflows:
|
|||||||
version: 2
|
version: 2
|
||||||
build_and_test:
|
build_and_test:
|
||||||
jobs:
|
jobs:
|
||||||
- main:
|
# - main:
|
||||||
context: DOCKERHUB_TOKEN
|
# context: DOCKERHUB_TOKEN
|
||||||
- binary_linux_conda:
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
cu_version: cu92
|
|
||||||
name: linux_conda_py36_cu92_pyt14
|
|
||||||
python_version: '3.6'
|
|
||||||
pytorch_version: '1.4'
|
|
||||||
- binary_linux_conda:
|
- binary_linux_conda:
|
||||||
context: DOCKERHUB_TOKEN
|
context: DOCKERHUB_TOKEN
|
||||||
cu_version: cu101
|
cu_version: cu101
|
||||||
name: linux_conda_py36_cu101_pyt14
|
name: linux_conda_py37_cu101_pyt180
|
||||||
python_version: '3.6'
|
python_version: '3.7'
|
||||||
pytorch_version: '1.4'
|
pytorch_version: 1.8.0
|
||||||
- binary_linux_conda:
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
cu_version: cu92
|
|
||||||
name: linux_conda_py36_cu92_pyt150
|
|
||||||
python_version: '3.6'
|
|
||||||
pytorch_version: 1.5.0
|
|
||||||
- binary_linux_conda:
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
cu_version: cu101
|
|
||||||
name: linux_conda_py36_cu101_pyt150
|
|
||||||
python_version: '3.6'
|
|
||||||
pytorch_version: 1.5.0
|
|
||||||
- binary_linux_conda:
|
- binary_linux_conda:
|
||||||
context: DOCKERHUB_TOKEN
|
context: DOCKERHUB_TOKEN
|
||||||
cu_version: cu102
|
cu_version: cu102
|
||||||
name: linux_conda_py36_cu102_pyt150
|
name: linux_conda_py37_cu102_pyt180
|
||||||
python_version: '3.6'
|
python_version: '3.7'
|
||||||
pytorch_version: 1.5.0
|
pytorch_version: 1.8.0
|
||||||
- binary_linux_conda:
|
- binary_linux_conda:
|
||||||
context: DOCKERHUB_TOKEN
|
context: DOCKERHUB_TOKEN
|
||||||
cu_version: cu92
|
cu_version: cu111
|
||||||
name: linux_conda_py36_cu92_pyt151
|
name: linux_conda_py37_cu111_pyt180
|
||||||
python_version: '3.6'
|
python_version: '3.7'
|
||||||
pytorch_version: 1.5.1
|
pytorch_version: 1.8.0
|
||||||
- binary_linux_conda:
|
- binary_linux_conda:
|
||||||
context: DOCKERHUB_TOKEN
|
context: DOCKERHUB_TOKEN
|
||||||
cu_version: cu101
|
cu_version: cu101
|
||||||
name: linux_conda_py36_cu101_pyt151
|
name: linux_conda_py37_cu101_pyt181
|
||||||
python_version: '3.6'
|
python_version: '3.7'
|
||||||
pytorch_version: 1.5.1
|
pytorch_version: 1.8.1
|
||||||
- binary_linux_conda:
|
- binary_linux_conda:
|
||||||
context: DOCKERHUB_TOKEN
|
context: DOCKERHUB_TOKEN
|
||||||
cu_version: cu102
|
cu_version: cu102
|
||||||
name: linux_conda_py36_cu102_pyt151
|
name: linux_conda_py37_cu102_pyt181
|
||||||
python_version: '3.6'
|
python_version: '3.7'
|
||||||
pytorch_version: 1.5.1
|
pytorch_version: 1.8.1
|
||||||
- binary_linux_conda:
|
- binary_linux_conda:
|
||||||
context: DOCKERHUB_TOKEN
|
context: DOCKERHUB_TOKEN
|
||||||
cu_version: cu92
|
cu_version: cu111
|
||||||
name: linux_conda_py36_cu92_pyt160
|
name: linux_conda_py37_cu111_pyt181
|
||||||
python_version: '3.6'
|
python_version: '3.7'
|
||||||
pytorch_version: 1.6.0
|
pytorch_version: 1.8.1
|
||||||
- binary_linux_conda:
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
cu_version: cu101
|
|
||||||
name: linux_conda_py36_cu101_pyt160
|
|
||||||
python_version: '3.6'
|
|
||||||
pytorch_version: 1.6.0
|
|
||||||
- binary_linux_conda:
|
- binary_linux_conda:
|
||||||
context: DOCKERHUB_TOKEN
|
context: DOCKERHUB_TOKEN
|
||||||
cu_version: cu102
|
cu_version: cu102
|
||||||
name: linux_conda_py36_cu102_pyt160
|
name: linux_conda_py37_cu102_pyt190
|
||||||
python_version: '3.6'
|
python_version: '3.7'
|
||||||
pytorch_version: 1.6.0
|
pytorch_version: 1.9.0
|
||||||
- binary_linux_conda:
|
- binary_linux_conda:
|
||||||
context: DOCKERHUB_TOKEN
|
context: DOCKERHUB_TOKEN
|
||||||
cu_version: cu101
|
cu_version: cu111
|
||||||
name: linux_conda_py36_cu101_pyt170
|
name: linux_conda_py37_cu111_pyt190
|
||||||
python_version: '3.6'
|
python_version: '3.7'
|
||||||
pytorch_version: 1.7.0
|
pytorch_version: 1.9.0
|
||||||
- binary_linux_conda:
|
- binary_linux_conda:
|
||||||
context: DOCKERHUB_TOKEN
|
context: DOCKERHUB_TOKEN
|
||||||
cu_version: cu102
|
cu_version: cu102
|
||||||
name: linux_conda_py36_cu102_pyt170
|
name: linux_conda_py37_cu102_pyt191
|
||||||
python_version: '3.6'
|
|
||||||
pytorch_version: 1.7.0
|
|
||||||
- binary_linux_conda:
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
cu_version: cu110
|
|
||||||
name: linux_conda_py36_cu110_pyt170
|
|
||||||
python_version: '3.6'
|
|
||||||
pytorch_version: 1.7.0
|
|
||||||
- binary_linux_conda:
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
cu_version: cu92
|
|
||||||
name: linux_conda_py37_cu92_pyt14
|
|
||||||
python_version: '3.7'
|
python_version: '3.7'
|
||||||
pytorch_version: '1.4'
|
pytorch_version: 1.9.1
|
||||||
- binary_linux_conda:
|
- binary_linux_conda:
|
||||||
context: DOCKERHUB_TOKEN
|
context: DOCKERHUB_TOKEN
|
||||||
cu_version: cu101
|
cu_version: cu111
|
||||||
name: linux_conda_py37_cu101_pyt14
|
name: linux_conda_py37_cu111_pyt191
|
||||||
python_version: '3.7'
|
python_version: '3.7'
|
||||||
pytorch_version: '1.4'
|
pytorch_version: 1.9.1
|
||||||
- binary_linux_conda:
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
cu_version: cu92
|
|
||||||
name: linux_conda_py37_cu92_pyt150
|
|
||||||
python_version: '3.7'
|
|
||||||
pytorch_version: 1.5.0
|
|
||||||
- binary_linux_conda:
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
cu_version: cu101
|
|
||||||
name: linux_conda_py37_cu101_pyt150
|
|
||||||
python_version: '3.7'
|
|
||||||
pytorch_version: 1.5.0
|
|
||||||
- binary_linux_conda:
|
- binary_linux_conda:
|
||||||
context: DOCKERHUB_TOKEN
|
context: DOCKERHUB_TOKEN
|
||||||
cu_version: cu102
|
cu_version: cu102
|
||||||
name: linux_conda_py37_cu102_pyt150
|
name: linux_conda_py37_cu102_pyt1100
|
||||||
python_version: '3.7'
|
python_version: '3.7'
|
||||||
pytorch_version: 1.5.0
|
pytorch_version: 1.10.0
|
||||||
- binary_linux_conda:
|
- binary_linux_conda:
|
||||||
context: DOCKERHUB_TOKEN
|
context: DOCKERHUB_TOKEN
|
||||||
cu_version: cu92
|
cu_version: cu111
|
||||||
name: linux_conda_py37_cu92_pyt151
|
name: linux_conda_py37_cu111_pyt1100
|
||||||
python_version: '3.7'
|
python_version: '3.7'
|
||||||
pytorch_version: 1.5.1
|
pytorch_version: 1.10.0
|
||||||
- binary_linux_conda:
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda113
|
||||||
context: DOCKERHUB_TOKEN
|
context: DOCKERHUB_TOKEN
|
||||||
cu_version: cu101
|
cu_version: cu113
|
||||||
name: linux_conda_py37_cu101_pyt151
|
name: linux_conda_py37_cu113_pyt1100
|
||||||
python_version: '3.7'
|
python_version: '3.7'
|
||||||
pytorch_version: 1.5.1
|
pytorch_version: 1.10.0
|
||||||
- binary_linux_conda:
|
- binary_linux_conda:
|
||||||
context: DOCKERHUB_TOKEN
|
context: DOCKERHUB_TOKEN
|
||||||
cu_version: cu102
|
cu_version: cu102
|
||||||
name: linux_conda_py37_cu102_pyt151
|
name: linux_conda_py37_cu102_pyt1101
|
||||||
python_version: '3.7'
|
python_version: '3.7'
|
||||||
pytorch_version: 1.5.1
|
pytorch_version: 1.10.1
|
||||||
- binary_linux_conda:
|
- binary_linux_conda:
|
||||||
context: DOCKERHUB_TOKEN
|
context: DOCKERHUB_TOKEN
|
||||||
cu_version: cu92
|
cu_version: cu111
|
||||||
name: linux_conda_py37_cu92_pyt160
|
name: linux_conda_py37_cu111_pyt1101
|
||||||
python_version: '3.7'
|
python_version: '3.7'
|
||||||
pytorch_version: 1.6.0
|
pytorch_version: 1.10.1
|
||||||
- binary_linux_conda:
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda113
|
||||||
context: DOCKERHUB_TOKEN
|
context: DOCKERHUB_TOKEN
|
||||||
cu_version: cu101
|
cu_version: cu113
|
||||||
name: linux_conda_py37_cu101_pyt160
|
name: linux_conda_py37_cu113_pyt1101
|
||||||
python_version: '3.7'
|
python_version: '3.7'
|
||||||
pytorch_version: 1.6.0
|
pytorch_version: 1.10.1
|
||||||
- binary_linux_conda:
|
- binary_linux_conda:
|
||||||
context: DOCKERHUB_TOKEN
|
context: DOCKERHUB_TOKEN
|
||||||
cu_version: cu102
|
cu_version: cu102
|
||||||
name: linux_conda_py37_cu102_pyt160
|
name: linux_conda_py37_cu102_pyt1102
|
||||||
python_version: '3.7'
|
python_version: '3.7'
|
||||||
pytorch_version: 1.6.0
|
pytorch_version: 1.10.2
|
||||||
- binary_linux_conda:
|
- binary_linux_conda:
|
||||||
context: DOCKERHUB_TOKEN
|
context: DOCKERHUB_TOKEN
|
||||||
cu_version: cu101
|
cu_version: cu111
|
||||||
name: linux_conda_py37_cu101_pyt170
|
name: linux_conda_py37_cu111_pyt1102
|
||||||
python_version: '3.7'
|
python_version: '3.7'
|
||||||
pytorch_version: 1.7.0
|
pytorch_version: 1.10.2
|
||||||
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda113
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu113
|
||||||
|
name: linux_conda_py37_cu113_pyt1102
|
||||||
|
python_version: '3.7'
|
||||||
|
pytorch_version: 1.10.2
|
||||||
- binary_linux_conda:
|
- binary_linux_conda:
|
||||||
context: DOCKERHUB_TOKEN
|
context: DOCKERHUB_TOKEN
|
||||||
cu_version: cu102
|
cu_version: cu102
|
||||||
name: linux_conda_py37_cu102_pyt170
|
name: linux_conda_py37_cu102_pyt1110
|
||||||
python_version: '3.7'
|
python_version: '3.7'
|
||||||
pytorch_version: 1.7.0
|
pytorch_version: 1.11.0
|
||||||
- binary_linux_conda:
|
- binary_linux_conda:
|
||||||
context: DOCKERHUB_TOKEN
|
context: DOCKERHUB_TOKEN
|
||||||
cu_version: cu110
|
cu_version: cu111
|
||||||
name: linux_conda_py37_cu110_pyt170
|
name: linux_conda_py37_cu111_pyt1110
|
||||||
python_version: '3.7'
|
python_version: '3.7'
|
||||||
pytorch_version: 1.7.0
|
pytorch_version: 1.11.0
|
||||||
- binary_linux_conda:
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda113
|
||||||
context: DOCKERHUB_TOKEN
|
context: DOCKERHUB_TOKEN
|
||||||
cu_version: cu92
|
cu_version: cu113
|
||||||
name: linux_conda_py38_cu92_pyt14
|
name: linux_conda_py37_cu113_pyt1110
|
||||||
python_version: '3.8'
|
|
||||||
pytorch_version: '1.4'
|
|
||||||
- binary_linux_conda:
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
cu_version: cu101
|
|
||||||
name: linux_conda_py38_cu101_pyt14
|
|
||||||
python_version: '3.8'
|
|
||||||
pytorch_version: '1.4'
|
|
||||||
- binary_linux_conda:
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
cu_version: cu92
|
|
||||||
name: linux_conda_py38_cu92_pyt150
|
|
||||||
python_version: '3.8'
|
|
||||||
pytorch_version: 1.5.0
|
|
||||||
- binary_linux_conda:
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
cu_version: cu101
|
|
||||||
name: linux_conda_py38_cu101_pyt150
|
|
||||||
python_version: '3.8'
|
|
||||||
pytorch_version: 1.5.0
|
|
||||||
- binary_linux_conda:
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
cu_version: cu102
|
|
||||||
name: linux_conda_py38_cu102_pyt150
|
|
||||||
python_version: '3.8'
|
|
||||||
pytorch_version: 1.5.0
|
|
||||||
- binary_linux_conda:
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
cu_version: cu92
|
|
||||||
name: linux_conda_py38_cu92_pyt151
|
|
||||||
python_version: '3.8'
|
|
||||||
pytorch_version: 1.5.1
|
|
||||||
- binary_linux_conda:
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
cu_version: cu101
|
|
||||||
name: linux_conda_py38_cu101_pyt151
|
|
||||||
python_version: '3.8'
|
|
||||||
pytorch_version: 1.5.1
|
|
||||||
- binary_linux_conda:
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
cu_version: cu102
|
|
||||||
name: linux_conda_py38_cu102_pyt151
|
|
||||||
python_version: '3.8'
|
|
||||||
pytorch_version: 1.5.1
|
|
||||||
- binary_linux_conda:
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
cu_version: cu92
|
|
||||||
name: linux_conda_py38_cu92_pyt160
|
|
||||||
python_version: '3.8'
|
|
||||||
pytorch_version: 1.6.0
|
|
||||||
- binary_linux_conda:
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
cu_version: cu101
|
|
||||||
name: linux_conda_py38_cu101_pyt160
|
|
||||||
python_version: '3.8'
|
|
||||||
pytorch_version: 1.6.0
|
|
||||||
- binary_linux_conda:
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
cu_version: cu102
|
|
||||||
name: linux_conda_py38_cu102_pyt160
|
|
||||||
python_version: '3.8'
|
|
||||||
pytorch_version: 1.6.0
|
|
||||||
- binary_linux_conda:
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
cu_version: cu101
|
|
||||||
name: linux_conda_py38_cu101_pyt170
|
|
||||||
python_version: '3.8'
|
|
||||||
pytorch_version: 1.7.0
|
|
||||||
- binary_linux_conda:
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
cu_version: cu102
|
|
||||||
name: linux_conda_py38_cu102_pyt170
|
|
||||||
python_version: '3.8'
|
|
||||||
pytorch_version: 1.7.0
|
|
||||||
- binary_linux_conda:
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
cu_version: cu110
|
|
||||||
name: linux_conda_py38_cu110_pyt170
|
|
||||||
python_version: '3.8'
|
|
||||||
pytorch_version: 1.7.0
|
|
||||||
- binary_linux_wheel:
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
cu_version: cu101
|
|
||||||
name: linux_wheel_py36_cu101_pyt160
|
|
||||||
python_version: '3.6'
|
|
||||||
pytorch_version: 1.6.0
|
|
||||||
- binary_linux_wheel:
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
cu_version: cu101
|
|
||||||
name: linux_wheel_py37_cu101_pyt160
|
|
||||||
python_version: '3.7'
|
python_version: '3.7'
|
||||||
pytorch_version: 1.6.0
|
pytorch_version: 1.11.0
|
||||||
- binary_linux_wheel:
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda115
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu115
|
||||||
|
name: linux_conda_py37_cu115_pyt1110
|
||||||
|
python_version: '3.7'
|
||||||
|
pytorch_version: 1.11.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu102
|
||||||
|
name: linux_conda_py37_cu102_pyt1120
|
||||||
|
python_version: '3.7'
|
||||||
|
pytorch_version: 1.12.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda113
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu113
|
||||||
|
name: linux_conda_py37_cu113_pyt1120
|
||||||
|
python_version: '3.7'
|
||||||
|
pytorch_version: 1.12.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda116
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu116
|
||||||
|
name: linux_conda_py37_cu116_pyt1120
|
||||||
|
python_version: '3.7'
|
||||||
|
pytorch_version: 1.12.0
|
||||||
|
- binary_linux_conda:
|
||||||
context: DOCKERHUB_TOKEN
|
context: DOCKERHUB_TOKEN
|
||||||
cu_version: cu101
|
cu_version: cu101
|
||||||
name: linux_wheel_py38_cu101_pyt160
|
name: linux_conda_py38_cu101_pyt180
|
||||||
python_version: '3.8'
|
python_version: '3.8'
|
||||||
pytorch_version: 1.6.0
|
pytorch_version: 1.8.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu102
|
||||||
|
name: linux_conda_py38_cu102_pyt180
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.8.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu111
|
||||||
|
name: linux_conda_py38_cu111_pyt180
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.8.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu101
|
||||||
|
name: linux_conda_py38_cu101_pyt181
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.8.1
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu102
|
||||||
|
name: linux_conda_py38_cu102_pyt181
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.8.1
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu111
|
||||||
|
name: linux_conda_py38_cu111_pyt181
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.8.1
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu102
|
||||||
|
name: linux_conda_py38_cu102_pyt190
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.9.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu111
|
||||||
|
name: linux_conda_py38_cu111_pyt190
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.9.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu102
|
||||||
|
name: linux_conda_py38_cu102_pyt191
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.9.1
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu111
|
||||||
|
name: linux_conda_py38_cu111_pyt191
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.9.1
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu102
|
||||||
|
name: linux_conda_py38_cu102_pyt1100
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.10.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu111
|
||||||
|
name: linux_conda_py38_cu111_pyt1100
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.10.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda113
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu113
|
||||||
|
name: linux_conda_py38_cu113_pyt1100
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.10.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu102
|
||||||
|
name: linux_conda_py38_cu102_pyt1101
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.10.1
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu111
|
||||||
|
name: linux_conda_py38_cu111_pyt1101
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.10.1
|
||||||
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda113
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu113
|
||||||
|
name: linux_conda_py38_cu113_pyt1101
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.10.1
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu102
|
||||||
|
name: linux_conda_py38_cu102_pyt1102
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.10.2
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu111
|
||||||
|
name: linux_conda_py38_cu111_pyt1102
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.10.2
|
||||||
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda113
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu113
|
||||||
|
name: linux_conda_py38_cu113_pyt1102
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.10.2
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu102
|
||||||
|
name: linux_conda_py38_cu102_pyt1110
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.11.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu111
|
||||||
|
name: linux_conda_py38_cu111_pyt1110
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.11.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda113
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu113
|
||||||
|
name: linux_conda_py38_cu113_pyt1110
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.11.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda115
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu115
|
||||||
|
name: linux_conda_py38_cu115_pyt1110
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.11.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu102
|
||||||
|
name: linux_conda_py38_cu102_pyt1120
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.12.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda113
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu113
|
||||||
|
name: linux_conda_py38_cu113_pyt1120
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.12.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda116
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu116
|
||||||
|
name: linux_conda_py38_cu116_pyt1120
|
||||||
|
python_version: '3.8'
|
||||||
|
pytorch_version: 1.12.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu101
|
||||||
|
name: linux_conda_py39_cu101_pyt180
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.8.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu102
|
||||||
|
name: linux_conda_py39_cu102_pyt180
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.8.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu111
|
||||||
|
name: linux_conda_py39_cu111_pyt180
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.8.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu101
|
||||||
|
name: linux_conda_py39_cu101_pyt181
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.8.1
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu102
|
||||||
|
name: linux_conda_py39_cu102_pyt181
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.8.1
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu111
|
||||||
|
name: linux_conda_py39_cu111_pyt181
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.8.1
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu102
|
||||||
|
name: linux_conda_py39_cu102_pyt190
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.9.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu111
|
||||||
|
name: linux_conda_py39_cu111_pyt190
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.9.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu102
|
||||||
|
name: linux_conda_py39_cu102_pyt191
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.9.1
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu111
|
||||||
|
name: linux_conda_py39_cu111_pyt191
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.9.1
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu102
|
||||||
|
name: linux_conda_py39_cu102_pyt1100
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.10.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu111
|
||||||
|
name: linux_conda_py39_cu111_pyt1100
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.10.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda113
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu113
|
||||||
|
name: linux_conda_py39_cu113_pyt1100
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.10.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu102
|
||||||
|
name: linux_conda_py39_cu102_pyt1101
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.10.1
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu111
|
||||||
|
name: linux_conda_py39_cu111_pyt1101
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.10.1
|
||||||
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda113
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu113
|
||||||
|
name: linux_conda_py39_cu113_pyt1101
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.10.1
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu102
|
||||||
|
name: linux_conda_py39_cu102_pyt1102
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.10.2
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu111
|
||||||
|
name: linux_conda_py39_cu111_pyt1102
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.10.2
|
||||||
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda113
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu113
|
||||||
|
name: linux_conda_py39_cu113_pyt1102
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.10.2
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu102
|
||||||
|
name: linux_conda_py39_cu102_pyt1110
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.11.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu111
|
||||||
|
name: linux_conda_py39_cu111_pyt1110
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.11.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda113
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu113
|
||||||
|
name: linux_conda_py39_cu113_pyt1110
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.11.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda115
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu115
|
||||||
|
name: linux_conda_py39_cu115_pyt1110
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.11.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu102
|
||||||
|
name: linux_conda_py39_cu102_pyt1120
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.12.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda113
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu113
|
||||||
|
name: linux_conda_py39_cu113_pyt1120
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.12.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda116
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu116
|
||||||
|
name: linux_conda_py39_cu116_pyt1120
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: 1.12.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu102
|
||||||
|
name: linux_conda_py310_cu102_pyt1110
|
||||||
|
python_version: '3.10'
|
||||||
|
pytorch_version: 1.11.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu111
|
||||||
|
name: linux_conda_py310_cu111_pyt1110
|
||||||
|
python_version: '3.10'
|
||||||
|
pytorch_version: 1.11.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda113
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu113
|
||||||
|
name: linux_conda_py310_cu113_pyt1110
|
||||||
|
python_version: '3.10'
|
||||||
|
pytorch_version: 1.11.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda115
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu115
|
||||||
|
name: linux_conda_py310_cu115_pyt1110
|
||||||
|
python_version: '3.10'
|
||||||
|
pytorch_version: 1.11.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu102
|
||||||
|
name: linux_conda_py310_cu102_pyt1120
|
||||||
|
python_version: '3.10'
|
||||||
|
pytorch_version: 1.12.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda113
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu113
|
||||||
|
name: linux_conda_py310_cu113_pyt1120
|
||||||
|
python_version: '3.10'
|
||||||
|
pytorch_version: 1.12.0
|
||||||
|
- binary_linux_conda:
|
||||||
|
conda_docker_image: pytorch/conda-builder:cuda116
|
||||||
|
context: DOCKERHUB_TOKEN
|
||||||
|
cu_version: cu116
|
||||||
|
name: linux_conda_py310_cu116_pyt1120
|
||||||
|
python_version: '3.10'
|
||||||
|
pytorch_version: 1.12.0
|
||||||
- binary_linux_conda_cuda:
|
- binary_linux_conda_cuda:
|
||||||
name: testrun_conda_cuda_py36_cu101_pyt14
|
name: testrun_conda_cuda_py37_cu102_pyt190
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
python_version: "3.6"
|
|
||||||
pytorch_version: "1.4"
|
|
||||||
cu_version: "cu101"
|
|
||||||
- binary_linux_conda_cuda:
|
|
||||||
name: testrun_conda_cuda_py37_cu102_pyt160
|
|
||||||
context: DOCKERHUB_TOKEN
|
context: DOCKERHUB_TOKEN
|
||||||
python_version: "3.7"
|
python_version: "3.7"
|
||||||
pytorch_version: '1.6.0'
|
pytorch_version: '1.9.0'
|
||||||
cu_version: "cu102"
|
cu_version: "cu102"
|
||||||
- binary_linux_conda_cuda:
|
|
||||||
name: testrun_conda_cuda_py37_cu110_pyt170
|
|
||||||
context: DOCKERHUB_TOKEN
|
|
||||||
python_version: "3.7"
|
|
||||||
pytorch_version: '1.7.0'
|
|
||||||
cu_version: "cu110"
|
|
||||||
- binary_macos_wheel:
|
|
||||||
cu_version: cpu
|
|
||||||
name: macos_wheel_py36_cpu
|
|
||||||
python_version: '3.6'
|
|
||||||
pytorch_version: '1.6.0'
|
|
||||||
- binary_macos_wheel:
|
- binary_macos_wheel:
|
||||||
cu_version: cpu
|
cu_version: cpu
|
||||||
name: macos_wheel_py37_cpu
|
name: macos_wheel_py37_cpu
|
||||||
python_version: '3.7'
|
python_version: '3.7'
|
||||||
pytorch_version: '1.6.0'
|
pytorch_version: '1.12.0'
|
||||||
- binary_macos_wheel:
|
- binary_macos_wheel:
|
||||||
cu_version: cpu
|
cu_version: cpu
|
||||||
name: macos_wheel_py38_cpu
|
name: macos_wheel_py38_cpu
|
||||||
python_version: '3.8'
|
python_version: '3.8'
|
||||||
pytorch_version: '1.6.0'
|
pytorch_version: '1.12.0'
|
||||||
|
- binary_macos_wheel:
|
||||||
|
cu_version: cpu
|
||||||
|
name: macos_wheel_py39_cpu
|
||||||
|
python_version: '3.9'
|
||||||
|
pytorch_version: '1.12.0'
|
||||||
|
|||||||
@@ -1,5 +1,9 @@
|
|||||||
#!/usr/bin/env python3
|
#!/usr/bin/env python3
|
||||||
# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
"""
|
"""
|
||||||
This script is adapted from the torchvision one.
|
This script is adapted from the torchvision one.
|
||||||
@@ -9,25 +13,59 @@ import os.path
|
|||||||
|
|
||||||
import jinja2
|
import jinja2
|
||||||
import yaml
|
import yaml
|
||||||
|
from packaging import version
|
||||||
|
|
||||||
|
|
||||||
# The CUDA versions which have pytorch conda packages available for linux for each
|
# The CUDA versions which have pytorch conda packages available for linux for each
|
||||||
# version of pytorch.
|
# version of pytorch.
|
||||||
# Pytorch 1.4 also supports cuda 10.0 but we no longer build for cuda 10.0 at all.
|
# Pytorch 1.4 also supports cuda 10.0 but we no longer build for cuda 10.0 at all.
|
||||||
CONDA_CUDA_VERSIONS = {
|
CONDA_CUDA_VERSIONS = {
|
||||||
"1.4": ["cu92", "cu101"],
|
"1.8.0": ["cu101", "cu102", "cu111"],
|
||||||
"1.5.0": ["cu92", "cu101", "cu102"],
|
"1.8.1": ["cu101", "cu102", "cu111"],
|
||||||
"1.5.1": ["cu92", "cu101", "cu102"],
|
"1.9.0": ["cu102", "cu111"],
|
||||||
"1.6.0": ["cu92", "cu101", "cu102"],
|
"1.9.1": ["cu102", "cu111"],
|
||||||
"1.7.0": ["cu101", "cu102", "cu110"],
|
"1.10.0": ["cu102", "cu111", "cu113"],
|
||||||
|
"1.10.1": ["cu102", "cu111", "cu113"],
|
||||||
|
"1.10.2": ["cu102", "cu111", "cu113"],
|
||||||
|
"1.11.0": ["cu102", "cu111", "cu113", "cu115"],
|
||||||
|
"1.12.0": ["cu102", "cu113", "cu116"],
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def conda_docker_image_for_cuda(cuda_version):
|
||||||
|
if cuda_version in ("cu101", "cu102", "cu111"):
|
||||||
|
return None
|
||||||
|
if cuda_version == "cu113":
|
||||||
|
return "pytorch/conda-builder:cuda113"
|
||||||
|
if cuda_version == "cu115":
|
||||||
|
return "pytorch/conda-builder:cuda115"
|
||||||
|
if cuda_version == "cu116":
|
||||||
|
return "pytorch/conda-builder:cuda116"
|
||||||
|
raise ValueError("Unknown cuda version")
|
||||||
|
|
||||||
|
|
||||||
|
def pytorch_versions_for_python(python_version):
|
||||||
|
if python_version in ["3.7", "3.8"]:
|
||||||
|
return list(CONDA_CUDA_VERSIONS)
|
||||||
|
if python_version == "3.9":
|
||||||
|
return [
|
||||||
|
i
|
||||||
|
for i in CONDA_CUDA_VERSIONS
|
||||||
|
if version.Version(i) > version.Version("1.7.0")
|
||||||
|
]
|
||||||
|
if python_version == "3.10":
|
||||||
|
return [
|
||||||
|
i
|
||||||
|
for i in CONDA_CUDA_VERSIONS
|
||||||
|
if version.Version(i) >= version.Version("1.11.0")
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
def workflows(prefix="", filter_branch=None, upload=False, indentation=6):
|
def workflows(prefix="", filter_branch=None, upload=False, indentation=6):
|
||||||
w = []
|
w = []
|
||||||
for btype in ["conda"]:
|
for btype in ["conda"]:
|
||||||
for python_version in ["3.6", "3.7", "3.8"]:
|
for python_version in ["3.7", "3.8", "3.9", "3.10"]:
|
||||||
for pytorch_version in ["1.4", "1.5.0", "1.5.1", "1.6.0", "1.7.0"]:
|
for pytorch_version in pytorch_versions_for_python(python_version):
|
||||||
for cu_version in CONDA_CUDA_VERSIONS[pytorch_version]:
|
for cu_version in CONDA_CUDA_VERSIONS[pytorch_version]:
|
||||||
w += workflow_pair(
|
w += workflow_pair(
|
||||||
btype=btype,
|
btype=btype,
|
||||||
@@ -38,18 +76,6 @@ def workflows(prefix="", filter_branch=None, upload=False, indentation=6):
|
|||||||
upload=upload,
|
upload=upload,
|
||||||
filter_branch=filter_branch,
|
filter_branch=filter_branch,
|
||||||
)
|
)
|
||||||
for btype in ["wheel"]:
|
|
||||||
for python_version in ["3.6", "3.7", "3.8"]:
|
|
||||||
for cu_version in ["cu101"]:
|
|
||||||
w += workflow_pair(
|
|
||||||
btype=btype,
|
|
||||||
python_version=python_version,
|
|
||||||
pytorch_version="1.6.0",
|
|
||||||
cu_version=cu_version,
|
|
||||||
prefix=prefix,
|
|
||||||
upload=upload,
|
|
||||||
filter_branch=filter_branch,
|
|
||||||
)
|
|
||||||
|
|
||||||
return indent(indentation, w)
|
return indent(indentation, w)
|
||||||
|
|
||||||
@@ -112,6 +138,10 @@ def generate_base_workflow(
|
|||||||
"context": "DOCKERHUB_TOKEN",
|
"context": "DOCKERHUB_TOKEN",
|
||||||
}
|
}
|
||||||
|
|
||||||
|
conda_docker_image = conda_docker_image_for_cuda(cu_version)
|
||||||
|
if conda_docker_image is not None:
|
||||||
|
d["conda_docker_image"] = conda_docker_image
|
||||||
|
|
||||||
if filter_branch is not None:
|
if filter_branch is not None:
|
||||||
d["filters"] = {"branches": {"only": filter_branch}}
|
d["filters"] = {"branches": {"only": filter_branch}}
|
||||||
|
|
||||||
@@ -135,6 +165,8 @@ def generate_upload_workflow(*, base_workflow_name, btype, cu_version, filter_br
|
|||||||
|
|
||||||
|
|
||||||
def indent(indentation, data_list):
|
def indent(indentation, data_list):
|
||||||
|
if len(data_list) == 0:
|
||||||
|
return ""
|
||||||
return ("\n" + " " * indentation).join(
|
return ("\n" + " " * indentation).join(
|
||||||
yaml.dump(data_list, default_flow_style=False).splitlines()
|
yaml.dump(data_list, default_flow_style=False).splitlines()
|
||||||
)
|
)
|
||||||
|
|||||||
2
.github/CONTRIBUTING.md
vendored
2
.github/CONTRIBUTING.md
vendored
@@ -46,7 +46,7 @@ outlined on that page and do not file a public issue.
|
|||||||
## Coding Style
|
## Coding Style
|
||||||
We follow these [python](http://google.github.io/styleguide/pyguide.html) and [C++](https://google.github.io/styleguide/cppguide.html) style guides.
|
We follow these [python](http://google.github.io/styleguide/pyguide.html) and [C++](https://google.github.io/styleguide/cppguide.html) style guides.
|
||||||
|
|
||||||
For the linter to work, you will need to install `black`, `flake`, `isort` and `clang-format`, and
|
For the linter to work, you will need to install `black`, `flake`, `usort` and `clang-format`, and
|
||||||
they need to be fairly up to date.
|
they need to be fairly up to date.
|
||||||
|
|
||||||
## License
|
## License
|
||||||
|
|||||||
BIN
.github/fit_nerf.gif
vendored
Normal file
BIN
.github/fit_nerf.gif
vendored
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 4.4 MiB |
BIN
.github/fit_textured_volume.gif
vendored
Normal file
BIN
.github/fit_textured_volume.gif
vendored
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 3.5 MiB |
BIN
.github/nerf_project_logo.gif
vendored
Normal file
BIN
.github/nerf_project_logo.gif
vendored
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 4.9 MiB |
27
.github/workflows/stale.yml
vendored
Normal file
27
.github/workflows/stale.yml
vendored
Normal file
@@ -0,0 +1,27 @@
|
|||||||
|
name: Mark stale issues and pull requests
|
||||||
|
|
||||||
|
on:
|
||||||
|
schedule:
|
||||||
|
- cron: '31 5 * * *'
|
||||||
|
|
||||||
|
jobs:
|
||||||
|
stale:
|
||||||
|
|
||||||
|
runs-on: ubuntu-latest
|
||||||
|
permissions:
|
||||||
|
issues: write
|
||||||
|
pull-requests: write
|
||||||
|
|
||||||
|
steps:
|
||||||
|
- uses: actions/stale@v3
|
||||||
|
with:
|
||||||
|
repo-token: ${{ secrets.GITHUB_TOKEN }}
|
||||||
|
exempt-issue-labels: 'enhancement,how-to'
|
||||||
|
stale-issue-message: 'This issue is stale because it has been open 30 days with no activity. Remove stale label or comment or this will be closed in 5 days.'
|
||||||
|
stale-pr-message: 'This PR is stale because it has been open 45 days with no activity. Remove stale label or comment or this will be closed in 10 days.'
|
||||||
|
close-issue-message: 'This issue was closed because it has been stalled for 5 days with no activity.'
|
||||||
|
close-pr-message: 'This PR was closed because it has been stalled for 10 days with no activity.'
|
||||||
|
days-before-issue-stale: 30
|
||||||
|
days-before-pr-stale: 45
|
||||||
|
days-before-issue-close: 5
|
||||||
|
days-before-pr-close: 10
|
||||||
83
INSTALL.md
83
INSTALL.md
@@ -5,23 +5,24 @@
|
|||||||
|
|
||||||
### Core library
|
### Core library
|
||||||
|
|
||||||
The core library is written in PyTorch. Several components have underlying implementation in CUDA for improved performance. A subset of these components have CPU implementations in C++/Pytorch. It is advised to use PyTorch3D with GPU support in order to use all the features.
|
The core library is written in PyTorch. Several components have underlying implementation in CUDA for improved performance. A subset of these components have CPU implementations in C++/PyTorch. It is advised to use PyTorch3D with GPU support in order to use all the features.
|
||||||
|
|
||||||
- Linux or macOS or Windows
|
- Linux or macOS or Windows
|
||||||
- Python 3.6, 3.7 or 3.8
|
- Python 3.6, 3.7, 3.8 or 3.9
|
||||||
- PyTorch 1.4, 1.5.0, 1.5.1, 1.6.0, or 1.7.0.
|
- PyTorch 1.8.0, 1.8.1, 1.9.0, 1.9.1, 1.10.0, 1.10.1, 1.10.2, 1.11.0 or 1.12.0.
|
||||||
- torchvision that matches the PyTorch installation. You can install them together as explained at pytorch.org to make sure of this.
|
- torchvision that matches the PyTorch installation. You can install them together as explained at pytorch.org to make sure of this.
|
||||||
- gcc & g++ ≥ 4.9
|
- gcc & g++ ≥ 4.9
|
||||||
- [fvcore](https://github.com/facebookresearch/fvcore)
|
- [fvcore](https://github.com/facebookresearch/fvcore)
|
||||||
|
- [ioPath](https://github.com/facebookresearch/iopath)
|
||||||
- If CUDA is to be used, use a version which is supported by the corresponding pytorch version and at least version 9.2.
|
- If CUDA is to be used, use a version which is supported by the corresponding pytorch version and at least version 9.2.
|
||||||
- If CUDA is to be used and you are building from source, the CUB library must be available. We recommend version 1.10.0.
|
- If CUDA is to be used and you are building from source, the CUB library must be available. We recommend version 1.10.0.
|
||||||
|
|
||||||
The runtime dependencies can be installed by running:
|
The runtime dependencies can be installed by running:
|
||||||
```
|
```
|
||||||
conda create -n pytorch3d python=3.8
|
conda create -n pytorch3d python=3.9
|
||||||
conda activate pytorch3d
|
conda activate pytorch3d
|
||||||
conda install -c pytorch pytorch=1.7.0 torchvision cudatoolkit=10.2
|
conda install -c pytorch pytorch=1.9.1 torchvision cudatoolkit=10.2
|
||||||
conda install -c conda-forge -c fvcore fvcore
|
conda install -c fvcore -c iopath -c conda-forge fvcore iopath
|
||||||
```
|
```
|
||||||
|
|
||||||
For the CUB build time dependency, if you are using conda, you can continue with
|
For the CUB build time dependency, if you are using conda, you can continue with
|
||||||
@@ -42,7 +43,7 @@ export CUB_HOME=$PWD/cub-1.10.0
|
|||||||
For developing on top of PyTorch3D or contributing, you will need to run the linter and tests. If you want to run any of the notebook tutorials as `docs/tutorials` or the examples in `docs/examples` you will also need matplotlib and OpenCV.
|
For developing on top of PyTorch3D or contributing, you will need to run the linter and tests. If you want to run any of the notebook tutorials as `docs/tutorials` or the examples in `docs/examples` you will also need matplotlib and OpenCV.
|
||||||
- scikit-image
|
- scikit-image
|
||||||
- black
|
- black
|
||||||
- isort
|
- usort
|
||||||
- flake8
|
- flake8
|
||||||
- matplotlib
|
- matplotlib
|
||||||
- tdqm
|
- tdqm
|
||||||
@@ -58,7 +59,7 @@ conda install jupyter
|
|||||||
pip install scikit-image matplotlib imageio plotly opencv-python
|
pip install scikit-image matplotlib imageio plotly opencv-python
|
||||||
|
|
||||||
# Tests/Linting
|
# Tests/Linting
|
||||||
pip install black 'isort<5' flake8 flake8-bugbear flake8-comprehensions
|
pip install black usort flake8 flake8-bugbear flake8-comprehensions
|
||||||
```
|
```
|
||||||
|
|
||||||
## Installing prebuilt binaries for PyTorch3D
|
## Installing prebuilt binaries for PyTorch3D
|
||||||
@@ -76,12 +77,33 @@ Or, to install a nightly (non-official, alpha) build:
|
|||||||
# Anaconda Cloud
|
# Anaconda Cloud
|
||||||
conda install pytorch3d -c pytorch3d-nightly
|
conda install pytorch3d -c pytorch3d-nightly
|
||||||
```
|
```
|
||||||
### 2. Install from PyPI, on Linux and Mac
|
### 2. Install from PyPI, on Mac only.
|
||||||
This works with pytorch 1.6.0 only.
|
This works with pytorch 1.12.0 only. The build is CPU only.
|
||||||
```
|
```
|
||||||
pip install pytorch3d
|
pip install pytorch3d
|
||||||
```
|
```
|
||||||
On Linux this has support for CUDA 10.1. On Mac this is CPU-only.
|
|
||||||
|
### 3. Install wheels for Linux
|
||||||
|
We have prebuilt wheels with CUDA for Linux for PyTorch 1.11.0, for each of the supported CUDA versions,
|
||||||
|
for Python 3.7, 3.8 and 3.9. This is for ease of use on Google Colab.
|
||||||
|
These are installed in a special way.
|
||||||
|
For example, to install for Python 3.8, PyTorch 1.11.0 and CUDA 11.3
|
||||||
|
```
|
||||||
|
pip install --no-index --no-cache-dir pytorch3d -f https://dl.fbaipublicfiles.com/pytorch3d/packaging/wheels/py38_cu113_pyt1110/download.html
|
||||||
|
```
|
||||||
|
|
||||||
|
In general, from inside IPython, or in Google Colab or a jupyter notebook, you can install with
|
||||||
|
```
|
||||||
|
import sys
|
||||||
|
import torch
|
||||||
|
pyt_version_str=torch.__version__.split("+")[0].replace(".", "")
|
||||||
|
version_str="".join([
|
||||||
|
f"py3{sys.version_info.minor}_cu",
|
||||||
|
torch.version.cuda.replace(".",""),
|
||||||
|
f"_pyt{pyt_version_str}"
|
||||||
|
])
|
||||||
|
!pip install --no-index --no-cache-dir pytorch3d -f https://dl.fbaipublicfiles.com/pytorch3d/packaging/wheels/{version_str}/download.html
|
||||||
|
```
|
||||||
|
|
||||||
## Building / installing from source.
|
## Building / installing from source.
|
||||||
CUDA support will be included if CUDA is available in pytorch or if the environment variable
|
CUDA support will be included if CUDA is available in pytorch or if the environment variable
|
||||||
@@ -89,11 +111,11 @@ CUDA support will be included if CUDA is available in pytorch or if the environm
|
|||||||
|
|
||||||
### 1. Install from GitHub
|
### 1. Install from GitHub
|
||||||
```
|
```
|
||||||
pip install 'git+https://github.com/facebookresearch/pytorch3d.git'
|
pip install "git+https://github.com/facebookresearch/pytorch3d.git"
|
||||||
```
|
```
|
||||||
To install using the code of the released version instead of from the main branch, use the following instead.
|
To install using the code of the released version instead of from the main branch, use the following instead.
|
||||||
```
|
```
|
||||||
pip install 'git+https://github.com/facebookresearch/pytorch3d.git@stable'
|
pip install "git+https://github.com/facebookresearch/pytorch3d.git@stable"
|
||||||
```
|
```
|
||||||
|
|
||||||
For CUDA builds with versions earlier than CUDA 11, set `CUB_HOME` before building as described above.
|
For CUDA builds with versions earlier than CUDA 11, set `CUB_HOME` before building as described above.
|
||||||
@@ -101,7 +123,7 @@ For CUDA builds with versions earlier than CUDA 11, set `CUB_HOME` before buildi
|
|||||||
**Install from Github on macOS:**
|
**Install from Github on macOS:**
|
||||||
Some environment variables should be provided, like this.
|
Some environment variables should be provided, like this.
|
||||||
```
|
```
|
||||||
MACOSX_DEPLOYMENT_TARGET=10.14 CC=clang CXX=clang++ pip install 'git+https://github.com/facebookresearch/pytorch3d.git'
|
MACOSX_DEPLOYMENT_TARGET=10.14 CC=clang CXX=clang++ pip install "git+https://github.com/facebookresearch/pytorch3d.git"
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2. Install from a local clone
|
### 2. Install from a local clone
|
||||||
@@ -118,40 +140,17 @@ MACOSX_DEPLOYMENT_TARGET=10.14 CC=clang CXX=clang++ pip install -e .
|
|||||||
|
|
||||||
**Install from local clone on Windows:**
|
**Install from local clone on Windows:**
|
||||||
|
|
||||||
If you are using pre-compiled pytorch 1.4 and torchvision 0.5, you should make the following changes to the pytorch source code to successfully compile with Visual Studio 2019 (MSVC 19.16.27034) and CUDA 10.1.
|
Depending on the version of PyTorch, changes to some PyTorch headers may be needed before compilation. These are often discussed in issues in this repository.
|
||||||
|
|
||||||
Change python/Lib/site-packages/torch/include/csrc/jit/script/module.h
|
After any necessary patching, you can go to "x64 Native Tools Command Prompt for VS 2019" to compile and install
|
||||||
|
|
||||||
L466, 476, 493, 506, 536
|
|
||||||
```
|
|
||||||
-static constexpr *
|
|
||||||
+static const *
|
|
||||||
```
|
|
||||||
Change python/Lib/site-packages/torch/include/csrc/jit/argument_spec.h
|
|
||||||
|
|
||||||
L190
|
|
||||||
```
|
|
||||||
-static constexpr size_t DEPTH_LIMIT = 128;
|
|
||||||
+static const size_t DEPTH_LIMIT = 128;
|
|
||||||
```
|
|
||||||
|
|
||||||
Change python/Lib/site-packages/torch/include/pybind11/cast.h
|
|
||||||
|
|
||||||
L1449
|
|
||||||
```
|
|
||||||
-explicit operator type&() { return *(this->value); }
|
|
||||||
+explicit operator type& () { return *((type*)(this->value)); }
|
|
||||||
```
|
|
||||||
|
|
||||||
After patching, you can go to "x64 Native Tools Command Prompt for VS 2019" to compile and install
|
|
||||||
```
|
```
|
||||||
cd pytorch3d
|
cd pytorch3d
|
||||||
python3 setup.py install
|
python3 setup.py install
|
||||||
```
|
```
|
||||||
After installing, verify whether all unit tests have passed
|
|
||||||
|
After installing, you can run **unit tests**
|
||||||
```
|
```
|
||||||
cd tests
|
python3 -m unittest discover -v -s tests -t .
|
||||||
python3 -m unittest discover -p *.py
|
|
||||||
```
|
```
|
||||||
|
|
||||||
# FAQ
|
# FAQ
|
||||||
|
|||||||
6
LICENSE
6
LICENSE
@@ -1,8 +1,8 @@
|
|||||||
BSD 3-Clause License
|
BSD License
|
||||||
|
|
||||||
For PyTorch3D software
|
For PyTorch3D software
|
||||||
|
|
||||||
Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
Copyright (c) Meta Platforms, Inc. and affiliates. All rights reserved.
|
||||||
|
|
||||||
Redistribution and use in source and binary forms, with or without modification,
|
Redistribution and use in source and binary forms, with or without modification,
|
||||||
are permitted provided that the following conditions are met:
|
are permitted provided that the following conditions are met:
|
||||||
@@ -14,7 +14,7 @@ are permitted provided that the following conditions are met:
|
|||||||
this list of conditions and the following disclaimer in the documentation
|
this list of conditions and the following disclaimer in the documentation
|
||||||
and/or other materials provided with the distribution.
|
and/or other materials provided with the distribution.
|
||||||
|
|
||||||
* Neither the name Facebook nor the names of its contributors may be used to
|
* Neither the name Meta nor the names of its contributors may be used to
|
||||||
endorse or promote products derived from this software without specific
|
endorse or promote products derived from this software without specific
|
||||||
prior written permission.
|
prior written permission.
|
||||||
|
|
||||||
|
|||||||
71
LICENSE-3RD-PARTY
Normal file
71
LICENSE-3RD-PARTY
Normal file
@@ -0,0 +1,71 @@
|
|||||||
|
SRN license ( https://github.com/vsitzmann/scene-representation-networks/ ):
|
||||||
|
|
||||||
|
MIT License
|
||||||
|
|
||||||
|
Copyright (c) 2019 Vincent Sitzmann
|
||||||
|
|
||||||
|
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||||
|
of this software and associated documentation files (the "Software"), to deal
|
||||||
|
in the Software without restriction, including without limitation the rights
|
||||||
|
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||||
|
copies of the Software, and to permit persons to whom the Software is
|
||||||
|
furnished to do so, subject to the following conditions:
|
||||||
|
|
||||||
|
The above copyright notice and this permission notice shall be included in all
|
||||||
|
copies or substantial portions of the Software.
|
||||||
|
|
||||||
|
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||||
|
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||||
|
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||||
|
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||||
|
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||||
|
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||||
|
SOFTWARE.
|
||||||
|
|
||||||
|
|
||||||
|
IDR license ( github.com/lioryariv/idr ):
|
||||||
|
|
||||||
|
MIT License
|
||||||
|
|
||||||
|
Copyright (c) 2020 Lior Yariv
|
||||||
|
|
||||||
|
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||||
|
of this software and associated documentation files (the "Software"), to deal
|
||||||
|
in the Software without restriction, including without limitation the rights
|
||||||
|
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||||
|
copies of the Software, and to permit persons to whom the Software is
|
||||||
|
furnished to do so, subject to the following conditions:
|
||||||
|
|
||||||
|
The above copyright notice and this permission notice shall be included in all
|
||||||
|
copies or substantial portions of the Software.
|
||||||
|
|
||||||
|
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||||
|
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||||
|
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||||
|
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||||
|
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||||
|
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||||
|
SOFTWARE.
|
||||||
|
|
||||||
|
|
||||||
|
NeRF https://github.com/bmild/nerf/
|
||||||
|
|
||||||
|
Copyright (c) 2020 bmild
|
||||||
|
|
||||||
|
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||||
|
of this software and associated documentation files (the "Software"), to deal
|
||||||
|
in the Software without restriction, including without limitation the rights
|
||||||
|
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||||
|
copies of the Software, and to permit persons to whom the Software is
|
||||||
|
furnished to do so, subject to the following conditions:
|
||||||
|
|
||||||
|
The above copyright notice and this permission notice shall be included in all
|
||||||
|
copies or substantial portions of the Software.
|
||||||
|
|
||||||
|
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||||
|
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||||
|
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||||
|
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||||
|
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||||
|
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||||
|
SOFTWARE.
|
||||||
64
README.md
64
README.md
@@ -1,4 +1,4 @@
|
|||||||
<img src="https://raw.githubusercontent.com/facebookresearch/pytorch3d/master/.github/pytorch3dlogo.png" width="900"/>
|
<img src="https://raw.githubusercontent.com/facebookresearch/pytorch3d/main/.github/pytorch3dlogo.png" width="900"/>
|
||||||
|
|
||||||
[](https://circleci.com/gh/facebookresearch/pytorch3d)
|
[](https://circleci.com/gh/facebookresearch/pytorch3d)
|
||||||
[](https://anaconda.org/pytorch3d/pytorch3d)
|
[](https://anaconda.org/pytorch3d/pytorch3d)
|
||||||
@@ -29,27 +29,34 @@ For detailed instructions refer to [INSTALL.md](INSTALL.md).
|
|||||||
|
|
||||||
## License
|
## License
|
||||||
|
|
||||||
PyTorch3D is released under the [BSD-3-Clause License](LICENSE).
|
PyTorch3D is released under the [BSD License](LICENSE).
|
||||||
|
|
||||||
## Tutorials
|
## Tutorials
|
||||||
|
|
||||||
Get started with PyTorch3D by trying one of the tutorial notebooks.
|
Get started with PyTorch3D by trying one of the tutorial notebooks.
|
||||||
|
|
||||||
|<img src="https://raw.githubusercontent.com/facebookresearch/pytorch3d/master/.github/dolphin_deform.gif" width="310"/>|<img src="https://raw.githubusercontent.com/facebookresearch/pytorch3d/master/.github/bundle_adjust.gif" width="310"/>|
|
|<img src="https://raw.githubusercontent.com/facebookresearch/pytorch3d/main/.github/dolphin_deform.gif" width="310"/>|<img src="https://raw.githubusercontent.com/facebookresearch/pytorch3d/main/.github/bundle_adjust.gif" width="310"/>|
|
||||||
|:-----------------------------------------------------------------------------------------------------------:|:--------------------------------------------------:|
|
|:-----------------------------------------------------------------------------------------------------------:|:--------------------------------------------------:|
|
||||||
| [Deform a sphere mesh to dolphin](https://github.com/facebookresearch/pytorch3d/blob/master/docs/tutorials/deform_source_mesh_to_target_mesh.ipynb)| [Bundle adjustment](https://github.com/facebookresearch/pytorch3d/blob/master/docs/tutorials/bundle_adjustment.ipynb) |
|
| [Deform a sphere mesh to dolphin](https://github.com/facebookresearch/pytorch3d/blob/main/docs/tutorials/deform_source_mesh_to_target_mesh.ipynb)| [Bundle adjustment](https://github.com/facebookresearch/pytorch3d/blob/main/docs/tutorials/bundle_adjustment.ipynb) |
|
||||||
|
|
||||||
| <img src="https://raw.githubusercontent.com/facebookresearch/pytorch3d/master/.github/render_textured_mesh.gif" width="310"/> | <img src="https://raw.githubusercontent.com/facebookresearch/pytorch3d/master/.github/camera_position_teapot.gif" width="310" height="310"/>
|
| <img src="https://raw.githubusercontent.com/facebookresearch/pytorch3d/main/.github/render_textured_mesh.gif" width="310"/> | <img src="https://raw.githubusercontent.com/facebookresearch/pytorch3d/main/.github/camera_position_teapot.gif" width="310" height="310"/>
|
||||||
|:------------------------------------------------------------:|:--------------------------------------------------:|
|
|:------------------------------------------------------------:|:--------------------------------------------------:|
|
||||||
| [Render textured meshes](https://github.com/facebookresearch/pytorch3d/blob/master/docs/tutorials/render_textured_meshes.ipynb)| [Camera position optimization](https://github.com/facebookresearch/pytorch3d/blob/master/docs/tutorials/camera_position_optimization_with_differentiable_rendering.ipynb)|
|
| [Render textured meshes](https://github.com/facebookresearch/pytorch3d/blob/main/docs/tutorials/render_textured_meshes.ipynb)| [Camera position optimization](https://github.com/facebookresearch/pytorch3d/blob/main/docs/tutorials/camera_position_optimization_with_differentiable_rendering.ipynb)|
|
||||||
|
|
||||||
| <img src="https://raw.githubusercontent.com/facebookresearch/pytorch3d/master/.github/pointcloud_render.png" width="310"/> | <img src="https://raw.githubusercontent.com/facebookresearch/pytorch3d/master/.github/cow_deform.gif" width="310" height="310"/>
|
| <img src="https://raw.githubusercontent.com/facebookresearch/pytorch3d/main/.github/pointcloud_render.png" width="310"/> | <img src="https://raw.githubusercontent.com/facebookresearch/pytorch3d/main/.github/cow_deform.gif" width="310" height="310"/>
|
||||||
|:------------------------------------------------------------:|:--------------------------------------------------:|
|
|:------------------------------------------------------------:|:--------------------------------------------------:|
|
||||||
| [Render textured pointclouds](https://github.com/facebookresearch/pytorch3d/blob/master/docs/tutorials/render_colored_points.ipynb)| [Fit a mesh with texture](https://github.com/facebookresearch/pytorch3d/blob/master/docs/tutorials/fit_textured_mesh.ipynb)|
|
| [Render textured pointclouds](https://github.com/facebookresearch/pytorch3d/blob/main/docs/tutorials/render_colored_points.ipynb)| [Fit a mesh with texture](https://github.com/facebookresearch/pytorch3d/blob/main/docs/tutorials/fit_textured_mesh.ipynb)|
|
||||||
|
|
||||||
| <img src="https://raw.githubusercontent.com/facebookresearch/pytorch3d/master/.github/densepose_render.png" width="310"/> | <img src="https://raw.githubusercontent.com/facebookresearch/pytorch3d/master/.github/shapenet_render.png" width="310" height="310"/>
|
| <img src="https://raw.githubusercontent.com/facebookresearch/pytorch3d/main/.github/densepose_render.png" width="310"/> | <img src="https://raw.githubusercontent.com/facebookresearch/pytorch3d/main/.github/shapenet_render.png" width="310" height="310"/>
|
||||||
|:------------------------------------------------------------:|:--------------------------------------------------:|
|
|:------------------------------------------------------------:|:--------------------------------------------------:|
|
||||||
| [Render DensePose data](https://github.com/facebookresearch/pytorch3d/blob/master/docs/tutorials/render_densepose.ipynb)| [Load & Render ShapeNet data](https://github.com/facebookresearch/pytorch3d/blob/master/docs/tutorials/dataloaders_ShapeNetCore_R2N2.ipynb)|
|
| [Render DensePose data](https://github.com/facebookresearch/pytorch3d/blob/main/docs/tutorials/render_densepose.ipynb)| [Load & Render ShapeNet data](https://github.com/facebookresearch/pytorch3d/blob/main/docs/tutorials/dataloaders_ShapeNetCore_R2N2.ipynb)|
|
||||||
|
|
||||||
|
| <img src="https://raw.githubusercontent.com/facebookresearch/pytorch3d/main/.github/fit_textured_volume.gif" width="310"/> | <img src="https://raw.githubusercontent.com/facebookresearch/pytorch3d/main/.github/fit_nerf.gif" width="310" height="310"/>
|
||||||
|
|:------------------------------------------------------------:|:--------------------------------------------------:|
|
||||||
|
| [Fit Textured Volume](https://github.com/facebookresearch/pytorch3d/blob/main/docs/tutorials/fit_textured_volume.ipynb)| [Fit A Simple Neural Radiance Field](https://github.com/facebookresearch/pytorch3d/blob/main/docs/tutorials/fit_simple_neural_radiance_field.ipynb)|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Documentation
|
## Documentation
|
||||||
|
|
||||||
@@ -57,9 +64,9 @@ Learn more about the API by reading the PyTorch3D [documentation](https://pytorc
|
|||||||
|
|
||||||
We also have deep dive notes on several API components:
|
We also have deep dive notes on several API components:
|
||||||
|
|
||||||
- [Heterogeneous Batching](https://github.com/facebookresearch/pytorch3d/tree/master/docs/notes/batching.md)
|
- [Heterogeneous Batching](https://github.com/facebookresearch/pytorch3d/tree/main/docs/notes/batching.md)
|
||||||
- [Mesh IO](https://github.com/facebookresearch/pytorch3d/tree/master/docs/notes/meshes_io.md)
|
- [Mesh IO](https://github.com/facebookresearch/pytorch3d/tree/main/docs/notes/meshes_io.md)
|
||||||
- [Differentiable Rendering](https://github.com/facebookresearch/pytorch3d/tree/master/docs/notes/renderer_getting_started.md)
|
- [Differentiable Rendering](https://github.com/facebookresearch/pytorch3d/tree/main/docs/notes/renderer_getting_started.md)
|
||||||
|
|
||||||
### Overview Video
|
### Overview Video
|
||||||
|
|
||||||
@@ -71,6 +78,13 @@ We have created a short (~14 min) video tutorial providing an overview of the Py
|
|||||||
|
|
||||||
We welcome new contributions to PyTorch3D and we will be actively maintaining this library! Please refer to [CONTRIBUTING.md](./.github/CONTRIBUTING.md) for full instructions on how to run the code, tests and linter, and submit your pull requests.
|
We welcome new contributions to PyTorch3D and we will be actively maintaining this library! Please refer to [CONTRIBUTING.md](./.github/CONTRIBUTING.md) for full instructions on how to run the code, tests and linter, and submit your pull requests.
|
||||||
|
|
||||||
|
## Development and Compatibility
|
||||||
|
|
||||||
|
- `main` branch: actively developed, without any guarantee, Anything can be broken at any time
|
||||||
|
- REMARK: this includes nightly builds which are built from `main`
|
||||||
|
- HINT: the commit history can help locate regressions or changes
|
||||||
|
- backward-compatibility between releases: no guarantee. Best efforts to communicate breaking changes and facilitate migration of code or data (incl. models).
|
||||||
|
|
||||||
## Contributors
|
## Contributors
|
||||||
|
|
||||||
PyTorch3D is written and maintained by the Facebook AI Research Computer Vision Team.
|
PyTorch3D is written and maintained by the Facebook AI Research Computer Vision Team.
|
||||||
@@ -83,7 +97,7 @@ In alphabetical order:
|
|||||||
* Georgia Gkioxari
|
* Georgia Gkioxari
|
||||||
* Taylor Gordon
|
* Taylor Gordon
|
||||||
* Justin Johnson
|
* Justin Johnson
|
||||||
* Patrick Labtut
|
* Patrick Labatut
|
||||||
* Christoph Lassner
|
* Christoph Lassner
|
||||||
* Wan-Yen Lo
|
* Wan-Yen Lo
|
||||||
* David Novotny
|
* David Novotny
|
||||||
@@ -111,8 +125,8 @@ If you are using the pulsar backend for sphere-rendering (the `PulsarPointRender
|
|||||||
|
|
||||||
```bibtex
|
```bibtex
|
||||||
@article{lassner2020pulsar,
|
@article{lassner2020pulsar,
|
||||||
author = {Christoph Lassner},
|
author = {Christoph Lassner and Michael Zollh\"ofer},
|
||||||
title = {Fast Differentiable Raycasting for Neural Rendering using Sphere-based Representations},
|
title = {Pulsar: Efficient Sphere-based Neural Rendering},
|
||||||
journal = {arXiv:2004.07484},
|
journal = {arXiv:2004.07484},
|
||||||
year = {2020},
|
year = {2020},
|
||||||
}
|
}
|
||||||
@@ -122,16 +136,24 @@ If you are using the pulsar backend for sphere-rendering (the `PulsarPointRender
|
|||||||
|
|
||||||
Please see below for a timeline of the codebase updates in reverse chronological order. We are sharing updates on the releases as well as research projects which are built with PyTorch3D. The changelogs for the releases are available under [`Releases`](https://github.com/facebookresearch/pytorch3d/releases), and the builds can be installed using `conda` as per the instructions in [INSTALL.md](INSTALL.md).
|
Please see below for a timeline of the codebase updates in reverse chronological order. We are sharing updates on the releases as well as research projects which are built with PyTorch3D. The changelogs for the releases are available under [`Releases`](https://github.com/facebookresearch/pytorch3d/releases), and the builds can be installed using `conda` as per the instructions in [INSTALL.md](INSTALL.md).
|
||||||
|
|
||||||
**[November 2nd 2020]:** PyTorch3D v0.3 released, integrating the pulsar backend.
|
**[Dec 16th 2021]:** PyTorch3D [v0.6.1](https://github.com/facebookresearch/pytorch3d/releases/tag/v0.6.1) released
|
||||||
|
|
||||||
**[Aug 28th 2020]:** PyTorch3D v0.2.5 released
|
**[Oct 6th 2021]:** PyTorch3D [v0.6.0](https://github.com/facebookresearch/pytorch3d/releases/tag/v0.6.0) released
|
||||||
|
|
||||||
|
**[Aug 5th 2021]:** PyTorch3D [v0.5.0](https://github.com/facebookresearch/pytorch3d/releases/tag/v0.5.0) released
|
||||||
|
|
||||||
|
**[Feb 9th 2021]:** PyTorch3D [v0.4.0](https://github.com/facebookresearch/pytorch3d/releases/tag/v0.4.0) released with support for implicit functions, volume rendering and a [reimplementation of NeRF](https://github.com/facebookresearch/pytorch3d/tree/main/projects/nerf).
|
||||||
|
|
||||||
|
**[November 2nd 2020]:** PyTorch3D [v0.3.0](https://github.com/facebookresearch/pytorch3d/releases/tag/v0.3.0) released, integrating the pulsar backend.
|
||||||
|
|
||||||
|
**[Aug 28th 2020]:** PyTorch3D [v0.2.5](https://github.com/facebookresearch/pytorch3d/releases/tag/v0.2.5) released
|
||||||
|
|
||||||
**[July 17th 2020]:** PyTorch3D tech report published on ArXiv: https://arxiv.org/abs/2007.08501
|
**[July 17th 2020]:** PyTorch3D tech report published on ArXiv: https://arxiv.org/abs/2007.08501
|
||||||
|
|
||||||
**[April 24th 2020]:** PyTorch3D v0.2 released
|
**[April 24th 2020]:** PyTorch3D [v0.2.0](https://github.com/facebookresearch/pytorch3d/releases/tag/v0.2.0) released
|
||||||
|
|
||||||
**[March 25th 2020]:** [SynSin](https://arxiv.org/abs/1912.08804) codebase released using PyTorch3D: https://github.com/facebookresearch/synsin
|
**[March 25th 2020]:** [SynSin](https://arxiv.org/abs/1912.08804) codebase released using PyTorch3D: https://github.com/facebookresearch/synsin
|
||||||
|
|
||||||
**[March 8th 2020]:** PyTorch3D v0.1.1 bug fix release
|
**[March 8th 2020]:** PyTorch3D [v0.1.1](https://github.com/facebookresearch/pytorch3d/releases/tag/v0.1.1) bug fix release
|
||||||
|
|
||||||
**[Jan 23rd 2020]:** PyTorch3D v0.1 released. [Mesh R-CNN](https://arxiv.org/abs/1906.02739) codebase released: https://github.com/facebookresearch/meshrcnn
|
**[Jan 23rd 2020]:** PyTorch3D [v0.1.0](https://github.com/facebookresearch/pytorch3d/releases/tag/v0.1.0) released. [Mesh R-CNN](https://arxiv.org/abs/1906.02739) codebase released: https://github.com/facebookresearch/meshrcnn
|
||||||
|
|||||||
@@ -1,35 +1,36 @@
|
|||||||
#!/bin/bash -e
|
#!/bin/bash -e
|
||||||
# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
# Run this script at project root by "./dev/linter.sh" before you commit
|
# Run this script at project root by "./dev/linter.sh" before you commit
|
||||||
|
|
||||||
{
|
|
||||||
V=$(black --version|cut '-d ' -f3)
|
|
||||||
code='import distutils.version; assert "19.3" < distutils.version.LooseVersion("'$V'")'
|
|
||||||
python -c "${code}" 2> /dev/null
|
|
||||||
} || {
|
|
||||||
echo "Linter requires black 19.3b0 or higher!"
|
|
||||||
exit 1
|
|
||||||
}
|
|
||||||
|
|
||||||
DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )"
|
DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )"
|
||||||
DIR=$(dirname "${DIR}")
|
DIR=$(dirname "${DIR}")
|
||||||
|
|
||||||
echo "Running isort..."
|
if [[ -f "${DIR}/TARGETS" ]]
|
||||||
isort -y -sp "${DIR}"
|
then
|
||||||
|
pyfmt "${DIR}"
|
||||||
|
else
|
||||||
|
# run usort externally only
|
||||||
|
echo "Running usort..."
|
||||||
|
usort "${DIR}"
|
||||||
|
fi
|
||||||
|
|
||||||
echo "Running black..."
|
echo "Running black..."
|
||||||
black "${DIR}"
|
black "${DIR}"
|
||||||
|
|
||||||
echo "Running flake..."
|
echo "Running flake..."
|
||||||
flake8 "${DIR}"
|
flake8 "${DIR}" || true
|
||||||
|
|
||||||
echo "Running clang-format ..."
|
echo "Running clang-format ..."
|
||||||
clangformat=$(command -v clang-format-8 || echo clang-format)
|
clangformat=$(command -v clang-format-8 || echo clang-format)
|
||||||
find "${DIR}" -regex ".*\.\(cpp\|c\|cc\|cu\|cuh\|cxx\|h\|hh\|hpp\|hxx\|tcc\|mm\|m\)" -print0 | xargs -0 "${clangformat}" -i
|
find "${DIR}" -regex ".*\.\(cpp\|c\|cc\|cu\|cuh\|cxx\|h\|hh\|hpp\|hxx\|tcc\|mm\|m\)" -print0 | xargs -0 "${clangformat}" -i
|
||||||
|
|
||||||
# Run arc and pyre internally only.
|
# Run arc and pyre internally only.
|
||||||
if [[ -f tests/TARGETS ]]
|
if [[ -f "${DIR}/TARGETS" ]]
|
||||||
then
|
then
|
||||||
(cd "${DIR}"; command -v arc > /dev/null && arc lint) || true
|
(cd "${DIR}"; command -v arc > /dev/null && arc lint) || true
|
||||||
|
|
||||||
|
|||||||
@@ -1,5 +1,9 @@
|
|||||||
#!/usr/bin/bash
|
#!/usr/bin/bash
|
||||||
# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
# This script is for running some of the tutorials using the nightly build in
|
# This script is for running some of the tutorials using the nightly build in
|
||||||
# an isolated environment. It is designed to be run in docker.
|
# an isolated environment. It is designed to be run in docker.
|
||||||
@@ -19,7 +23,7 @@ conda init bash
|
|||||||
source ~/.bashrc
|
source ~/.bashrc
|
||||||
conda create -y -n myenv python=3.8 matplotlib ipython ipywidgets nbconvert
|
conda create -y -n myenv python=3.8 matplotlib ipython ipywidgets nbconvert
|
||||||
conda activate myenv
|
conda activate myenv
|
||||||
conda install -y -c conda-forge fvcore
|
conda install -y -c fvcore -c iopath -c conda-forge fvcore iopath
|
||||||
conda install -y -c pytorch pytorch=1.6.0 cudatoolkit=10.1 torchvision
|
conda install -y -c pytorch pytorch=1.6.0 cudatoolkit=10.1 torchvision
|
||||||
conda install -y -c pytorch3d-nightly pytorch3d
|
conda install -y -c pytorch3d-nightly pytorch3d
|
||||||
pip install plotly scikit-image
|
pip install plotly scikit-image
|
||||||
|
|||||||
64
dev/test_list.py
Normal file
64
dev/test_list.py
Normal file
@@ -0,0 +1,64 @@
|
|||||||
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
|
import ast
|
||||||
|
from pathlib import Path
|
||||||
|
from typing import List
|
||||||
|
|
||||||
|
|
||||||
|
"""
|
||||||
|
This module outputs a list of tests for completion.
|
||||||
|
It has no dependencies.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
def get_test_files() -> List[Path]:
|
||||||
|
root = Path(__file__).parent.parent
|
||||||
|
return list((root / "tests").glob("**/test*.py"))
|
||||||
|
|
||||||
|
|
||||||
|
def tests_from_file(path: Path, base: str) -> List[str]:
|
||||||
|
"""
|
||||||
|
Returns all the tests in the given file, in format
|
||||||
|
expected as arguments when running the tests.
|
||||||
|
e.g.
|
||||||
|
file_stem
|
||||||
|
file_stem.TestFunctionality
|
||||||
|
file_stem.TestFunctionality.test_f
|
||||||
|
file_stem.TestFunctionality.test_g
|
||||||
|
"""
|
||||||
|
with open(path) as f:
|
||||||
|
node = ast.parse(f.read())
|
||||||
|
out = [base]
|
||||||
|
for cls in node.body:
|
||||||
|
if not isinstance(cls, ast.ClassDef):
|
||||||
|
continue
|
||||||
|
if not cls.name.startswith("Test"):
|
||||||
|
continue
|
||||||
|
class_base = base + "." + cls.name
|
||||||
|
out.append(class_base)
|
||||||
|
for method in cls.body:
|
||||||
|
if not isinstance(method, ast.FunctionDef):
|
||||||
|
continue
|
||||||
|
if not method.name.startswith("test"):
|
||||||
|
continue
|
||||||
|
out.append(class_base + "." + method.name)
|
||||||
|
return out
|
||||||
|
|
||||||
|
|
||||||
|
def main() -> None:
|
||||||
|
files = get_test_files()
|
||||||
|
test_root = Path(__file__).parent.parent
|
||||||
|
all_tests = []
|
||||||
|
for f in files:
|
||||||
|
file_base = str(f.relative_to(test_root))[:-3].replace("/", ".")
|
||||||
|
all_tests.extend(tests_from_file(f, file_base))
|
||||||
|
for test in sorted(all_tests):
|
||||||
|
print(test)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
main()
|
||||||
@@ -1,4 +1,8 @@
|
|||||||
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
# Minimal makefile for Sphinx documentation
|
# Minimal makefile for Sphinx documentation
|
||||||
|
|
||||||
|
|||||||
@@ -1,4 +1,3 @@
|
|||||||
|
|
||||||
## Setup
|
## Setup
|
||||||
|
|
||||||
### Install dependencies
|
### Install dependencies
|
||||||
|
|||||||
12
docs/conf.py
12
docs/conf.py
@@ -1,5 +1,9 @@
|
|||||||
# -*- coding: utf-8 -*-
|
# -*- coding: utf-8 -*-
|
||||||
# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
# flake8: noqa
|
# flake8: noqa
|
||||||
|
|
||||||
@@ -78,11 +82,11 @@ for m in ["cv2", "scipy", "numpy", "pytorch3d._C", "np.eye", "np.zeros"]:
|
|||||||
# -- Project information -----------------------------------------------------
|
# -- Project information -----------------------------------------------------
|
||||||
|
|
||||||
project = "PyTorch3D"
|
project = "PyTorch3D"
|
||||||
copyright = "2019, facebookresearch"
|
copyright = "Meta Platforms, Inc"
|
||||||
author = "facebookresearch"
|
author = "facebookresearch"
|
||||||
|
|
||||||
# The short X.Y version
|
# The short X.Y version
|
||||||
version = "0.2.0"
|
version = ""
|
||||||
|
|
||||||
# The full version, including alpha/beta/rc tags
|
# The full version, including alpha/beta/rc tags
|
||||||
release = version
|
release = version
|
||||||
@@ -155,7 +159,7 @@ html_theme_options = {"collapse_navigation": True}
|
|||||||
def url_resolver(url):
|
def url_resolver(url):
|
||||||
if ".html" not in url:
|
if ".html" not in url:
|
||||||
url = url.replace("../", "")
|
url = url.replace("../", "")
|
||||||
return "https://github.com/facebookresearch/pytorch3d/blob/master/" + url
|
return "https://github.com/facebookresearch/pytorch3d/blob/main/" + url
|
||||||
else:
|
else:
|
||||||
if DEPLOY:
|
if DEPLOY:
|
||||||
return "http://pytorch3d.readthedocs.io/" + url
|
return "http://pytorch3d.readthedocs.io/" + url
|
||||||
|
|||||||
@@ -1,5 +1,10 @@
|
|||||||
#!/usr/bin/env python3
|
#!/usr/bin/env python3
|
||||||
# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
"""
|
"""
|
||||||
This example demonstrates the most trivial, direct interface of the pulsar
|
This example demonstrates the most trivial, direct interface of the pulsar
|
||||||
sphere renderer. It renders and saves an image with 10 random spheres.
|
sphere renderer. It renders and saves an image with 10 random spheres.
|
||||||
|
|||||||
@@ -1,5 +1,10 @@
|
|||||||
#!/usr/bin/env python3
|
#!/usr/bin/env python3
|
||||||
# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
"""
|
"""
|
||||||
This example demonstrates the most trivial use of the pulsar PyTorch3D
|
This example demonstrates the most trivial use of the pulsar PyTorch3D
|
||||||
interface for sphere renderering. It renders and saves an image with
|
interface for sphere renderering. It renders and saves an image with
|
||||||
@@ -11,11 +16,8 @@ from os import path
|
|||||||
|
|
||||||
import imageio
|
import imageio
|
||||||
import torch
|
import torch
|
||||||
|
|
||||||
# Import `look_at_view_transform` as needed in the suggestion later in the
|
|
||||||
# example.
|
|
||||||
from pytorch3d.renderer import PerspectiveCameras # , look_at_view_transform
|
|
||||||
from pytorch3d.renderer import (
|
from pytorch3d.renderer import (
|
||||||
|
PerspectiveCameras,
|
||||||
PointsRasterizationSettings,
|
PointsRasterizationSettings,
|
||||||
PointsRasterizer,
|
PointsRasterizer,
|
||||||
PulsarPointsRenderer,
|
PulsarPointsRenderer,
|
||||||
@@ -56,12 +58,12 @@ def cli():
|
|||||||
focal_length=(5.0 * 2.0 / 2.0,),
|
focal_length=(5.0 * 2.0 / 2.0,),
|
||||||
R=torch.eye(3, dtype=torch.float32, device=device)[None, ...],
|
R=torch.eye(3, dtype=torch.float32, device=device)[None, ...],
|
||||||
T=torch.zeros((1, 3), dtype=torch.float32, device=device),
|
T=torch.zeros((1, 3), dtype=torch.float32, device=device),
|
||||||
image_size=((width, height),),
|
image_size=((height, width),),
|
||||||
device=device,
|
device=device,
|
||||||
)
|
)
|
||||||
vert_rad = torch.rand(n_points, dtype=torch.float32, device=device)
|
vert_rad = torch.rand(n_points, dtype=torch.float32, device=device)
|
||||||
raster_settings = PointsRasterizationSettings(
|
raster_settings = PointsRasterizationSettings(
|
||||||
image_size=(width, height),
|
image_size=(height, width),
|
||||||
radius=vert_rad,
|
radius=vert_rad,
|
||||||
)
|
)
|
||||||
rasterizer = PointsRasterizer(cameras=cameras, raster_settings=raster_settings)
|
rasterizer = PointsRasterizer(cameras=cameras, raster_settings=raster_settings)
|
||||||
|
|||||||
@@ -1,5 +1,10 @@
|
|||||||
#!/usr/bin/env python3
|
#!/usr/bin/env python3
|
||||||
# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
"""
|
"""
|
||||||
This example demonstrates camera parameter optimization with the plain
|
This example demonstrates camera parameter optimization with the plain
|
||||||
pulsar interface. For this, a reference image has been pre-generated
|
pulsar interface. For this, a reference image has been pre-generated
|
||||||
|
|||||||
@@ -1,5 +1,10 @@
|
|||||||
#!/usr/bin/env python3
|
#!/usr/bin/env python3
|
||||||
# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
"""
|
"""
|
||||||
This example demonstrates camera parameter optimization with the pulsar
|
This example demonstrates camera parameter optimization with the pulsar
|
||||||
PyTorch3D interface. For this, a reference image has been pre-generated
|
PyTorch3D interface. For this, a reference image has been pre-generated
|
||||||
@@ -16,10 +21,7 @@ import cv2
|
|||||||
import imageio
|
import imageio
|
||||||
import numpy as np
|
import numpy as np
|
||||||
import torch
|
import torch
|
||||||
|
from pytorch3d.renderer.cameras import PerspectiveCameras
|
||||||
# Import `look_at_view_transform` as needed in the suggestion later in the
|
|
||||||
# example.
|
|
||||||
from pytorch3d.renderer.cameras import PerspectiveCameras # , look_at_view_transform
|
|
||||||
from pytorch3d.renderer.points import (
|
from pytorch3d.renderer.points import (
|
||||||
PointsRasterizationSettings,
|
PointsRasterizationSettings,
|
||||||
PointsRasterizer,
|
PointsRasterizer,
|
||||||
@@ -123,11 +125,11 @@ class SceneModel(nn.Module):
|
|||||||
focal_length=self.focal_length,
|
focal_length=self.focal_length,
|
||||||
R=self.cam_rot[None, ...],
|
R=self.cam_rot[None, ...],
|
||||||
T=self.cam_pos[None, ...],
|
T=self.cam_pos[None, ...],
|
||||||
image_size=((WIDTH, HEIGHT),),
|
image_size=((HEIGHT, WIDTH),),
|
||||||
device=DEVICE,
|
device=DEVICE,
|
||||||
)
|
)
|
||||||
raster_settings = PointsRasterizationSettings(
|
raster_settings = PointsRasterizationSettings(
|
||||||
image_size=(WIDTH, HEIGHT),
|
image_size=(HEIGHT, WIDTH),
|
||||||
radius=self.vert_rad,
|
radius=self.vert_rad,
|
||||||
)
|
)
|
||||||
rasterizer = PointsRasterizer(
|
rasterizer = PointsRasterizer(
|
||||||
|
|||||||
@@ -1,5 +1,10 @@
|
|||||||
#!/usr/bin/env python3
|
#!/usr/bin/env python3
|
||||||
# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
"""
|
"""
|
||||||
This example demonstrates multiview 3D reconstruction using the plain
|
This example demonstrates multiview 3D reconstruction using the plain
|
||||||
pulsar interface. For this, reference images have been pre-generated
|
pulsar interface. For this, reference images have been pre-generated
|
||||||
|
|||||||
@@ -1,5 +1,10 @@
|
|||||||
#!/usr/bin/env python3
|
#!/usr/bin/env python3
|
||||||
# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
"""
|
"""
|
||||||
This example demonstrates scene optimization with the plain
|
This example demonstrates scene optimization with the plain
|
||||||
pulsar interface. For this, a reference image has been pre-generated
|
pulsar interface. For this, a reference image has been pre-generated
|
||||||
|
|||||||
@@ -1,5 +1,10 @@
|
|||||||
#!/usr/bin/env python3
|
#!/usr/bin/env python3
|
||||||
# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
"""
|
"""
|
||||||
This example demonstrates scene optimization with the PyTorch3D
|
This example demonstrates scene optimization with the PyTorch3D
|
||||||
pulsar interface. For this, a reference image has been pre-generated
|
pulsar interface. For this, a reference image has been pre-generated
|
||||||
@@ -15,10 +20,7 @@ import cv2
|
|||||||
import imageio
|
import imageio
|
||||||
import numpy as np
|
import numpy as np
|
||||||
import torch
|
import torch
|
||||||
|
from pytorch3d.renderer.cameras import PerspectiveCameras
|
||||||
# Import `look_at_view_transform` as needed in the suggestion later in the
|
|
||||||
# example.
|
|
||||||
from pytorch3d.renderer.cameras import PerspectiveCameras # , look_at_view_transform
|
|
||||||
from pytorch3d.renderer.points import (
|
from pytorch3d.renderer.points import (
|
||||||
PointsRasterizationSettings,
|
PointsRasterizationSettings,
|
||||||
PointsRasterizer,
|
PointsRasterizer,
|
||||||
@@ -84,11 +86,11 @@ class SceneModel(nn.Module):
|
|||||||
focal_length=5.0,
|
focal_length=5.0,
|
||||||
R=torch.eye(3, dtype=torch.float32, device=DEVICE)[None, ...],
|
R=torch.eye(3, dtype=torch.float32, device=DEVICE)[None, ...],
|
||||||
T=torch.zeros((1, 3), dtype=torch.float32, device=DEVICE),
|
T=torch.zeros((1, 3), dtype=torch.float32, device=DEVICE),
|
||||||
image_size=((WIDTH, HEIGHT),),
|
image_size=((HEIGHT, WIDTH),),
|
||||||
device=DEVICE,
|
device=DEVICE,
|
||||||
)
|
)
|
||||||
raster_settings = PointsRasterizationSettings(
|
raster_settings = PointsRasterizationSettings(
|
||||||
image_size=(WIDTH, HEIGHT),
|
image_size=(HEIGHT, WIDTH),
|
||||||
radius=self.vert_rad,
|
radius=self.vert_rad,
|
||||||
)
|
)
|
||||||
rasterizer = PointsRasterizer(
|
rasterizer = PointsRasterizer(
|
||||||
|
|||||||
6
docs/modules/common.rst
Normal file
6
docs/modules/common.rst
Normal file
@@ -0,0 +1,6 @@
|
|||||||
|
pytorch3d.common
|
||||||
|
===========================
|
||||||
|
|
||||||
|
.. automodule:: pytorch3d.common
|
||||||
|
:members:
|
||||||
|
:undoc-members:
|
||||||
@@ -11,3 +11,5 @@ API Documentation
|
|||||||
transforms
|
transforms
|
||||||
utils
|
utils
|
||||||
datasets
|
datasets
|
||||||
|
common
|
||||||
|
vis
|
||||||
|
|||||||
6
docs/modules/vis.rst
Normal file
6
docs/modules/vis.rst
Normal file
@@ -0,0 +1,6 @@
|
|||||||
|
pytorch3d.vis
|
||||||
|
===========================
|
||||||
|
|
||||||
|
.. automodule:: pytorch3d.vis
|
||||||
|
:members:
|
||||||
|
:undoc-members:
|
||||||
BIN
docs/notes/assets/iou3d.gif
Normal file
BIN
docs/notes/assets/iou3d.gif
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 221 KiB |
BIN
docs/notes/assets/iou3d_comp.png
Normal file
BIN
docs/notes/assets/iou3d_comp.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 12 KiB |
@@ -5,7 +5,7 @@ sidebar_label: Batching
|
|||||||
|
|
||||||
# Batching
|
# Batching
|
||||||
|
|
||||||
In deep learning, every optimization step operates on multiple input examples for robust training. Thus, efficient batching is crucial. For image inputs, batching is straighforward; N images are resized to the same height and width and stacked as a 4 dimensional tensor of shape `N x 3 x H x W`. For meshes, batching is less straighforward.
|
In deep learning, every optimization step operates on multiple input examples for robust training. Thus, efficient batching is crucial. For image inputs, batching is straightforward; N images are resized to the same height and width and stacked as a 4 dimensional tensor of shape `N x 3 x H x W`. For meshes, batching is less straightforward.
|
||||||
|
|
||||||
<img src="assets/batch_intro.png" alt="batch_intro" align="middle"/>
|
<img src="assets/batch_intro.png" alt="batch_intro" align="middle"/>
|
||||||
|
|
||||||
@@ -21,12 +21,12 @@ Assume you want to construct a batch containing two meshes, with `mesh1 = (v1: V
|
|||||||
|
|
||||||
## Use cases for batch modes
|
## Use cases for batch modes
|
||||||
|
|
||||||
The need for different mesh batch modes is inherent to the way pytorch operators are implemented. To fully utilize the optimized pytorch ops, the [Meshes][meshes] data structure allows for efficient conversion between the different batch modes. This is crucial when aiming for a fast and efficient training cycle. An example of this is [Mesh R-CNN][meshrcnn]. Here, in the same forward pass different parts of the network assume different inputs, which are computed by converting between the different batch modes. In particular, [vert_align][vert_align] assumes a *padded* input tensor while immediately after [graph_conv][graphconv] assumes a *packed* input tensor.
|
The need for different mesh batch modes is inherent to the way PyTorch operators are implemented. To fully utilize the optimized PyTorch ops, the [Meshes][meshes] data structure allows for efficient conversion between the different batch modes. This is crucial when aiming for a fast and efficient training cycle. An example of this is [Mesh R-CNN][meshrcnn]. Here, in the same forward pass different parts of the network assume different inputs, which are computed by converting between the different batch modes. In particular, [vert_align][vert_align] assumes a *padded* input tensor while immediately after [graph_conv][graphconv] assumes a *packed* input tensor.
|
||||||
|
|
||||||
<img src="assets/meshrcnn.png" alt="meshrcnn" width="700" align="middle" />
|
<img src="assets/meshrcnn.png" alt="meshrcnn" width="700" align="middle" />
|
||||||
|
|
||||||
|
|
||||||
[meshes]: https://github.com/facebookresearch/pytorch3d/blob/master/pytorch3d/structures/meshes.py
|
[meshes]: https://github.com/facebookresearch/pytorch3d/blob/main/pytorch3d/structures/meshes.py
|
||||||
[graphconv]: https://github.com/facebookresearch/pytorch3d/blob/master/pytorch3d/ops/graph_conv.py
|
[graphconv]: https://github.com/facebookresearch/pytorch3d/blob/main/pytorch3d/ops/graph_conv.py
|
||||||
[vert_align]: https://github.com/facebookresearch/pytorch3d/blob/master/pytorch3d/ops/vert_align.py
|
[vert_align]: https://github.com/facebookresearch/pytorch3d/blob/main/pytorch3d/ops/vert_align.py
|
||||||
[meshrcnn]: https://github.com/facebookresearch/meshrcnn
|
[meshrcnn]: https://github.com/facebookresearch/meshrcnn
|
||||||
|
|||||||
@@ -13,56 +13,89 @@ This is the system the object/scene lives - the world.
|
|||||||
* **Camera view coordinate system**
|
* **Camera view coordinate system**
|
||||||
This is the system that has its origin on the image plane and the `Z`-axis perpendicular to the image plane. In PyTorch3D, we assume that `+X` points left, and `+Y` points up and `+Z` points out from the image plane. The transformation from world to view happens after applying a rotation (`R`) and translation (`T`).
|
This is the system that has its origin on the image plane and the `Z`-axis perpendicular to the image plane. In PyTorch3D, we assume that `+X` points left, and `+Y` points up and `+Z` points out from the image plane. The transformation from world to view happens after applying a rotation (`R`) and translation (`T`).
|
||||||
* **NDC coordinate system**
|
* **NDC coordinate system**
|
||||||
This is the normalized coordinate system that confines in a volume the renderered part of the object/scene. Also known as view volume. Under the PyTorch3D convention, `(+1, +1, znear)` is the top left near corner, and `(-1, -1, zfar)` is the bottom right far corner of the volume. The transformation from view to NDC happens after applying the camera projection matrix (`P`).
|
This is the normalized coordinate system that confines in a volume the rendered part of the object/scene. Also known as view volume. For square images, under the PyTorch3D convention, `(+1, +1, znear)` is the top left near corner, and `(-1, -1, zfar)` is the bottom right far corner of the volume. For non-square images, the side of the volume in `XY` with the smallest length ranges from `[-1, 1]` while the larger side from `[-s, s]`, where `s` is the aspect ratio and `s > 1` (larger divided by smaller side).
|
||||||
|
The transformation from view to NDC happens after applying the camera projection matrix (`P`).
|
||||||
* **Screen coordinate system**
|
* **Screen coordinate system**
|
||||||
This is another representation of the view volume with the `XY` coordinates defined in pixel space instead of a normalized space.
|
This is another representation of the view volume with the `XY` coordinates defined in pixel space instead of a normalized space. (0,0) is the top left corner of the top left pixel
|
||||||
|
and (W,H) is the bottom right corner of the bottom right pixel.
|
||||||
|
|
||||||
An illustration of the 4 coordinate systems is shown below
|
An illustration of the 4 coordinate systems is shown below
|
||||||
|

|
||||||
|
|
||||||
## Defining Cameras in PyTorch3D
|
## Defining Cameras in PyTorch3D
|
||||||
|
|
||||||
Cameras in PyTorch3D transform an object/scene from world to NDC by first transforming the object/scene to view (via transforms `R` and `T`) and then projecting the 3D object/scene to NDC (via the projection matrix `P`, else known as camera matrix). Thus, the camera parameters in `P` are assumed to be in NDC space. If the user has camera parameters in screen space, which is a common use case, the parameters should transformed to NDC (see below for an example)
|
Cameras in PyTorch3D transform an object/scene from world to view by first transforming the object/scene to view (via transforms `R` and `T`) and then projecting the 3D object/scene to a normalized space via the projection matrix `P = K[R | T]`, where `K` is the intrinsic matrix. The camera parameters in `K` define the normalized space. If users define the camera parameters in NDC space, then the transform projects points to NDC. If the camera parameters are defined in screen space, the transformed points are in screen space.
|
||||||
|
|
||||||
We describe the camera types in PyTorch3D and the convention for the camera parameters provided at construction time.
|
Note that the base `CamerasBase` class makes no assumptions about the coordinate systems. All the above transforms are geometric transforms defined purely by `R`, `T` and `K`. This means that users can define cameras in any coordinate system and for any transforms. The method `transform_points` will apply `K` , `R` and `T` to the input points as a simple matrix transformation. However, if users wish to use cameras with the PyTorch3D renderer, they need to abide to PyTorch3D's coordinate system assumptions (read below).
|
||||||
|
|
||||||
|
We provide instantiations of common camera types in PyTorch3D and how users can flexibly define the projection space below.
|
||||||
|
|
||||||
|
## Interfacing with the PyTorch3D Renderer
|
||||||
|
|
||||||
|
The PyTorch3D renderer for both meshes and point clouds assumes that the camera transformed points, meaning the points passed as input to the rasterizer, are in PyTorch3D's NDC space. So to get the expected rendering outcome, users need to make sure that their 3D input data and cameras abide by these PyTorch3D coordinate system assumptions. The PyTorch3D coordinate system assumes `+X:left`, `+Y: up` and `+Z: from us to scene` (right-handed) . Confusions regarding coordinate systems are common so we advise that you spend some time understanding your data and the coordinate system they live in and transform them accordingly before using the PyTorch3D renderer.
|
||||||
|
|
||||||
|
Examples of cameras and how they interface with the PyTorch3D renderer can be found in our tutorials.
|
||||||
|
|
||||||
### Camera Types
|
### Camera Types
|
||||||
|
|
||||||
All cameras inherit from `CamerasBase` which is a base class for all cameras. PyTorch3D provides four different camera types. The `CamerasBase` defines methods that are common to all camera models:
|
All cameras inherit from `CamerasBase` which is a base class for all cameras. PyTorch3D provides four different camera types. The `CamerasBase` defines methods that are common to all camera models:
|
||||||
* `get_camera_center` that returns the optical center of the camera in world coordinates
|
* `get_camera_center` that returns the optical center of the camera in world coordinates
|
||||||
* `get_world_to_view_transform` which returns a 3D transform from world coordinates to the camera view coordinates (R, T)
|
* `get_world_to_view_transform` which returns a 3D transform from world coordinates to the camera view coordinates `(R, T)`
|
||||||
* `get_full_projection_transform` which composes the projection transform (P) with the world-to-view transform (R, T)
|
* `get_full_projection_transform` which composes the projection transform (`K`) with the world-to-view transform `(R, T)`
|
||||||
* `transform_points` which takes a set of input points in world coordinates and projects to NDC coordinates ranging from [-1, -1, znear] to [+1, +1, zfar].
|
* `transform_points` which takes a set of input points in world coordinates and projects to NDC coordinates ranging from [-1, -1, znear] to [+1, +1, zfar].
|
||||||
* `transform_points_screen` which takes a set of input points in world coordinates and projects them to the screen coordinates ranging from [0, 0, znear] to [W-1, H-1, zfar]
|
* `get_ndc_camera_transform` which defines the conversion to PyTorch3D's NDC space and is called when interfacing with the PyTorch3D renderer. If the camera is defined in NDC space, then the identity transform is returned. If the cameras is defined in screen space, the conversion from screen to NDC is returned. If users define their own camera in screen space, they need to think of the screen to NDC conversion. We provide examples for the `PerspectiveCameras` and `OrthographicCameras`.
|
||||||
|
* `transform_points_ndc` which takes a set of points in world coordinates and projects them to PyTorch3D's NDC space
|
||||||
|
* `transform_points_screen` which takes a set of input points in world coordinates and projects them to the screen coordinates ranging from [0, 0, znear] to [W, H, zfar]
|
||||||
|
|
||||||
Users can easily customize their own cameras. For each new camera, users should implement the `get_projection_transform` routine that returns the mapping `P` from camera view coordinates to NDC coordinates.
|
Users can easily customize their own cameras. For each new camera, users should implement the `get_projection_transform` routine that returns the mapping `P` from camera view coordinates to NDC coordinates.
|
||||||
|
|
||||||
#### FoVPerspectiveCameras, FoVOrthographicCameras
|
#### FoVPerspectiveCameras, FoVOrthographicCameras
|
||||||
These two cameras follow the OpenGL convention for perspective and orthographic cameras respectively. The user provides the near `znear` and far `zfar` field which confines the view volume in the `Z` axis. The view volume in the `XY` plane is defined by field of view angle (`fov`) in the case of `FoVPerspectiveCameras` and by `min_x, min_y, max_x, max_y` in the case of `FoVOrthographicCameras`.
|
These two cameras follow the OpenGL convention for perspective and orthographic cameras respectively. The user provides the near `znear` and far `zfar` field which confines the view volume in the `Z` axis. The view volume in the `XY` plane is defined by field of view angle (`fov`) in the case of `FoVPerspectiveCameras` and by `min_x, min_y, max_x, max_y` in the case of `FoVOrthographicCameras`.
|
||||||
|
These cameras are by default in NDC space.
|
||||||
|
|
||||||
#### PerspectiveCameras, OrthographicCameras
|
#### PerspectiveCameras, OrthographicCameras
|
||||||
These two cameras follow the Multi-View Geometry convention for cameras. The user provides the focal length (`fx`, `fy`) and the principal point (`px`, `py`). For example, `camera = PerspectiveCameras(focal_length=((fx, fy),), principal_point=((px, py),))`
|
These two cameras follow the Multi-View Geometry convention for cameras. The user provides the focal length (`fx`, `fy`) and the principal point (`px`, `py`). For example, `camera = PerspectiveCameras(focal_length=((fx, fy),), principal_point=((px, py),))`
|
||||||
|
|
||||||
As mentioned above, the focal length and principal point are used to convert a point `(X, Y, Z)` from view coordinates to NDC coordinates, as follows
|
The camera projection of a 3D point `(X, Y, Z)` in view coordinates to a point `(x, y, z)` in projection space (either NDC or screen) is
|
||||||
|
|
||||||
```
|
```
|
||||||
# for perspective
|
# for perspective camera
|
||||||
x_ndc = fx * X / Z + px
|
x = fx * X / Z + px
|
||||||
y_ndc = fy * Y / Z + py
|
y = fy * Y / Z + py
|
||||||
z_ndc = 1 / Z
|
z = 1 / Z
|
||||||
|
|
||||||
# for orthographic
|
# for orthographic camera
|
||||||
x_ndc = fx * X + px
|
x = fx * X + px
|
||||||
y_ndc = fy * Y + py
|
y = fy * Y + py
|
||||||
z_ndc = Z
|
z = Z
|
||||||
```
|
```
|
||||||
|
|
||||||
Commonly, users have access to the focal length (`fx_screen`, `fy_screen`) and the principal point (`px_screen`, `py_screen`) in screen space. In that case, to construct the camera the user needs to additionally provide the `image_size = ((image_width, image_height),)`. More precisely, `camera = PerspectiveCameras(focal_length=((fx_screen, fy_screen),), principal_point=((px_screen, py_screen),), image_size = ((image_width, image_height),))`. Internally, the camera parameters are converted from screen to NDC as follows:
|
The user can define the camera parameters in NDC or in screen space. Screen space camera parameters are common and for that case the user needs to set `in_ndc` to `False` and also provide the `image_size=(height, width)` of the screen, aka the image.
|
||||||
|
|
||||||
|
The `get_ndc_camera_transform` provides the transform from screen to NDC space in PyTorch3D. Note that the screen space assumes that the principal point is provided in the space with `+X left`, `+Y down` and origin at the top left corner of the image. To convert to NDC we need to account for the scaling of the normalized space as well as the change in `XY` direction.
|
||||||
|
|
||||||
|
Below are example of equivalent `PerspectiveCameras` instantiations in NDC and screen space, respectively.
|
||||||
|
|
||||||
|
```python
|
||||||
|
# NDC space camera
|
||||||
|
fcl_ndc = (1.2,)
|
||||||
|
prp_ndc = ((0.2, 0.5),)
|
||||||
|
cameras_ndc = PerspectiveCameras(focal_length=fcl_ndc, principal_point=prp_ndc)
|
||||||
|
|
||||||
|
# Screen space camera
|
||||||
|
image_size = ((128, 256),) # (h, w)
|
||||||
|
fcl_screen = (76.8,) # fcl_ndc * min(image_size) / 2
|
||||||
|
prp_screen = ((115.2, 48), ) # w / 2 - px_ndc * min(image_size) / 2, h / 2 - py_ndc * min(image_size) / 2
|
||||||
|
cameras_screen = PerspectiveCameras(focal_length=fcl_screen, principal_point=prp_screen, in_ndc=False, image_size=image_size)
|
||||||
|
```
|
||||||
|
|
||||||
|
The relationship between screen and NDC specifications of a camera's `focal_length` and `principal_point` is given by the following equations, where `s = min(image_width, image_height)`.
|
||||||
|
The transformation of x and y coordinates between screen and NDC is exactly the same as for px and py.
|
||||||
|
|
||||||
```
|
```
|
||||||
fx = fx_screen * 2.0 / image_width
|
fx_ndc = fx_screen * 2.0 / s
|
||||||
fy = fy_screen * 2.0 / image_height
|
fy_ndc = fy_screen * 2.0 / s
|
||||||
|
|
||||||
px = - (px_screen - image_width / 2.0) * 2.0 / image_width
|
px_ndc = - (px_screen - image_width / 2.0) * 2.0 / s
|
||||||
py = - (py_screen - image_height / 2.0) * 2.0/ image_height
|
py_ndc = - (py_screen - image_height / 2.0) * 2.0 / s
|
||||||
```
|
```
|
||||||
|
|||||||
@@ -5,7 +5,7 @@ sidebar_label: Cubify
|
|||||||
|
|
||||||
# Cubify
|
# Cubify
|
||||||
|
|
||||||
The [cubify operator](https://github.com/facebookresearch/pytorch3d/blob/master/pytorch3d/ops/cubify.py) converts an 3D occupancy grid of shape `BxDxHxW`, where `B` is the batch size, into a mesh instantiated as a [Meshes](https://github.com/facebookresearch/pytorch3d/blob/master/pytorch3d/structures/meshes.py) data structure of `B` elements. The operator replaces every occupied voxel (if its occupancy probability is greater than a user defined threshold) with a cuboid of 12 faces and 8 vertices. Shared vertices are merged, and internal faces are removed resulting in a **watertight** mesh.
|
The [cubify operator](https://github.com/facebookresearch/pytorch3d/blob/main/pytorch3d/ops/cubify.py) converts an 3D occupancy grid of shape `BxDxHxW`, where `B` is the batch size, into a mesh instantiated as a [Meshes](https://github.com/facebookresearch/pytorch3d/blob/main/pytorch3d/structures/meshes.py) data structure of `B` elements. The operator replaces every occupied voxel (if its occupancy probability is greater than a user defined threshold) with a cuboid of 12 faces and 8 vertices. Shared vertices are merged, and internal faces are removed resulting in a **watertight** mesh.
|
||||||
|
|
||||||
The operator provides three alignment modes {*topleft*, *corner*, *center*} which define the span of the mesh vertices with respect to the voxel grid. The alignment modes are described in the figure below for a 2D grid.
|
The operator provides three alignment modes {*topleft*, *corner*, *center*} which define the span of the mesh vertices with respect to the voxel grid. The alignment modes are described in the figure below for a 2D grid.
|
||||||
|
|
||||||
|
|||||||
@@ -9,12 +9,12 @@ sidebar_label: Data loaders
|
|||||||
|
|
||||||
ShapeNet is a dataset of 3D CAD models. ShapeNetCore is a subset of the ShapeNet dataset and can be downloaded from https://www.shapenet.org/. There are two versions ShapeNetCore: v1 (55 categories) and v2 (57 categories).
|
ShapeNet is a dataset of 3D CAD models. ShapeNetCore is a subset of the ShapeNet dataset and can be downloaded from https://www.shapenet.org/. There are two versions ShapeNetCore: v1 (55 categories) and v2 (57 categories).
|
||||||
|
|
||||||
The PyTorch3D [ShapeNetCore data loader](https://github.com/facebookresearch/pytorch3d/blob/master/pytorch3d/datasets/shapenet/shapenet_core.py) inherits from `torch.utils.data.Dataset`. It takes the path where the ShapeNetCore dataset is stored locally and loads models in the dataset. The ShapeNetCore class loads and returns models with their `categories`, `model_ids`, `vertices` and `faces`. The `ShapeNetCore` data loader also has a customized `render` function that renders models by the specified `model_ids (List[int])`, `categories (List[str])` or `indices (List[int])` with PyTorch3D's differentiable renderer.
|
The PyTorch3D [ShapeNetCore data loader](https://github.com/facebookresearch/pytorch3d/blob/main/pytorch3d/datasets/shapenet/shapenet_core.py) inherits from `torch.utils.data.Dataset`. It takes the path where the ShapeNetCore dataset is stored locally and loads models in the dataset. The ShapeNetCore class loads and returns models with their `categories`, `model_ids`, `vertices` and `faces`. The `ShapeNetCore` data loader also has a customized `render` function that renders models by the specified `model_ids (List[int])`, `categories (List[str])` or `indices (List[int])` with PyTorch3D's differentiable renderer.
|
||||||
|
|
||||||
The loaded dataset can be passed to `torch.utils.data.DataLoader` with PyTorch3D's customized collate_fn: `collate_batched_meshes` from the `pytorch3d.dataset.utils` module. The `vertices` and `faces` of the models are used to construct a [Meshes](https://github.com/facebookresearch/pytorch3d/blob/master/pytorch3d/structures/meshes.py) object representing the batched meshes. This `Meshes` representation can be easily used with other ops and rendering in PyTorch3D.
|
The loaded dataset can be passed to `torch.utils.data.DataLoader` with PyTorch3D's customized collate_fn: `collate_batched_meshes` from the `pytorch3d.dataset.utils` module. The `vertices` and `faces` of the models are used to construct a [Meshes](https://github.com/facebookresearch/pytorch3d/blob/main/pytorch3d/structures/meshes.py) object representing the batched meshes. This `Meshes` representation can be easily used with other ops and rendering in PyTorch3D.
|
||||||
|
|
||||||
### R2N2
|
### R2N2
|
||||||
|
|
||||||
The R2N2 dataset contains 13 categories that are a subset of the ShapeNetCore v.1 dataset. The R2N2 dataset also contains its own 24 renderings of each object and voxelized models. The R2N2 Dataset can be downloaded following the instructions [here](http://3d-r2n2.stanford.edu/).
|
The R2N2 dataset contains 13 categories that are a subset of the ShapeNetCore v.1 dataset. The R2N2 dataset also contains its own 24 renderings of each object and voxelized models. The R2N2 Dataset can be downloaded following the instructions [here](http://3d-r2n2.stanford.edu/).
|
||||||
|
|
||||||
The PyTorch3D [R2N2 data loader](https://github.com/facebookresearch/pytorch3d/blob/master/pytorch3d/datasets/r2n2/r2n2.py) is initialized with the paths to the ShapeNet dataset, the R2N2 dataset and the splits file for R2N2. Just like `ShapeNetCore`, it can be passed to `torch.utils.data.DataLoader` with a customized collate_fn: `collate_batched_R2N2` from the `pytorch3d.dataset.r2n2.utils` module. It returns all the data that `ShapeNetCore` returns, and in addition, it returns the R2N2 renderings (24 views for each model) along with the camera calibration matrices and a voxel representation for each model. Similar to `ShapeNetCore`, it has a customized `render` function that supports rendering specified models with the PyTorch3D differentiable renderer. In addition, it supports rendering models with the same orientations as R2N2's original renderings.
|
The PyTorch3D [R2N2 data loader](https://github.com/facebookresearch/pytorch3d/blob/main/pytorch3d/datasets/r2n2/r2n2.py) is initialized with the paths to the ShapeNet dataset, the R2N2 dataset and the splits file for R2N2. Just like `ShapeNetCore`, it can be passed to `torch.utils.data.DataLoader` with a customized collate_fn: `collate_batched_R2N2` from the `pytorch3d.dataset.r2n2.utils` module. It returns all the data that `ShapeNetCore` returns, and in addition, it returns the R2N2 renderings (24 views for each model) along with the camera calibration matrices and a voxel representation for each model. Similar to `ShapeNetCore`, it has a customized `render` function that supports rendering specified models with the PyTorch3D differentiable renderer. In addition, it supports rendering models with the same orientations as R2N2's original renderings.
|
||||||
|
|||||||
34
docs/notes/io.md
Normal file
34
docs/notes/io.md
Normal file
@@ -0,0 +1,34 @@
|
|||||||
|
---
|
||||||
|
hide_title: true
|
||||||
|
sidebar_label: File IO
|
||||||
|
---
|
||||||
|
|
||||||
|
# File IO
|
||||||
|
There is a flexible interface for loading and saving point clouds and meshes from different formats.
|
||||||
|
|
||||||
|
The main usage is via the `pytorch3d.io.IO` object, and its methods
|
||||||
|
`load_mesh`, `save_mesh`, `load_point_cloud` and `save_point_cloud`.
|
||||||
|
|
||||||
|
For example, to load a mesh you might do
|
||||||
|
```
|
||||||
|
from pytorch3d.io import IO
|
||||||
|
|
||||||
|
device=torch.device("cuda:0")
|
||||||
|
mesh = IO().load_mesh("mymesh.ply", device=device)
|
||||||
|
```
|
||||||
|
|
||||||
|
and to save a pointcloud you might do
|
||||||
|
```
|
||||||
|
pcl = Pointclouds(...)
|
||||||
|
IO().save_point_cloud(pcl, "output_pointcloud.obj")
|
||||||
|
```
|
||||||
|
|
||||||
|
For meshes, this supports OBJ, PLY and OFF files.
|
||||||
|
|
||||||
|
For pointclouds, this supports PLY files.
|
||||||
|
|
||||||
|
In addition, there is experimental support for loading meshes from
|
||||||
|
[glTF 2 assets](https://github.com/KhronosGroup/glTF/tree/master/specification/2.0)
|
||||||
|
stored either in a GLB container file or a glTF JSON file with embedded binary data.
|
||||||
|
This must be enabled explicitly, as described in
|
||||||
|
`pytorch3d/io/experimental_gltf_io.ply`.
|
||||||
93
docs/notes/iou3d.md
Normal file
93
docs/notes/iou3d.md
Normal file
@@ -0,0 +1,93 @@
|
|||||||
|
---
|
||||||
|
hide_title: true
|
||||||
|
sidebar_label: IoU3D
|
||||||
|
---
|
||||||
|
|
||||||
|
# Intersection Over Union of Oriented 3D Boxes: A New Algorithm
|
||||||
|
|
||||||
|
Author: Georgia Gkioxari
|
||||||
|
|
||||||
|
Implementation: Georgia Gkioxari and Nikhila Ravi
|
||||||
|
|
||||||
|
## Description
|
||||||
|
|
||||||
|
Intersection over union (IoU) of boxes is widely used as an evaluation metric in object detection ([1][pascalvoc], [2][coco]).
|
||||||
|
In 2D, IoU is commonly applied to axis-aligned boxes, namely boxes with edges parallel to the image axis.
|
||||||
|
In 3D, boxes are usually not axis aligned and can be oriented in any way in the world.
|
||||||
|
We introduce a new algorithm which computes the *exact* IoU of two *oriented 3D boxes*.
|
||||||
|
|
||||||
|
Our algorithm is based on the simple observation that the intersection of two oriented 3D boxes, `box1` and `box2`, is a convex polyhedron (convex n-gon in 2D) with `n > 2` comprised of connected *planar units*.
|
||||||
|
In 3D, these planar units are 3D triangular faces.
|
||||||
|
In 2D, they are 2D edges.
|
||||||
|
Each planar unit belongs strictly to either `box1` or `box2`.
|
||||||
|
Our algorithm finds these units by iterating through the sides of each box.
|
||||||
|
|
||||||
|
1. For each 3D triangular face `e` in `box1` we check wether `e` is *inside* `box2`.
|
||||||
|
2. If `e` is not *inside*, then we discard it.
|
||||||
|
3. If `e` is *inside* or *partially inside*, then the part of `e` *inside* `box2` is added to the units that comprise the final intersection shape.
|
||||||
|
4. We repeat for `box2`.
|
||||||
|
|
||||||
|
Below, we show a visualization of our algorithm for the case of 2D oriented boxes.
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<img src="assets/iou3d.gif" alt="drawing" width="400"/>
|
||||||
|
</p>
|
||||||
|
|
||||||
|
Note that when a box's unit `e` is *partially inside* a `box` then `e` breaks into smaller units. In 2D, `e` is an edge and breaks into smaller edges. In 3D, `e` is a 3D triangular face and is clipped to more and smaller faces by the plane of the `box` it intersects with.
|
||||||
|
This is the sole fundamental difference between the algorithms for 2D and 3D.
|
||||||
|
|
||||||
|
## Comparison With Other Algorithms
|
||||||
|
|
||||||
|
Current algorithms for 3D box IoU rely on crude approximations or make box assumptions, for example they restrict the orientation of the 3D boxes.
|
||||||
|
[Objectron][objectron] provides a nice discussion on the limitations of prior works.
|
||||||
|
[Objectron][objectron] introduces a great algorithm for exact IoU computation of oriented 3D boxes.
|
||||||
|
Objectron's algorithm computes the intersection points of two boxes using the [Sutherland-Hodgman algorithm][clipalgo].
|
||||||
|
The intersection shape is formed by the convex hull from the intersection points, using the [Qhull library][qhull].
|
||||||
|
|
||||||
|
Our algorithm has several advantages over Objectron's:
|
||||||
|
|
||||||
|
* Our algorithm also computes the points of intersection, similar to Objectron, but in addition stores the *planar units* the points belong to. This eliminates the need for convex hull computation which is `O(nlogn)` and relies on a third party library which often crashes with nondescript error messages.
|
||||||
|
* Objectron's implementation assumes that boxes are a rotation away from axis aligned. Our algorithm and implementation make no such assumption and work for any 3D boxes.
|
||||||
|
* Our implementation supports batching, unlike Objectron which assumes single element inputs for `box1` and `box2`.
|
||||||
|
* Our implementation is easily parallelizable and in fact we provide a custom C++/CUDA implementation which is **450 times faster than Objectron**.
|
||||||
|
|
||||||
|
Below we compare the performance for Objectron (in C++) and our algorithm, in C++ and CUDA. We benchmark for a common use case in object detection where `boxes1` hold M predictions and `boxes2` hold N ground truth 3D boxes in an image and compute the `MxN` IoU matrix. We report the time in ms for `M=N=16`.
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<img src="assets/iou3d_comp.png" alt="drawing" width="400"/>
|
||||||
|
</p>
|
||||||
|
|
||||||
|
## Usage and Code
|
||||||
|
|
||||||
|
```python
|
||||||
|
from pytorch3d.ops import box3d_overlap
|
||||||
|
# Assume inputs: boxes1 (M, 8, 3) and boxes2 (N, 8, 3)
|
||||||
|
intersection_vol, iou_3d = box3d_overal(boxes1, boxes2)
|
||||||
|
```
|
||||||
|
|
||||||
|
For more details, read [iou_box3d.py](https://github.com/facebookresearch/pytorch3d/blob/main/pytorch3d/ops/iou_box3d.py).
|
||||||
|
|
||||||
|
Note that our implementation is not differentiable as of now. We plan to add gradient support soon.
|
||||||
|
|
||||||
|
We also include have extensive [tests](https://github.com/facebookresearch/pytorch3d/blob/main/tests/test_iou_box3d.py) comparing our implementation with Objectron and MeshLab.
|
||||||
|
|
||||||
|
|
||||||
|
## Cite
|
||||||
|
|
||||||
|
If you use our 3D IoU algorithm, please cite PyTorch3D
|
||||||
|
|
||||||
|
```bibtex
|
||||||
|
@article{ravi2020pytorch3d,
|
||||||
|
author = {Nikhila Ravi and Jeremy Reizenstein and David Novotny and Taylor Gordon
|
||||||
|
and Wan-Yen Lo and Justin Johnson and Georgia Gkioxari},
|
||||||
|
title = {Accelerating 3D Deep Learning with PyTorch3D},
|
||||||
|
journal = {arXiv:2007.08501},
|
||||||
|
year = {2020},
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
[pascalvoc]: http://host.robots.ox.ac.uk/pascal/VOC/
|
||||||
|
[coco]: https://cocodataset.org/
|
||||||
|
[objectron]: https://arxiv.org/abs/2012.09988
|
||||||
|
[qhull]: http://www.qhull.org/
|
||||||
|
[clipalgo]: https://en.wikipedia.org/wiki/Sutherland%E2%80%93Hodgman_algorithm
|
||||||
@@ -6,13 +6,13 @@ hide_title: true
|
|||||||
# Meshes and IO
|
# Meshes and IO
|
||||||
|
|
||||||
The Meshes object represents a batch of triangulated meshes, and is central to
|
The Meshes object represents a batch of triangulated meshes, and is central to
|
||||||
much of the functionality of pytorch3d. There is no insistence that each mesh in
|
much of the functionality of PyTorch3D. There is no insistence that each mesh in
|
||||||
the batch has the same number of vertices or faces. When available, it can store
|
the batch has the same number of vertices or faces. When available, it can store
|
||||||
other data which pertains to the mesh, for example face normals, face areas
|
other data which pertains to the mesh, for example face normals, face areas
|
||||||
and textures.
|
and textures.
|
||||||
|
|
||||||
Two common file formats for storing single meshes are ".obj" and ".ply" files,
|
Two common file formats for storing single meshes are ".obj" and ".ply" files,
|
||||||
and pytorch3d has functions for reading these.
|
and PyTorch3D has functions for reading these.
|
||||||
|
|
||||||
## OBJ
|
## OBJ
|
||||||
|
|
||||||
@@ -60,7 +60,7 @@ The `load_objs_as_meshes` function provides this procedure.
|
|||||||
|
|
||||||
## PLY
|
## PLY
|
||||||
|
|
||||||
Ply files are flexible in the way they store additional information, pytorch3d
|
Ply files are flexible in the way they store additional information. PyTorch3D
|
||||||
provides a function just to read the vertices and faces from a ply file.
|
provides a function just to read the vertices and faces from a ply file.
|
||||||
The call
|
The call
|
||||||
```
|
```
|
||||||
|
|||||||
@@ -21,7 +21,7 @@ Our implementation decouples the rasterization and shading steps of rendering. T
|
|||||||
|
|
||||||
## <u>Get started</u>
|
## <u>Get started</u>
|
||||||
|
|
||||||
To learn about more the implementation and start using the renderer refer to [getting started with renderer](renderer_getting_started.md), which also contains the [architecture overview](assets/architecture_overview.png) and [coordinate transformation conventions](assets/transformations_overview.png).
|
To learn about more the implementation and start using the renderer refer to [getting started with renderer](renderer_getting_started.md), which also contains the [architecture overview](assets/architecture_renderer.jpg) and [coordinate transformation conventions](assets/transforms_overview.jpg).
|
||||||
|
|
||||||
## <u>Tech Report</u>
|
## <u>Tech Report</u>
|
||||||
|
|
||||||
|
|||||||
@@ -55,13 +55,26 @@ While we tried to emulate several aspects of OpenGL, there are differences in th
|
|||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
|
### Rasterizing Non Square Images
|
||||||
|
|
||||||
|
To rasterize an image where H != W, you can specify the `image_size` in the `RasterizationSettings` as a tuple of (H, W).
|
||||||
|
|
||||||
|
The aspect ratio needs special consideration. There are two aspect ratios to be aware of:
|
||||||
|
- the aspect ratio of each pixel
|
||||||
|
- the aspect ratio of the output image
|
||||||
|
In the cameras e.g. `FoVPerspectiveCameras`, the `aspect_ratio` argument can be used to set the pixel aspect ratio. In the rasterizer, we assume square pixels, but variable image aspect ratio (i.e rectangle images).
|
||||||
|
|
||||||
|
In most cases you will want to set the camera aspect ratio to 1.0 (i.e. square pixels) and only vary the `image_size` in the `RasterizationSettings`(i.e. the output image dimensions in pixels).
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
### The pulsar backend
|
### The pulsar backend
|
||||||
|
|
||||||
Since v0.3, [pulsar](https://arxiv.org/abs/2004.07484) can be used as a backend for point-rendering. It has a focus on efficiency, which comes with pros and cons: it is highly optimized and all rendering stages are integrated in the CUDA kernels. This leads to significantly higher speed and better scaling behavior. We use it at Facebook Reality Labs to render and optimize scenes with millions of spheres in resolutions up to 4K. You can find a runtime comparison plot below (settings: `bin_size=None`, `points_per_pixel=5`, `image_size=1024`, `radius=1e-2`, `composite_params.radius=1e-4`; benchmarked on an RTX 2070 GPU).
|
Since v0.3, [pulsar](https://arxiv.org/abs/2004.07484) can be used as a backend for point-rendering. It has a focus on efficiency, which comes with pros and cons: it is highly optimized and all rendering stages are integrated in the CUDA kernels. This leads to significantly higher speed and better scaling behavior. We use it at Facebook Reality Labs to render and optimize scenes with millions of spheres in resolutions up to 4K. You can find a runtime comparison plot below (settings: `bin_size=None`, `points_per_pixel=5`, `image_size=1024`, `radius=1e-2`, `composite_params.radius=1e-4`; benchmarked on an RTX 2070 GPU).
|
||||||
|
|
||||||
<img align="center" src="assets/pulsar_bm.png" width="300">
|
<img align="center" src="assets/pulsar_bm.png" width="300">
|
||||||
|
|
||||||
Pulsar's processing steps are tightly integrated CUDA kernels and do not work with custom `rasterizer` and `compositor` components. We provide two ways to use Pulsar: (1) there is a unified interface to match the PyTorch3D calling convention seamlessly. This is, for example, illustrated in the [point cloud tutorial](https://github.com/facebookresearch/pytorch3d/blob/master/docs/tutorials/render_colored_points.ipynb). (2) There is a direct interface available to the pulsar backend, which exposes the full functionality of the backend (including opacity, which is not yet available in PyTorch3D). Examples showing its use as well as the matching PyTorch3D interface code are available in [this folder](https://github.com/facebookresearch/pytorch3d/tree/master/docs/examples).
|
Pulsar's processing steps are tightly integrated CUDA kernels and do not work with custom `rasterizer` and `compositor` components. We provide two ways to use Pulsar: (1) there is a unified interface to match the PyTorch3D calling convention seamlessly. This is, for example, illustrated in the [point cloud tutorial](https://github.com/facebookresearch/pytorch3d/blob/main/docs/tutorials/render_colored_points.ipynb). (2) There is a direct interface available to the pulsar backend, which exposes the full functionality of the backend (including opacity, which is not yet available in PyTorch3D). Examples showing its use as well as the matching PyTorch3D interface code are available in [this folder](https://github.com/facebookresearch/pytorch3d/tree/master/docs/examples).
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
@@ -71,10 +84,13 @@ For mesh texturing we offer several options (in `pytorch3d/renderer/mesh/texturi
|
|||||||
|
|
||||||
1. **Vertex Textures**: D dimensional textures for each vertex (for example an RGB color) which can be interpolated across the face. This can be represented as an `(N, V, D)` tensor. This is a fairly simple representation though and cannot model complex textures if the mesh faces are large.
|
1. **Vertex Textures**: D dimensional textures for each vertex (for example an RGB color) which can be interpolated across the face. This can be represented as an `(N, V, D)` tensor. This is a fairly simple representation though and cannot model complex textures if the mesh faces are large.
|
||||||
2. **UV Textures**: vertex UV coordinates and **one** texture map for the whole mesh. For a point on a face with given barycentric coordinates, the face color can be computed by interpolating the vertex uv coordinates and then sampling from the texture map. This representation requires two tensors (UVs: `(N, V, 2), Texture map: `(N, H, W, 3)`), and is limited to only support one texture map per mesh.
|
2. **UV Textures**: vertex UV coordinates and **one** texture map for the whole mesh. For a point on a face with given barycentric coordinates, the face color can be computed by interpolating the vertex uv coordinates and then sampling from the texture map. This representation requires two tensors (UVs: `(N, V, 2), Texture map: `(N, H, W, 3)`), and is limited to only support one texture map per mesh.
|
||||||
3. **Face Textures**: In more complex cases such as ShapeNet meshes, there are multiple texture maps per mesh and some faces have texture while other do not. For these cases, a more flexible representation is a texture atlas, where each face is represented as an `(RxR)` texture map where R is the texture resolution. For a given point on the face, the texture value can be sampled from the per face texture map using the barycentric coordinates of the point. This representation requires one tensor of shape `(N, F, R, R, 3)`. This texturing method is inspired by the SoftRasterizer implementation. For more details refer to the [`make_material_atlas`](https://github.com/facebookresearch/pytorch3d/blob/master/pytorch3d/io/mtl_io.py#L123) and [`sample_textures`](https://github.com/facebookresearch/pytorch3d/blob/master/pytorch3d/renderer/mesh/textures.py#L452) functions.
|
3. **Face Textures**: In more complex cases such as ShapeNet meshes, there are multiple texture maps per mesh and some faces have texture while other do not. For these cases, a more flexible representation is a texture atlas, where each face is represented as an `(RxR)` texture map where R is the texture resolution. For a given point on the face, the texture value can be sampled from the per face texture map using the barycentric coordinates of the point. This representation requires one tensor of shape `(N, F, R, R, 3)`. This texturing method is inspired by the SoftRasterizer implementation. For more details refer to the [`make_material_atlas`](https://github.com/facebookresearch/pytorch3d/blob/main/pytorch3d/io/mtl_io.py#L123) and [`sample_textures`](https://github.com/facebookresearch/pytorch3d/blob/main/pytorch3d/renderer/mesh/textures.py#L452) functions. **NOTE:**: The `TexturesAtlas` texture sampling is only differentiable with respect to the texture atlas but not differentiable with respect to the barycentric coordinates.
|
||||||
|
|
||||||
|
|
||||||
<img src="assets/texturing.jpg" width="1000">
|
<img src="assets/texturing.jpg" width="1000">
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
### A simple renderer
|
### A simple renderer
|
||||||
|
|
||||||
A renderer in PyTorch3D is composed of a **rasterizer** and a **shader**. Create a renderer in a few simple steps:
|
A renderer in PyTorch3D is composed of a **rasterizer** and a **shader**. Create a renderer in a few simple steps:
|
||||||
@@ -100,7 +116,7 @@ raster_settings = RasterizationSettings(
|
|||||||
faces_per_pixel=1,
|
faces_per_pixel=1,
|
||||||
)
|
)
|
||||||
|
|
||||||
# Create a phong renderer by composing a rasterizer and a shader. Here we can use a predefined
|
# Create a Phong renderer by composing a rasterizer and a shader. Here we can use a predefined
|
||||||
# PhongShader, passing in the device on which to initialize the default parameters
|
# PhongShader, passing in the device on which to initialize the default parameters
|
||||||
renderer = MeshRenderer(
|
renderer = MeshRenderer(
|
||||||
rasterizer=MeshRasterizer(cameras=cameras, raster_settings=raster_settings),
|
rasterizer=MeshRasterizer(cameras=cameras, raster_settings=raster_settings),
|
||||||
@@ -108,6 +124,8 @@ renderer = MeshRenderer(
|
|||||||
)
|
)
|
||||||
```
|
```
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
### A custom shader
|
### A custom shader
|
||||||
|
|
||||||
Shaders are the most flexible part of the PyTorch3D rendering API. We have created some examples of shaders in `shaders.py` but this is a non exhaustive set.
|
Shaders are the most flexible part of the PyTorch3D rendering API. We have created some examples of shaders in `shaders.py` but this is a non exhaustive set.
|
||||||
|
|||||||
@@ -5,12 +5,12 @@ sidebar_label: Plotly Visualization
|
|||||||
|
|
||||||
# Overview
|
# Overview
|
||||||
|
|
||||||
PyTorch3D provides a modular differentiable renderer, but for instances where we want interactive plots or are not concerned with the differentiability of the rendering process, we provide [functions to render meshes and pointclouds in plotly](../../pytorch3d/vis/plotly_vis.py). These plotly figures allow you to rotate and zoom the rendered images and support plotting batched data as multiple traces in a singular plot or divided into individual subplots.
|
PyTorch3D provides a modular differentiable renderer, but for instances where we want interactive plots or are not concerned with the differentiability of the rendering process, we provide [functions to render meshes and pointclouds in plotly](https://github.com/facebookresearch/pytorch3d/blob/main/pytorch3d/vis/plotly_vis.py). These plotly figures allow you to rotate and zoom the rendered images and support plotting batched data as multiple traces in a singular plot or divided into individual subplots.
|
||||||
|
|
||||||
|
|
||||||
# Examples
|
# Examples
|
||||||
|
|
||||||
These rendering functions accept plotly x,y, and z axis arguments as `kwargs`, allowing us to customize the plots. Here are two plots with colored axes, a [Pointclouds plot](assets/plotly_pointclouds.png), a [batched Meshes plot in subplots](assets/plotly_meshes_batch.png), and a [batched Meshes plot with multiple traces](assets/plotly_meshes_trace.png). Refer to the [render textured meshes](../tutorials/render_textured_meshes.ipynb) and [render colored pointclouds](../tutorials/render_colored_points) tutorials for code examples.
|
These rendering functions accept plotly x,y, and z axis arguments as `kwargs`, allowing us to customize the plots. Here are two plots with colored axes, a [Pointclouds plot](assets/plotly_pointclouds.png), a [batched Meshes plot in subplots](assets/plotly_meshes_batch.png), and a [batched Meshes plot with multiple traces](assets/plotly_meshes_trace.png). Refer to the [render textured meshes](https://pytorch3d.org/tutorials/render_textured_meshes) and [render colored pointclouds](https://pytorch3d.org/tutorials/render_colored_points) tutorials for code examples.
|
||||||
|
|
||||||
# Saving plots to images
|
# Saving plots to images
|
||||||
|
|
||||||
|
|||||||
@@ -10,4 +10,3 @@ sidebar_label: Why PyTorch3D
|
|||||||
Our goal with PyTorch3D is to help accelerate research at the intersection of deep learning and 3D. 3D data is more complex than 2D images and while working on projects such as [Mesh R-CNN](https://github.com/facebookresearch/meshrcnn) and [C3DPO](https://github.com/facebookresearch/c3dpo_nrsfm), we encountered several challenges including 3D data representation, batching, and speed. We have developed many useful operators and abstractions for working on 3D deep learning and want to share this with the community to drive novel research in this area.
|
Our goal with PyTorch3D is to help accelerate research at the intersection of deep learning and 3D. 3D data is more complex than 2D images and while working on projects such as [Mesh R-CNN](https://github.com/facebookresearch/meshrcnn) and [C3DPO](https://github.com/facebookresearch/c3dpo_nrsfm), we encountered several challenges including 3D data representation, batching, and speed. We have developed many useful operators and abstractions for working on 3D deep learning and want to share this with the community to drive novel research in this area.
|
||||||
|
|
||||||
In PyTorch3D we have included efficient 3D operators, heterogeneous batching capabilities, and a modular differentiable rendering API, to equip researchers in this field with a much needed toolkit to implement cutting-edge research with complex 3D inputs.
|
In PyTorch3D we have included efficient 3D operators, heterogeneous batching capabilities, and a modular differentiable rendering API, to equip researchers in this field with a much needed toolkit to implement cutting-edge research with complex 3D inputs.
|
||||||
|
|
||||||
|
|||||||
@@ -6,5 +6,6 @@ sphinx_markdown_tables
|
|||||||
mock
|
mock
|
||||||
numpy
|
numpy
|
||||||
git+git://github.com/facebookresearch/fvcore.git
|
git+git://github.com/facebookresearch/fvcore.git
|
||||||
https://download.pytorch.org/whl/nightly/cpu/torch-1.3.0.dev20191010%2Bcpu-cp37-cp37m-linux_x86_64.whl
|
git+git://github.com/facebookresearch/iopath.git
|
||||||
https://download.pytorch.org/whl/nightly/cpu/torchvision-0.5.0.dev20191008%2Bcpu-cp37-cp37m-linux_x86_64.whl
|
https://download.pytorch.org/whl/cpu/torchvision-0.8.2%2Bcpu-cp37-cp37m-linux_x86_64.whl
|
||||||
|
https://download.pytorch.org/whl/cpu/torch-1.7.1%2Bcpu-cp37-cp37m-linux_x86_64.whl
|
||||||
|
|||||||
@@ -6,9 +6,8 @@ https://github.com/facebookresearch/pytorch3d/tree/stable/docs/tutorials .
|
|||||||
|
|
||||||
There are links at the project homepage for opening these directly in colab.
|
There are links at the project homepage for opening these directly in colab.
|
||||||
|
|
||||||
They install torch, torchvision and PyTorch3D from pip, which should work
|
They install PyTorch3D from pip, which should work inside a GPU colab notebook.
|
||||||
with the CUDA 10.1 inside a GPU colab notebook. If you need to install
|
If you need to install PyTorch3D from source inside colab, you can use
|
||||||
PyTorch3D from source inside colab, you can use
|
|
||||||
```
|
```
|
||||||
import os
|
import os
|
||||||
!curl -LO https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz
|
!curl -LO https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz
|
||||||
|
|||||||
@@ -10,7 +10,7 @@
|
|||||||
},
|
},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved."
|
"# Copyright (c) Meta Platforms, Inc. and affiliates. All rights reserved."
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -36,12 +36,12 @@
|
|||||||
"where $d(g_i, g_j)$ is a suitable metric that compares the extrinsics of cameras $g_i$ and $g_j$. \n",
|
"where $d(g_i, g_j)$ is a suitable metric that compares the extrinsics of cameras $g_i$ and $g_j$. \n",
|
||||||
"\n",
|
"\n",
|
||||||
"Visually, the problem can be described as follows. The picture below depicts the situation at the beginning of our optimization. The ground truth cameras are plotted in purple while the randomly initialized estimated cameras are plotted in orange:\n",
|
"Visually, the problem can be described as follows. The picture below depicts the situation at the beginning of our optimization. The ground truth cameras are plotted in purple while the randomly initialized estimated cameras are plotted in orange:\n",
|
||||||
"\n",
|
"\n",
|
||||||
"\n",
|
"\n",
|
||||||
"Our optimization seeks to align the estimated (orange) cameras with the ground truth (purple) cameras, by minimizing the discrepancies between pairs of relative cameras. Thus, the solution to the problem should look as follows:\n",
|
"Our optimization seeks to align the estimated (orange) cameras with the ground truth (purple) cameras, by minimizing the discrepancies between pairs of relative cameras. Thus, the solution to the problem should look as follows:\n",
|
||||||
"\n",
|
"\n",
|
||||||
"\n",
|
"\n",
|
||||||
"In practice, the camera extrinsics $g_{ij}$ and $g_i$ are represented using objects from the `SfMPerspectiveCameras` class initialized with the corresponding rotation and translation matrices `R_absolute` and `T_absolute` that define the extrinsic parameters $g = (R, T); R \\in SO(3); T \\in \\mathbb{R}^3$. In order to ensure that `R_absolute` is a valid rotation matrix, we represent it using an exponential map (implemented with `so3_exponential_map`) of the axis-angle representation of the rotation `log_R_absolute`.\n",
|
"In practice, the camera extrinsics $g_{ij}$ and $g_i$ are represented using objects from the `SfMPerspectiveCameras` class initialized with the corresponding rotation and translation matrices `R_absolute` and `T_absolute` that define the extrinsic parameters $g = (R, T); R \\in SO(3); T \\in \\mathbb{R}^3$. In order to ensure that `R_absolute` is a valid rotation matrix, we represent it using an exponential map (implemented with `so3_exp_map`) of the axis-angle representation of the rotation `log_R_absolute`.\n",
|
||||||
"\n",
|
"\n",
|
||||||
"Note that the solution to this problem could only be recovered up to an unknown global rigid transformation $g_{glob} \\in SE(3)$. Thus, for simplicity, we assume knowledge of the absolute extrinsics of the first camera $g_0$. We set $g_0$ as a trivial camera $g_0 = (I, \\vec{0})$.\n"
|
"Note that the solution to this problem could only be recovered up to an unknown global rigid transformation $g_{glob} \\in SE(3)$. Thus, for simplicity, we assume knowledge of the absolute extrinsics of the first camera $g_0$. We set $g_0$ as a trivial camera $g_0 = (I, \\vec{0})$.\n"
|
||||||
]
|
]
|
||||||
@@ -63,7 +63,7 @@
|
|||||||
"id": "WAHR1LMJmP-h"
|
"id": "WAHR1LMJmP-h"
|
||||||
},
|
},
|
||||||
"source": [
|
"source": [
|
||||||
"If `torch`, `torchvision` and `pytorch3d` are not installed, run the following cell:"
|
"Ensure `torch` and `torchvision` are installed. If `pytorch3d` is not installed, install it using the following cell:"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -80,19 +80,27 @@
|
|||||||
},
|
},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"!pip install torch torchvision\n",
|
|
||||||
"import os\n",
|
"import os\n",
|
||||||
"import sys\n",
|
"import sys\n",
|
||||||
"import torch\n",
|
"import torch\n",
|
||||||
"if torch.__version__=='1.6.0+cu101' and sys.platform.startswith('linux'):\n",
|
|
||||||
" !pip install pytorch3d\n",
|
|
||||||
"else:\n",
|
|
||||||
"need_pytorch3d=False\n",
|
"need_pytorch3d=False\n",
|
||||||
"try:\n",
|
"try:\n",
|
||||||
" import pytorch3d\n",
|
" import pytorch3d\n",
|
||||||
"except ModuleNotFoundError:\n",
|
"except ModuleNotFoundError:\n",
|
||||||
" need_pytorch3d=True\n",
|
" need_pytorch3d=True\n",
|
||||||
"if need_pytorch3d:\n",
|
"if need_pytorch3d:\n",
|
||||||
|
" if torch.__version__.startswith(\"1.11.\") and sys.platform.startswith(\"linux\"):\n",
|
||||||
|
" # We try to install PyTorch3D via a released wheel.\n",
|
||||||
|
" pyt_version_str=torch.__version__.split(\"+\")[0].replace(\".\", \"\")\n",
|
||||||
|
" version_str=\"\".join([\n",
|
||||||
|
" f\"py3{sys.version_info.minor}_cu\",\n",
|
||||||
|
" torch.version.cuda.replace(\".\",\"\"),\n",
|
||||||
|
" f\"_pyt{pyt_version_str}\"\n",
|
||||||
|
" ])\n",
|
||||||
|
" !pip install fvcore iopath\n",
|
||||||
|
" !pip install --no-index --no-cache-dir pytorch3d -f https://dl.fbaipublicfiles.com/pytorch3d/packaging/wheels/{version_str}/download.html\n",
|
||||||
|
" else:\n",
|
||||||
|
" # We try to install PyTorch3D from source.\n",
|
||||||
" !curl -LO https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz\n",
|
" !curl -LO https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz\n",
|
||||||
" !tar xzf 1.10.0.tar.gz\n",
|
" !tar xzf 1.10.0.tar.gz\n",
|
||||||
" os.environ[\"CUB_HOME\"] = os.getcwd() + \"/cub-1.10.0\"\n",
|
" os.environ[\"CUB_HOME\"] = os.getcwd() + \"/cub-1.10.0\"\n",
|
||||||
@@ -116,7 +124,7 @@
|
|||||||
"# imports\n",
|
"# imports\n",
|
||||||
"import torch\n",
|
"import torch\n",
|
||||||
"from pytorch3d.transforms.so3 import (\n",
|
"from pytorch3d.transforms.so3 import (\n",
|
||||||
" so3_exponential_map,\n",
|
" so3_exp_map,\n",
|
||||||
" so3_relative_angle,\n",
|
" so3_relative_angle,\n",
|
||||||
")\n",
|
")\n",
|
||||||
"from pytorch3d.renderer.cameras import (\n",
|
"from pytorch3d.renderer.cameras import (\n",
|
||||||
@@ -161,11 +169,11 @@
|
|||||||
},
|
},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"!wget https://raw.githubusercontent.com/facebookresearch/pytorch3d/master/docs/tutorials/utils/camera_visualization.py\n",
|
"!wget https://raw.githubusercontent.com/facebookresearch/pytorch3d/main/docs/tutorials/utils/camera_visualization.py\n",
|
||||||
"from camera_visualization import plot_camera_scene\n",
|
"from camera_visualization import plot_camera_scene\n",
|
||||||
"\n",
|
"\n",
|
||||||
"!mkdir data\n",
|
"!mkdir data\n",
|
||||||
"!wget -P data https://raw.githubusercontent.com/facebookresearch/pytorch3d/master/docs/tutorials/data/camera_graph.pth"
|
"!wget -P data https://raw.githubusercontent.com/facebookresearch/pytorch3d/main/docs/tutorials/data/camera_graph.pth"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -322,7 +330,7 @@
|
|||||||
"\n",
|
"\n",
|
||||||
"As mentioned earlier, `log_R_absolute` is the axis angle representation of the rotation part of our absolute cameras. We can obtain the 3x3 rotation matrix `R_absolute` that corresponds to `log_R_absolute` with:\n",
|
"As mentioned earlier, `log_R_absolute` is the axis angle representation of the rotation part of our absolute cameras. We can obtain the 3x3 rotation matrix `R_absolute` that corresponds to `log_R_absolute` with:\n",
|
||||||
"\n",
|
"\n",
|
||||||
"`R_absolute = so3_exponential_map(log_R_absolute)`\n"
|
"`R_absolute = so3_exp_map(log_R_absolute)`\n"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -372,7 +380,7 @@
|
|||||||
" # compute the absolute camera rotations as \n",
|
" # compute the absolute camera rotations as \n",
|
||||||
" # an exponential map of the logarithms (=axis-angles)\n",
|
" # an exponential map of the logarithms (=axis-angles)\n",
|
||||||
" # of the absolute rotations\n",
|
" # of the absolute rotations\n",
|
||||||
" R_absolute = so3_exponential_map(log_R_absolute * camera_mask)\n",
|
" R_absolute = so3_exp_map(log_R_absolute * camera_mask)\n",
|
||||||
"\n",
|
"\n",
|
||||||
" # get the current absolute cameras\n",
|
" # get the current absolute cameras\n",
|
||||||
" cameras_absolute = SfMPerspectiveCameras(\n",
|
" cameras_absolute = SfMPerspectiveCameras(\n",
|
||||||
@@ -381,7 +389,7 @@
|
|||||||
" device = device,\n",
|
" device = device,\n",
|
||||||
" )\n",
|
" )\n",
|
||||||
"\n",
|
"\n",
|
||||||
" # compute the relative cameras as a compositon of the absolute cameras\n",
|
" # compute the relative cameras as a composition of the absolute cameras\n",
|
||||||
" cameras_relative_composed = \\\n",
|
" cameras_relative_composed = \\\n",
|
||||||
" get_relative_camera(cameras_absolute, relative_edges)\n",
|
" get_relative_camera(cameras_absolute, relative_edges)\n",
|
||||||
"\n",
|
"\n",
|
||||||
|
|||||||
@@ -10,7 +10,7 @@
|
|||||||
},
|
},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved."
|
"# Copyright (c) Meta Platforms, Inc. and affiliates. All rights reserved."
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -50,7 +50,7 @@
|
|||||||
"id": "qkX7DiM6rmeM"
|
"id": "qkX7DiM6rmeM"
|
||||||
},
|
},
|
||||||
"source": [
|
"source": [
|
||||||
"If `torch`, `torchvision` and `pytorch3d` are not installed, run the following cell:"
|
"Ensure `torch` and `torchvision` are installed. If `pytorch3d` is not installed, install it using the following cell:"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -67,19 +67,27 @@
|
|||||||
},
|
},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"!pip install torch torchvision\n",
|
|
||||||
"import os\n",
|
"import os\n",
|
||||||
"import sys\n",
|
"import sys\n",
|
||||||
"import torch\n",
|
"import torch\n",
|
||||||
"if torch.__version__=='1.6.0+cu101' and sys.platform.startswith('linux'):\n",
|
|
||||||
" !pip install pytorch3d\n",
|
|
||||||
"else:\n",
|
|
||||||
"need_pytorch3d=False\n",
|
"need_pytorch3d=False\n",
|
||||||
"try:\n",
|
"try:\n",
|
||||||
" import pytorch3d\n",
|
" import pytorch3d\n",
|
||||||
"except ModuleNotFoundError:\n",
|
"except ModuleNotFoundError:\n",
|
||||||
" need_pytorch3d=True\n",
|
" need_pytorch3d=True\n",
|
||||||
"if need_pytorch3d:\n",
|
"if need_pytorch3d:\n",
|
||||||
|
" if torch.__version__.startswith(\"1.11.\") and sys.platform.startswith(\"linux\"):\n",
|
||||||
|
" # We try to install PyTorch3D via a released wheel.\n",
|
||||||
|
" pyt_version_str=torch.__version__.split(\"+\")[0].replace(\".\", \"\")\n",
|
||||||
|
" version_str=\"\".join([\n",
|
||||||
|
" f\"py3{sys.version_info.minor}_cu\",\n",
|
||||||
|
" torch.version.cuda.replace(\".\",\"\"),\n",
|
||||||
|
" f\"_pyt{pyt_version_str}\"\n",
|
||||||
|
" ])\n",
|
||||||
|
" !pip install fvcore iopath\n",
|
||||||
|
" !pip install --no-index --no-cache-dir pytorch3d -f https://dl.fbaipublicfiles.com/pytorch3d/packaging/wheels/{version_str}/download.html\n",
|
||||||
|
" else:\n",
|
||||||
|
" # We try to install PyTorch3D from source.\n",
|
||||||
" !curl -LO https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz\n",
|
" !curl -LO https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz\n",
|
||||||
" !tar xzf 1.10.0.tar.gz\n",
|
" !tar xzf 1.10.0.tar.gz\n",
|
||||||
" os.environ[\"CUB_HOME\"] = os.getcwd() + \"/cub-1.10.0\"\n",
|
" os.environ[\"CUB_HOME\"] = os.getcwd() + \"/cub-1.10.0\"\n",
|
||||||
@@ -217,9 +225,9 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"### Create a renderer\n",
|
"### Create a renderer\n",
|
||||||
"\n",
|
"\n",
|
||||||
"A **renderer** in PyTorch3D is composed of a **rasterizer** and a **shader** which each have a number of subcomponents such as a **camera** (orthgraphic/perspective). Here we initialize some of these components and use default values for the rest. \n",
|
"A **renderer** in PyTorch3D is composed of a **rasterizer** and a **shader** which each have a number of subcomponents such as a **camera** (orthographic/perspective). Here we initialize some of these components and use default values for the rest. \n",
|
||||||
"\n",
|
"\n",
|
||||||
"For optimizing the camera position we will use a renderer which produces a **silhouette** of the object only and does not apply any **lighting** or **shading**. We will also initialize another renderer which applies full **phong shading** and use this for visualizing the outputs. "
|
"For optimizing the camera position we will use a renderer which produces a **silhouette** of the object only and does not apply any **lighting** or **shading**. We will also initialize another renderer which applies full **Phong shading** and use this for visualizing the outputs. "
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -260,7 +268,7 @@
|
|||||||
")\n",
|
")\n",
|
||||||
"\n",
|
"\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# We will also create a phong renderer. This is simpler and only needs to render one face per pixel.\n",
|
"# We will also create a Phong renderer. This is simpler and only needs to render one face per pixel.\n",
|
||||||
"raster_settings = RasterizationSettings(\n",
|
"raster_settings = RasterizationSettings(\n",
|
||||||
" image_size=256, \n",
|
" image_size=256, \n",
|
||||||
" blur_radius=0.0, \n",
|
" blur_radius=0.0, \n",
|
||||||
@@ -316,15 +324,15 @@
|
|||||||
"R, T = look_at_view_transform(distance, elevation, azimuth, device=device)\n",
|
"R, T = look_at_view_transform(distance, elevation, azimuth, device=device)\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# Render the teapot providing the values of R and T. \n",
|
"# Render the teapot providing the values of R and T. \n",
|
||||||
"silhouete = silhouette_renderer(meshes_world=teapot_mesh, R=R, T=T)\n",
|
"silhouette = silhouette_renderer(meshes_world=teapot_mesh, R=R, T=T)\n",
|
||||||
"image_ref = phong_renderer(meshes_world=teapot_mesh, R=R, T=T)\n",
|
"image_ref = phong_renderer(meshes_world=teapot_mesh, R=R, T=T)\n",
|
||||||
"\n",
|
"\n",
|
||||||
"silhouete = silhouete.cpu().numpy()\n",
|
"silhouette = silhouette.cpu().numpy()\n",
|
||||||
"image_ref = image_ref.cpu().numpy()\n",
|
"image_ref = image_ref.cpu().numpy()\n",
|
||||||
"\n",
|
"\n",
|
||||||
"plt.figure(figsize=(10, 10))\n",
|
"plt.figure(figsize=(10, 10))\n",
|
||||||
"plt.subplot(1, 2, 1)\n",
|
"plt.subplot(1, 2, 1)\n",
|
||||||
"plt.imshow(silhouete.squeeze()[..., 3]) # only plot the alpha channel of the RGBA image\n",
|
"plt.imshow(silhouette.squeeze()[..., 3]) # only plot the alpha channel of the RGBA image\n",
|
||||||
"plt.grid(False)\n",
|
"plt.grid(False)\n",
|
||||||
"plt.subplot(1, 2, 2)\n",
|
"plt.subplot(1, 2, 2)\n",
|
||||||
"plt.imshow(image_ref.squeeze())\n",
|
"plt.imshow(image_ref.squeeze())\n",
|
||||||
@@ -371,7 +379,7 @@
|
|||||||
" def forward(self):\n",
|
" def forward(self):\n",
|
||||||
" \n",
|
" \n",
|
||||||
" # Render the image using the updated camera position. Based on the new position of the \n",
|
" # Render the image using the updated camera position. Based on the new position of the \n",
|
||||||
" # camer we calculate the rotation and translation matrices\n",
|
" # camera we calculate the rotation and translation matrices\n",
|
||||||
" R = look_at_rotation(self.camera_position[None, :], device=self.device) # (1, 3, 3)\n",
|
" R = look_at_rotation(self.camera_position[None, :], device=self.device) # (1, 3, 3)\n",
|
||||||
" T = -torch.bmm(R.transpose(1, 2), self.camera_position[None, :, None])[:, :, 0] # (1, 3)\n",
|
" T = -torch.bmm(R.transpose(1, 2), self.camera_position[None, :, None])[:, :, 0] # (1, 3)\n",
|
||||||
" \n",
|
" \n",
|
||||||
@@ -514,7 +522,6 @@
|
|||||||
" plt.figure()\n",
|
" plt.figure()\n",
|
||||||
" plt.imshow(image[..., :3])\n",
|
" plt.imshow(image[..., :3])\n",
|
||||||
" plt.title(\"iter: %d, loss: %0.2f\" % (i, loss.data))\n",
|
" plt.title(\"iter: %d, loss: %0.2f\" % (i, loss.data))\n",
|
||||||
" plt.grid(\"off\")\n",
|
|
||||||
" plt.axis(\"off\")\n",
|
" plt.axis(\"off\")\n",
|
||||||
" \n",
|
" \n",
|
||||||
"writer.close()"
|
"writer.close()"
|
||||||
|
|||||||
@@ -1,4 +1,3 @@
|
|||||||
|
|
||||||
# Acknowledgements
|
# Acknowledgements
|
||||||
|
|
||||||
Thank you to Keenen Crane for allowing the cow mesh model to be used freely in the public domain.
|
Thank you to Keenen Crane for allowing the cow mesh model to be used freely in the public domain.
|
||||||
|
|||||||
@@ -6,7 +6,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved."
|
"# Copyright (c) Meta Platforms, Inc. and affiliates. All rights reserved."
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -33,7 +33,7 @@
|
|||||||
"cell_type": "markdown",
|
"cell_type": "markdown",
|
||||||
"metadata": {},
|
"metadata": {},
|
||||||
"source": [
|
"source": [
|
||||||
"If `torch`, `torchvision` and `pytorch3d` are not installed, run the following cell:"
|
"Ensure `torch` and `torchvision` are installed. If `pytorch3d` is not installed, install it using the following cell:"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -42,19 +42,27 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"!pip install torch torchvision\n",
|
|
||||||
"import os\n",
|
"import os\n",
|
||||||
"import sys\n",
|
"import sys\n",
|
||||||
"import torch\n",
|
"import torch\n",
|
||||||
"if torch.__version__=='1.6.0+cu101' and sys.platform.startswith('linux'):\n",
|
|
||||||
" !pip install pytorch3d\n",
|
|
||||||
"else:\n",
|
|
||||||
"need_pytorch3d=False\n",
|
"need_pytorch3d=False\n",
|
||||||
"try:\n",
|
"try:\n",
|
||||||
" import pytorch3d\n",
|
" import pytorch3d\n",
|
||||||
"except ModuleNotFoundError:\n",
|
"except ModuleNotFoundError:\n",
|
||||||
" need_pytorch3d=True\n",
|
" need_pytorch3d=True\n",
|
||||||
"if need_pytorch3d:\n",
|
"if need_pytorch3d:\n",
|
||||||
|
" if torch.__version__.startswith(\"1.11.\") and sys.platform.startswith(\"linux\"):\n",
|
||||||
|
" # We try to install PyTorch3D via a released wheel.\n",
|
||||||
|
" pyt_version_str=torch.__version__.split(\"+\")[0].replace(\".\", \"\")\n",
|
||||||
|
" version_str=\"\".join([\n",
|
||||||
|
" f\"py3{sys.version_info.minor}_cu\",\n",
|
||||||
|
" torch.version.cuda.replace(\".\",\"\"),\n",
|
||||||
|
" f\"_pyt{pyt_version_str}\"\n",
|
||||||
|
" ])\n",
|
||||||
|
" !pip install fvcore iopath\n",
|
||||||
|
" !pip install --no-index --no-cache-dir pytorch3d -f https://dl.fbaipublicfiles.com/pytorch3d/packaging/wheels/{version_str}/download.html\n",
|
||||||
|
" else:\n",
|
||||||
|
" # We try to install PyTorch3D from source.\n",
|
||||||
" !curl -LO https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz\n",
|
" !curl -LO https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz\n",
|
||||||
" !tar xzf 1.10.0.tar.gz\n",
|
" !tar xzf 1.10.0.tar.gz\n",
|
||||||
" os.environ[\"CUB_HOME\"] = os.getcwd() + \"/cub-1.10.0\"\n",
|
" os.environ[\"CUB_HOME\"] = os.getcwd() + \"/cub-1.10.0\"\n",
|
||||||
@@ -106,7 +114,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"!wget https://raw.githubusercontent.com/facebookresearch/pytorch3d/master/docs/tutorials/utils/plot_image_grid.py\n",
|
"!wget https://raw.githubusercontent.com/facebookresearch/pytorch3d/main/docs/tutorials/utils/plot_image_grid.py\n",
|
||||||
"from plot_image_grid import image_grid"
|
"from plot_image_grid import image_grid"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -184,7 +192,7 @@
|
|||||||
"cell_type": "markdown",
|
"cell_type": "markdown",
|
||||||
"metadata": {},
|
"metadata": {},
|
||||||
"source": [
|
"source": [
|
||||||
"We can retrieve a model by indexing into the loaded dataset. For both ShapeNetCore and R2N2, we can examine the category this model belongs to (in the form of a synset id, equivalend to wnid described in ImageNet's API: http://image-net.org/download-API), its model id, and its vertices and faces."
|
"We can retrieve a model by indexing into the loaded dataset. For both ShapeNetCore and R2N2, we can examine the category this model belongs to (in the form of a synset id, equivalent to wnid described in ImageNet's API: http://image-net.org/download-API), its model id, and its vertices and faces."
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -248,11 +256,11 @@
|
|||||||
"cell_type": "markdown",
|
"cell_type": "markdown",
|
||||||
"metadata": {},
|
"metadata": {},
|
||||||
"source": [
|
"source": [
|
||||||
"Training deep learning models, usually requires passing in batches of inputs. The `torch.utils.data.DataLoader` from Pytorch helps us do this. PyTorch3D provides a function `collate_batched_meshes` to group the input meshes into a single `Meshes` object which represents the batch. The `Meshes` datastructure can then be used directly by other PyTorch3D ops which might be part of the deep learning model (e.g. `graph_conv`).\n",
|
"Training deep learning models, usually requires passing in batches of inputs. The `torch.utils.data.DataLoader` from PyTorch helps us do this. PyTorch3D provides a function `collate_batched_meshes` to group the input meshes into a single `Meshes` object which represents the batch. The `Meshes` datastructure can then be used directly by other PyTorch3D ops which might be part of the deep learning model (e.g. `graph_conv`).\n",
|
||||||
"\n",
|
"\n",
|
||||||
"For R2N2, if all the models in the batch have the same number of views, the views, rotation matrices, translation matrices, intrinsic matrices and voxels will also be stacked into batched tensors.\n",
|
"For R2N2, if all the models in the batch have the same number of views, the views, rotation matrices, translation matrices, intrinsic matrices and voxels will also be stacked into batched tensors.\n",
|
||||||
"\n",
|
"\n",
|
||||||
"**NOTE**: All models in the `val` split of R2N2 have 24 views, but there are 8 models that split their 24 views between `train` and `test` splits, in which case `collate_batched_meshes` will only be able to join the matrices, views and voxels as lists. However, this can be avoided by laoding only one view of each model by setting `return_all_views = False`."
|
"**NOTE**: All models in the `val` split of R2N2 have 24 views, but there are 8 models that split their 24 views between `train` and `test` splits, in which case `collate_batched_meshes` will only be able to join the matrices, views and voxels as lists. However, this can be avoided by loading only one view of each model by setting `return_all_views = False`."
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -289,7 +297,7 @@
|
|||||||
"cell_type": "markdown",
|
"cell_type": "markdown",
|
||||||
"metadata": {},
|
"metadata": {},
|
||||||
"source": [
|
"source": [
|
||||||
"## 3. Render ShapeNetCore models with PyTorch3D's differntiable renderer"
|
"## 3. Render ShapeNetCore models with PyTorch3D's differentiable renderer"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -444,7 +452,7 @@
|
|||||||
"cell_type": "markdown",
|
"cell_type": "markdown",
|
||||||
"metadata": {},
|
"metadata": {},
|
||||||
"source": [
|
"source": [
|
||||||
"Next, we will visualize PyTorch3d's renderings:"
|
"Next, we will visualize PyTorch3D's renderings:"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
|
|||||||
@@ -10,7 +10,7 @@
|
|||||||
},
|
},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved."
|
"# Copyright (c) Meta Platforms, Inc. and affiliates. All rights reserved."
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -68,7 +68,7 @@
|
|||||||
"cell_type": "markdown",
|
"cell_type": "markdown",
|
||||||
"metadata": {},
|
"metadata": {},
|
||||||
"source": [
|
"source": [
|
||||||
"If `torch`, `torchvision` and `pytorch3d` are not installed, run the following cell:"
|
"Ensure `torch` and `torchvision` are installed. If `pytorch3d` is not installed, install it using the following cell:"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -81,19 +81,27 @@
|
|||||||
},
|
},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"!pip install torch torchvision\n",
|
|
||||||
"import os\n",
|
"import os\n",
|
||||||
"import sys\n",
|
"import sys\n",
|
||||||
"import torch\n",
|
"import torch\n",
|
||||||
"if torch.__version__=='1.6.0+cu101' and sys.platform.startswith('linux'):\n",
|
|
||||||
" !pip install pytorch3d\n",
|
|
||||||
"else:\n",
|
|
||||||
"need_pytorch3d=False\n",
|
"need_pytorch3d=False\n",
|
||||||
"try:\n",
|
"try:\n",
|
||||||
" import pytorch3d\n",
|
" import pytorch3d\n",
|
||||||
"except ModuleNotFoundError:\n",
|
"except ModuleNotFoundError:\n",
|
||||||
" need_pytorch3d=True\n",
|
" need_pytorch3d=True\n",
|
||||||
"if need_pytorch3d:\n",
|
"if need_pytorch3d:\n",
|
||||||
|
" if torch.__version__.startswith(\"1.11.\") and sys.platform.startswith(\"linux\"):\n",
|
||||||
|
" # We try to install PyTorch3D via a released wheel.\n",
|
||||||
|
" pyt_version_str=torch.__version__.split(\"+\")[0].replace(\".\", \"\")\n",
|
||||||
|
" version_str=\"\".join([\n",
|
||||||
|
" f\"py3{sys.version_info.minor}_cu\",\n",
|
||||||
|
" torch.version.cuda.replace(\".\",\"\"),\n",
|
||||||
|
" f\"_pyt{pyt_version_str}\"\n",
|
||||||
|
" ])\n",
|
||||||
|
" !pip install fvcore iopath\n",
|
||||||
|
" !pip install --no-index --no-cache-dir pytorch3d -f https://dl.fbaipublicfiles.com/pytorch3d/packaging/wheels/{version_str}/download.html\n",
|
||||||
|
" else:\n",
|
||||||
|
" # We try to install PyTorch3D from source.\n",
|
||||||
" !curl -LO https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz\n",
|
" !curl -LO https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz\n",
|
||||||
" !tar xzf 1.10.0.tar.gz\n",
|
" !tar xzf 1.10.0.tar.gz\n",
|
||||||
" os.environ[\"CUB_HOME\"] = os.getcwd() + \"/cub-1.10.0\"\n",
|
" os.environ[\"CUB_HOME\"] = os.getcwd() + \"/cub-1.10.0\"\n",
|
||||||
@@ -400,10 +408,10 @@
|
|||||||
" loop.set_description('total_loss = %.6f' % loss)\n",
|
" loop.set_description('total_loss = %.6f' % loss)\n",
|
||||||
" \n",
|
" \n",
|
||||||
" # Save the losses for plotting\n",
|
" # Save the losses for plotting\n",
|
||||||
" chamfer_losses.append(loss_chamfer)\n",
|
" chamfer_losses.append(float(loss_chamfer.detach().cpu()))\n",
|
||||||
" edge_losses.append(loss_edge)\n",
|
" edge_losses.append(float(loss_edge.detach().cpu()))\n",
|
||||||
" normal_losses.append(loss_normal)\n",
|
" normal_losses.append(float(loss_normal.detach().cpu()))\n",
|
||||||
" laplacian_losses.append(loss_laplacian)\n",
|
" laplacian_losses.append(float(loss_laplacian.detach().cpu()))\n",
|
||||||
" \n",
|
" \n",
|
||||||
" # Plot mesh\n",
|
" # Plot mesh\n",
|
||||||
" if i % plot_period == 0:\n",
|
" if i % plot_period == 0:\n",
|
||||||
|
|||||||
903
docs/tutorials/fit_simple_neural_radiance_field.ipynb
Normal file
903
docs/tutorials/fit_simple_neural_radiance_field.ipynb
Normal file
@@ -0,0 +1,903 @@
|
|||||||
|
{
|
||||||
|
"cells": [
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# Copyright (c) Meta Platforms, Inc. and affiliates. All rights reserved."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"# Fit a simple Neural Radiance Field via raymarching\n",
|
||||||
|
"\n",
|
||||||
|
"This tutorial shows how to fit Neural Radiance Field given a set of views of a scene using differentiable implicit function rendering.\n",
|
||||||
|
"\n",
|
||||||
|
"More specifically, this tutorial will explain how to:\n",
|
||||||
|
"1. Create a differentiable implicit function renderer with either image-grid or Monte Carlo ray sampling.\n",
|
||||||
|
"2. Create an Implicit model of a scene.\n",
|
||||||
|
"3. Fit the implicit function (Neural Radiance Field) based on input images using the differentiable implicit renderer. \n",
|
||||||
|
"4. Visualize the learnt implicit function.\n",
|
||||||
|
"\n",
|
||||||
|
"Note that the presented implicit model is a simplified version of NeRF:<br>\n",
|
||||||
|
"_Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, Ren Ng: NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis, ECCV 2020._\n",
|
||||||
|
"\n",
|
||||||
|
"The simplifications include:\n",
|
||||||
|
"* *Ray sampling*: This notebook does not perform stratified ray sampling but rather ray sampling at equidistant depths.\n",
|
||||||
|
"* *Rendering*: We do a single rendering pass, as opposed to the original implementation that does a coarse and fine rendering pass.\n",
|
||||||
|
"* *Architecture*: Our network is shallower which allows for faster optimization possibly at the cost of surface details.\n",
|
||||||
|
"* *Mask loss*: Since our observations include segmentation masks, we also optimize a silhouette loss that forces rays to either get fully absorbed inside the volume, or to completely pass through it.\n"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## 0. Install and Import modules\n",
|
||||||
|
"Ensure `torch` and `torchvision` are installed. If `pytorch3d` is not installed, install it using the following cell:"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"import os\n",
|
||||||
|
"import sys\n",
|
||||||
|
"import torch\n",
|
||||||
|
"need_pytorch3d=False\n",
|
||||||
|
"try:\n",
|
||||||
|
" import pytorch3d\n",
|
||||||
|
"except ModuleNotFoundError:\n",
|
||||||
|
" need_pytorch3d=True\n",
|
||||||
|
"if need_pytorch3d:\n",
|
||||||
|
" if torch.__version__.startswith(\"1.11.\") and sys.platform.startswith(\"linux\"):\n",
|
||||||
|
" # We try to install PyTorch3D via a released wheel.\n",
|
||||||
|
" pyt_version_str=torch.__version__.split(\"+\")[0].replace(\".\", \"\")\n",
|
||||||
|
" version_str=\"\".join([\n",
|
||||||
|
" f\"py3{sys.version_info.minor}_cu\",\n",
|
||||||
|
" torch.version.cuda.replace(\".\",\"\"),\n",
|
||||||
|
" f\"_pyt{pyt_version_str}\"\n",
|
||||||
|
" ])\n",
|
||||||
|
" !pip install fvcore iopath\n",
|
||||||
|
" !pip install --no-index --no-cache-dir pytorch3d -f https://dl.fbaipublicfiles.com/pytorch3d/packaging/wheels/{version_str}/download.html\n",
|
||||||
|
" else:\n",
|
||||||
|
" # We try to install PyTorch3D from source.\n",
|
||||||
|
" !curl -LO https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz\n",
|
||||||
|
" !tar xzf 1.10.0.tar.gz\n",
|
||||||
|
" os.environ[\"CUB_HOME\"] = os.getcwd() + \"/cub-1.10.0\"\n",
|
||||||
|
" !pip install 'git+https://github.com/facebookresearch/pytorch3d.git@stable'"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# %matplotlib inline\n",
|
||||||
|
"# %matplotlib notebook\n",
|
||||||
|
"import os\n",
|
||||||
|
"import sys\n",
|
||||||
|
"import time\n",
|
||||||
|
"import json\n",
|
||||||
|
"import glob\n",
|
||||||
|
"import torch\n",
|
||||||
|
"import math\n",
|
||||||
|
"import matplotlib.pyplot as plt\n",
|
||||||
|
"import numpy as np\n",
|
||||||
|
"from PIL import Image\n",
|
||||||
|
"from IPython import display\n",
|
||||||
|
"from tqdm.notebook import tqdm\n",
|
||||||
|
"\n",
|
||||||
|
"# Data structures and functions for rendering\n",
|
||||||
|
"from pytorch3d.structures import Volumes\n",
|
||||||
|
"from pytorch3d.transforms import so3_exp_map\n",
|
||||||
|
"from pytorch3d.renderer import (\n",
|
||||||
|
" FoVPerspectiveCameras, \n",
|
||||||
|
" NDCMultinomialRaysampler,\n",
|
||||||
|
" MonteCarloRaysampler,\n",
|
||||||
|
" EmissionAbsorptionRaymarcher,\n",
|
||||||
|
" ImplicitRenderer,\n",
|
||||||
|
" RayBundle,\n",
|
||||||
|
" ray_bundle_to_ray_points,\n",
|
||||||
|
")\n",
|
||||||
|
"\n",
|
||||||
|
"# obtain the utilized device\n",
|
||||||
|
"if torch.cuda.is_available():\n",
|
||||||
|
" device = torch.device(\"cuda:0\")\n",
|
||||||
|
" torch.cuda.set_device(device)\n",
|
||||||
|
"else:\n",
|
||||||
|
" print(\n",
|
||||||
|
" 'Please note that NeRF is a resource-demanding method.'\n",
|
||||||
|
" + ' Running this notebook on CPU will be extremely slow.'\n",
|
||||||
|
" + ' We recommend running the example on a GPU'\n",
|
||||||
|
" + ' with at least 10 GB of memory.'\n",
|
||||||
|
" )\n",
|
||||||
|
" device = torch.device(\"cpu\")"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"!wget https://raw.githubusercontent.com/facebookresearch/pytorch3d/main/docs/tutorials/utils/plot_image_grid.py\n",
|
||||||
|
"!wget https://raw.githubusercontent.com/facebookresearch/pytorch3d/main/docs/tutorials/utils/generate_cow_renders.py\n",
|
||||||
|
"from plot_image_grid import image_grid\n",
|
||||||
|
"from generate_cow_renders import generate_cow_renders"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"OR if running locally uncomment and run the following cell:"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# from utils.generate_cow_renders import generate_cow_renders\n",
|
||||||
|
"# from utils import image_grid"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## 1. Generate images of the scene and masks\n",
|
||||||
|
"\n",
|
||||||
|
"The following cell generates our training data.\n",
|
||||||
|
"It renders the cow mesh from the `fit_textured_mesh.ipynb` tutorial from several viewpoints and returns:\n",
|
||||||
|
"1. A batch of image and silhouette tensors that are produced by the cow mesh renderer.\n",
|
||||||
|
"2. A set of cameras corresponding to each render.\n",
|
||||||
|
"\n",
|
||||||
|
"Note: For the purpose of this tutorial, which aims at explaining the details of implicit rendering, we do not explain how the mesh rendering, implemented in the `generate_cow_renders` function, works. Please refer to `fit_textured_mesh.ipynb` for a detailed explanation of mesh rendering."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"target_cameras, target_images, target_silhouettes = generate_cow_renders(num_views=40, azimuth_range=180)\n",
|
||||||
|
"print(f'Generated {len(target_images)} images/silhouettes/cameras.')"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## 2. Initialize the implicit renderer\n",
|
||||||
|
"\n",
|
||||||
|
"The following initializes an implicit renderer that emits a ray from each pixel of a target image and samples a set of uniformly-spaced points along the ray. At each ray-point, the corresponding density and color value is obtained by querying the corresponding location in the neural model of the scene (the model is described & instantiated in a later cell).\n",
|
||||||
|
"\n",
|
||||||
|
"The renderer is composed of a *raymarcher* and a *raysampler*.\n",
|
||||||
|
"- The *raysampler* is responsible for emitting rays from image pixels and sampling the points along them. Here, we use two different raysamplers:\n",
|
||||||
|
" - `MonteCarloRaysampler` is used to generate rays from a random subset of pixels of the image plane. The random subsampling of pixels is carried out during **training** to decrease the memory consumption of the implicit model.\n",
|
||||||
|
" - `NDCMultinomialRaysampler` which follows the standard PyTorch3D coordinate grid convention (+X from right to left; +Y from bottom to top; +Z away from the user). In combination with the implicit model of the scene, `NDCMultinomialRaysampler` consumes a large amount of memory and, hence, is only used for visualizing the results of the training at **test** time.\n",
|
||||||
|
"- The *raymarcher* takes the densities and colors sampled along each ray and renders each ray into a color and an opacity value of the ray's source pixel. Here we use the `EmissionAbsorptionRaymarcher` which implements the standard Emission-Absorption raymarching algorithm."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# render_size describes the size of both sides of the \n",
|
||||||
|
"# rendered images in pixels. Since an advantage of \n",
|
||||||
|
"# Neural Radiance Fields are high quality renders\n",
|
||||||
|
"# with a significant amount of details, we render\n",
|
||||||
|
"# the implicit function at double the size of \n",
|
||||||
|
"# target images.\n",
|
||||||
|
"render_size = target_images.shape[1] * 2\n",
|
||||||
|
"\n",
|
||||||
|
"# Our rendered scene is centered around (0,0,0) \n",
|
||||||
|
"# and is enclosed inside a bounding box\n",
|
||||||
|
"# whose side is roughly equal to 3.0 (world units).\n",
|
||||||
|
"volume_extent_world = 3.0\n",
|
||||||
|
"\n",
|
||||||
|
"# 1) Instantiate the raysamplers.\n",
|
||||||
|
"\n",
|
||||||
|
"# Here, NDCMultinomialRaysampler generates a rectangular image\n",
|
||||||
|
"# grid of rays whose coordinates follow the PyTorch3D\n",
|
||||||
|
"# coordinate conventions.\n",
|
||||||
|
"raysampler_grid = NDCMultinomialRaysampler(\n",
|
||||||
|
" image_height=render_size,\n",
|
||||||
|
" image_width=render_size,\n",
|
||||||
|
" n_pts_per_ray=128,\n",
|
||||||
|
" min_depth=0.1,\n",
|
||||||
|
" max_depth=volume_extent_world,\n",
|
||||||
|
")\n",
|
||||||
|
"\n",
|
||||||
|
"# MonteCarloRaysampler generates a random subset \n",
|
||||||
|
"# of `n_rays_per_image` rays emitted from the image plane.\n",
|
||||||
|
"raysampler_mc = MonteCarloRaysampler(\n",
|
||||||
|
" min_x = -1.0,\n",
|
||||||
|
" max_x = 1.0,\n",
|
||||||
|
" min_y = -1.0,\n",
|
||||||
|
" max_y = 1.0,\n",
|
||||||
|
" n_rays_per_image=750,\n",
|
||||||
|
" n_pts_per_ray=128,\n",
|
||||||
|
" min_depth=0.1,\n",
|
||||||
|
" max_depth=volume_extent_world,\n",
|
||||||
|
")\n",
|
||||||
|
"\n",
|
||||||
|
"# 2) Instantiate the raymarcher.\n",
|
||||||
|
"# Here, we use the standard EmissionAbsorptionRaymarcher \n",
|
||||||
|
"# which marches along each ray in order to render\n",
|
||||||
|
"# the ray into a single 3D color vector \n",
|
||||||
|
"# and an opacity scalar.\n",
|
||||||
|
"raymarcher = EmissionAbsorptionRaymarcher()\n",
|
||||||
|
"\n",
|
||||||
|
"# Finally, instantiate the implicit renders\n",
|
||||||
|
"# for both raysamplers.\n",
|
||||||
|
"renderer_grid = ImplicitRenderer(\n",
|
||||||
|
" raysampler=raysampler_grid, raymarcher=raymarcher,\n",
|
||||||
|
")\n",
|
||||||
|
"renderer_mc = ImplicitRenderer(\n",
|
||||||
|
" raysampler=raysampler_mc, raymarcher=raymarcher,\n",
|
||||||
|
")"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## 3. Define the neural radiance field model\n",
|
||||||
|
"\n",
|
||||||
|
"In this cell we define the `NeuralRadianceField` module, which specifies a continuous field of colors and opacities over the 3D domain of the scene.\n",
|
||||||
|
"\n",
|
||||||
|
"The `forward` function of `NeuralRadianceField` (NeRF) receives as input a set of tensors that parametrize a bundle of rendering rays. The ray bundle is later converted to 3D ray points in the world coordinates of the scene. Each 3D point is then mapped to a harmonic representation using the `HarmonicEmbedding` layer (defined in the next cell). The harmonic embeddings then enter the _color_ and _opacity_ branches of the NeRF model in order to label each ray point with a 3D vector and a 1D scalar ranging in [0-1] which define the point's RGB color and opacity respectively.\n",
|
||||||
|
"\n",
|
||||||
|
"Since NeRF has a large memory footprint, we also implement the `NeuralRadianceField.forward_batched` method. The method splits the input rays into batches and executes the `forward` function for each batch separately in a for loop. This lets us render a large set of rays without running out of GPU memory. Standardly, `forward_batched` would be used to render rays emitted from all pixels of an image in order to produce a full-sized render of a scene.\n"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"class HarmonicEmbedding(torch.nn.Module):\n",
|
||||||
|
" def __init__(self, n_harmonic_functions=60, omega0=0.1):\n",
|
||||||
|
" \"\"\"\n",
|
||||||
|
" Given an input tensor `x` of shape [minibatch, ... , dim],\n",
|
||||||
|
" the harmonic embedding layer converts each feature\n",
|
||||||
|
" in `x` into a series of harmonic features `embedding`\n",
|
||||||
|
" as follows:\n",
|
||||||
|
" embedding[..., i*dim:(i+1)*dim] = [\n",
|
||||||
|
" sin(x[..., i]),\n",
|
||||||
|
" sin(2*x[..., i]),\n",
|
||||||
|
" sin(4*x[..., i]),\n",
|
||||||
|
" ...\n",
|
||||||
|
" sin(2**(self.n_harmonic_functions-1) * x[..., i]),\n",
|
||||||
|
" cos(x[..., i]),\n",
|
||||||
|
" cos(2*x[..., i]),\n",
|
||||||
|
" cos(4*x[..., i]),\n",
|
||||||
|
" ...\n",
|
||||||
|
" cos(2**(self.n_harmonic_functions-1) * x[..., i])\n",
|
||||||
|
" ]\n",
|
||||||
|
" \n",
|
||||||
|
" Note that `x` is also premultiplied by `omega0` before\n",
|
||||||
|
" evaluating the harmonic functions.\n",
|
||||||
|
" \"\"\"\n",
|
||||||
|
" super().__init__()\n",
|
||||||
|
" self.register_buffer(\n",
|
||||||
|
" 'frequencies',\n",
|
||||||
|
" omega0 * (2.0 ** torch.arange(n_harmonic_functions)),\n",
|
||||||
|
" )\n",
|
||||||
|
" def forward(self, x):\n",
|
||||||
|
" \"\"\"\n",
|
||||||
|
" Args:\n",
|
||||||
|
" x: tensor of shape [..., dim]\n",
|
||||||
|
" Returns:\n",
|
||||||
|
" embedding: a harmonic embedding of `x`\n",
|
||||||
|
" of shape [..., n_harmonic_functions * dim * 2]\n",
|
||||||
|
" \"\"\"\n",
|
||||||
|
" embed = (x[..., None] * self.frequencies).view(*x.shape[:-1], -1)\n",
|
||||||
|
" return torch.cat((embed.sin(), embed.cos()), dim=-1)\n",
|
||||||
|
"\n",
|
||||||
|
"\n",
|
||||||
|
"class NeuralRadianceField(torch.nn.Module):\n",
|
||||||
|
" def __init__(self, n_harmonic_functions=60, n_hidden_neurons=256):\n",
|
||||||
|
" super().__init__()\n",
|
||||||
|
" \"\"\"\n",
|
||||||
|
" Args:\n",
|
||||||
|
" n_harmonic_functions: The number of harmonic functions\n",
|
||||||
|
" used to form the harmonic embedding of each point.\n",
|
||||||
|
" n_hidden_neurons: The number of hidden units in the\n",
|
||||||
|
" fully connected layers of the MLPs of the model.\n",
|
||||||
|
" \"\"\"\n",
|
||||||
|
" \n",
|
||||||
|
" # The harmonic embedding layer converts input 3D coordinates\n",
|
||||||
|
" # to a representation that is more suitable for\n",
|
||||||
|
" # processing with a deep neural network.\n",
|
||||||
|
" self.harmonic_embedding = HarmonicEmbedding(n_harmonic_functions)\n",
|
||||||
|
" \n",
|
||||||
|
" # The dimension of the harmonic embedding.\n",
|
||||||
|
" embedding_dim = n_harmonic_functions * 2 * 3\n",
|
||||||
|
" \n",
|
||||||
|
" # self.mlp is a simple 2-layer multi-layer perceptron\n",
|
||||||
|
" # which converts the input per-point harmonic embeddings\n",
|
||||||
|
" # to a latent representation.\n",
|
||||||
|
" # Not that we use Softplus activations instead of ReLU.\n",
|
||||||
|
" self.mlp = torch.nn.Sequential(\n",
|
||||||
|
" torch.nn.Linear(embedding_dim, n_hidden_neurons),\n",
|
||||||
|
" torch.nn.Softplus(beta=10.0),\n",
|
||||||
|
" torch.nn.Linear(n_hidden_neurons, n_hidden_neurons),\n",
|
||||||
|
" torch.nn.Softplus(beta=10.0),\n",
|
||||||
|
" ) \n",
|
||||||
|
" \n",
|
||||||
|
" # Given features predicted by self.mlp, self.color_layer\n",
|
||||||
|
" # is responsible for predicting a 3-D per-point vector\n",
|
||||||
|
" # that represents the RGB color of the point.\n",
|
||||||
|
" self.color_layer = torch.nn.Sequential(\n",
|
||||||
|
" torch.nn.Linear(n_hidden_neurons + embedding_dim, n_hidden_neurons),\n",
|
||||||
|
" torch.nn.Softplus(beta=10.0),\n",
|
||||||
|
" torch.nn.Linear(n_hidden_neurons, 3),\n",
|
||||||
|
" torch.nn.Sigmoid(),\n",
|
||||||
|
" # To ensure that the colors correctly range between [0-1],\n",
|
||||||
|
" # the layer is terminated with a sigmoid layer.\n",
|
||||||
|
" ) \n",
|
||||||
|
" \n",
|
||||||
|
" # The density layer converts the features of self.mlp\n",
|
||||||
|
" # to a 1D density value representing the raw opacity\n",
|
||||||
|
" # of each point.\n",
|
||||||
|
" self.density_layer = torch.nn.Sequential(\n",
|
||||||
|
" torch.nn.Linear(n_hidden_neurons, 1),\n",
|
||||||
|
" torch.nn.Softplus(beta=10.0),\n",
|
||||||
|
" # Sofplus activation ensures that the raw opacity\n",
|
||||||
|
" # is a non-negative number.\n",
|
||||||
|
" )\n",
|
||||||
|
" \n",
|
||||||
|
" # We set the bias of the density layer to -1.5\n",
|
||||||
|
" # in order to initialize the opacities of the\n",
|
||||||
|
" # ray points to values close to 0. \n",
|
||||||
|
" # This is a crucial detail for ensuring convergence\n",
|
||||||
|
" # of the model.\n",
|
||||||
|
" self.density_layer[0].bias.data[0] = -1.5 \n",
|
||||||
|
" \n",
|
||||||
|
" def _get_densities(self, features):\n",
|
||||||
|
" \"\"\"\n",
|
||||||
|
" This function takes `features` predicted by `self.mlp`\n",
|
||||||
|
" and converts them to `raw_densities` with `self.density_layer`.\n",
|
||||||
|
" `raw_densities` are later mapped to [0-1] range with\n",
|
||||||
|
" 1 - inverse exponential of `raw_densities`.\n",
|
||||||
|
" \"\"\"\n",
|
||||||
|
" raw_densities = self.density_layer(features)\n",
|
||||||
|
" return 1 - (-raw_densities).exp()\n",
|
||||||
|
" \n",
|
||||||
|
" def _get_colors(self, features, rays_directions):\n",
|
||||||
|
" \"\"\"\n",
|
||||||
|
" This function takes per-point `features` predicted by `self.mlp`\n",
|
||||||
|
" and evaluates the color model in order to attach to each\n",
|
||||||
|
" point a 3D vector of its RGB color.\n",
|
||||||
|
" \n",
|
||||||
|
" In order to represent viewpoint dependent effects,\n",
|
||||||
|
" before evaluating `self.color_layer`, `NeuralRadianceField`\n",
|
||||||
|
" concatenates to the `features` a harmonic embedding\n",
|
||||||
|
" of `ray_directions`, which are per-point directions \n",
|
||||||
|
" of point rays expressed as 3D l2-normalized vectors\n",
|
||||||
|
" in world coordinates.\n",
|
||||||
|
" \"\"\"\n",
|
||||||
|
" spatial_size = features.shape[:-1]\n",
|
||||||
|
" \n",
|
||||||
|
" # Normalize the ray_directions to unit l2 norm.\n",
|
||||||
|
" rays_directions_normed = torch.nn.functional.normalize(\n",
|
||||||
|
" rays_directions, dim=-1\n",
|
||||||
|
" )\n",
|
||||||
|
" \n",
|
||||||
|
" # Obtain the harmonic embedding of the normalized ray directions.\n",
|
||||||
|
" rays_embedding = self.harmonic_embedding(\n",
|
||||||
|
" rays_directions_normed\n",
|
||||||
|
" )\n",
|
||||||
|
" \n",
|
||||||
|
" # Expand the ray directions tensor so that its spatial size\n",
|
||||||
|
" # is equal to the size of features.\n",
|
||||||
|
" rays_embedding_expand = rays_embedding[..., None, :].expand(\n",
|
||||||
|
" *spatial_size, rays_embedding.shape[-1]\n",
|
||||||
|
" )\n",
|
||||||
|
" \n",
|
||||||
|
" # Concatenate ray direction embeddings with \n",
|
||||||
|
" # features and evaluate the color model.\n",
|
||||||
|
" color_layer_input = torch.cat(\n",
|
||||||
|
" (features, rays_embedding_expand),\n",
|
||||||
|
" dim=-1\n",
|
||||||
|
" )\n",
|
||||||
|
" return self.color_layer(color_layer_input)\n",
|
||||||
|
" \n",
|
||||||
|
" \n",
|
||||||
|
" def forward(\n",
|
||||||
|
" self, \n",
|
||||||
|
" ray_bundle: RayBundle,\n",
|
||||||
|
" **kwargs,\n",
|
||||||
|
" ):\n",
|
||||||
|
" \"\"\"\n",
|
||||||
|
" The forward function accepts the parametrizations of\n",
|
||||||
|
" 3D points sampled along projection rays. The forward\n",
|
||||||
|
" pass is responsible for attaching a 3D vector\n",
|
||||||
|
" and a 1D scalar representing the point's \n",
|
||||||
|
" RGB color and opacity respectively.\n",
|
||||||
|
" \n",
|
||||||
|
" Args:\n",
|
||||||
|
" ray_bundle: A RayBundle object containing the following variables:\n",
|
||||||
|
" origins: A tensor of shape `(minibatch, ..., 3)` denoting the\n",
|
||||||
|
" origins of the sampling rays in world coords.\n",
|
||||||
|
" directions: A tensor of shape `(minibatch, ..., 3)`\n",
|
||||||
|
" containing the direction vectors of sampling rays in world coords.\n",
|
||||||
|
" lengths: A tensor of shape `(minibatch, ..., num_points_per_ray)`\n",
|
||||||
|
" containing the lengths at which the rays are sampled.\n",
|
||||||
|
"\n",
|
||||||
|
" Returns:\n",
|
||||||
|
" rays_densities: A tensor of shape `(minibatch, ..., num_points_per_ray, 1)`\n",
|
||||||
|
" denoting the opacity of each ray point.\n",
|
||||||
|
" rays_colors: A tensor of shape `(minibatch, ..., num_points_per_ray, 3)`\n",
|
||||||
|
" denoting the color of each ray point.\n",
|
||||||
|
" \"\"\"\n",
|
||||||
|
" # We first convert the ray parametrizations to world\n",
|
||||||
|
" # coordinates with `ray_bundle_to_ray_points`.\n",
|
||||||
|
" rays_points_world = ray_bundle_to_ray_points(ray_bundle)\n",
|
||||||
|
" # rays_points_world.shape = [minibatch x ... x 3]\n",
|
||||||
|
" \n",
|
||||||
|
" # For each 3D world coordinate, we obtain its harmonic embedding.\n",
|
||||||
|
" embeds = self.harmonic_embedding(\n",
|
||||||
|
" rays_points_world\n",
|
||||||
|
" )\n",
|
||||||
|
" # embeds.shape = [minibatch x ... x self.n_harmonic_functions*6]\n",
|
||||||
|
" \n",
|
||||||
|
" # self.mlp maps each harmonic embedding to a latent feature space.\n",
|
||||||
|
" features = self.mlp(embeds)\n",
|
||||||
|
" # features.shape = [minibatch x ... x n_hidden_neurons]\n",
|
||||||
|
" \n",
|
||||||
|
" # Finally, given the per-point features, \n",
|
||||||
|
" # execute the density and color branches.\n",
|
||||||
|
" \n",
|
||||||
|
" rays_densities = self._get_densities(features)\n",
|
||||||
|
" # rays_densities.shape = [minibatch x ... x 1]\n",
|
||||||
|
"\n",
|
||||||
|
" rays_colors = self._get_colors(features, ray_bundle.directions)\n",
|
||||||
|
" # rays_colors.shape = [minibatch x ... x 3]\n",
|
||||||
|
" \n",
|
||||||
|
" return rays_densities, rays_colors\n",
|
||||||
|
" \n",
|
||||||
|
" def batched_forward(\n",
|
||||||
|
" self, \n",
|
||||||
|
" ray_bundle: RayBundle,\n",
|
||||||
|
" n_batches: int = 16,\n",
|
||||||
|
" **kwargs, \n",
|
||||||
|
" ):\n",
|
||||||
|
" \"\"\"\n",
|
||||||
|
" This function is used to allow for memory efficient processing\n",
|
||||||
|
" of input rays. The input rays are first split to `n_batches`\n",
|
||||||
|
" chunks and passed through the `self.forward` function one at a time\n",
|
||||||
|
" in a for loop. Combined with disabling PyTorch gradient caching\n",
|
||||||
|
" (`torch.no_grad()`), this allows for rendering large batches\n",
|
||||||
|
" of rays that do not all fit into GPU memory in a single forward pass.\n",
|
||||||
|
" In our case, batched_forward is used to export a fully-sized render\n",
|
||||||
|
" of the radiance field for visualization purposes.\n",
|
||||||
|
" \n",
|
||||||
|
" Args:\n",
|
||||||
|
" ray_bundle: A RayBundle object containing the following variables:\n",
|
||||||
|
" origins: A tensor of shape `(minibatch, ..., 3)` denoting the\n",
|
||||||
|
" origins of the sampling rays in world coords.\n",
|
||||||
|
" directions: A tensor of shape `(minibatch, ..., 3)`\n",
|
||||||
|
" containing the direction vectors of sampling rays in world coords.\n",
|
||||||
|
" lengths: A tensor of shape `(minibatch, ..., num_points_per_ray)`\n",
|
||||||
|
" containing the lengths at which the rays are sampled.\n",
|
||||||
|
" n_batches: Specifies the number of batches the input rays are split into.\n",
|
||||||
|
" The larger the number of batches, the smaller the memory footprint\n",
|
||||||
|
" and the lower the processing speed.\n",
|
||||||
|
"\n",
|
||||||
|
" Returns:\n",
|
||||||
|
" rays_densities: A tensor of shape `(minibatch, ..., num_points_per_ray, 1)`\n",
|
||||||
|
" denoting the opacity of each ray point.\n",
|
||||||
|
" rays_colors: A tensor of shape `(minibatch, ..., num_points_per_ray, 3)`\n",
|
||||||
|
" denoting the color of each ray point.\n",
|
||||||
|
"\n",
|
||||||
|
" \"\"\"\n",
|
||||||
|
"\n",
|
||||||
|
" # Parse out shapes needed for tensor reshaping in this function.\n",
|
||||||
|
" n_pts_per_ray = ray_bundle.lengths.shape[-1] \n",
|
||||||
|
" spatial_size = [*ray_bundle.origins.shape[:-1], n_pts_per_ray]\n",
|
||||||
|
"\n",
|
||||||
|
" # Split the rays to `n_batches` batches.\n",
|
||||||
|
" tot_samples = ray_bundle.origins.shape[:-1].numel()\n",
|
||||||
|
" batches = torch.chunk(torch.arange(tot_samples), n_batches)\n",
|
||||||
|
"\n",
|
||||||
|
" # For each batch, execute the standard forward pass.\n",
|
||||||
|
" batch_outputs = [\n",
|
||||||
|
" self.forward(\n",
|
||||||
|
" RayBundle(\n",
|
||||||
|
" origins=ray_bundle.origins.view(-1, 3)[batch_idx],\n",
|
||||||
|
" directions=ray_bundle.directions.view(-1, 3)[batch_idx],\n",
|
||||||
|
" lengths=ray_bundle.lengths.view(-1, n_pts_per_ray)[batch_idx],\n",
|
||||||
|
" xys=None,\n",
|
||||||
|
" )\n",
|
||||||
|
" ) for batch_idx in batches\n",
|
||||||
|
" ]\n",
|
||||||
|
" \n",
|
||||||
|
" # Concatenate the per-batch rays_densities and rays_colors\n",
|
||||||
|
" # and reshape according to the sizes of the inputs.\n",
|
||||||
|
" rays_densities, rays_colors = [\n",
|
||||||
|
" torch.cat(\n",
|
||||||
|
" [batch_output[output_i] for batch_output in batch_outputs], dim=0\n",
|
||||||
|
" ).view(*spatial_size, -1) for output_i in (0, 1)\n",
|
||||||
|
" ]\n",
|
||||||
|
" return rays_densities, rays_colors"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## 4. Helper functions\n",
|
||||||
|
"\n",
|
||||||
|
"In this function we define functions that help with the Neural Radiance Field optimization."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"def huber(x, y, scaling=0.1):\n",
|
||||||
|
" \"\"\"\n",
|
||||||
|
" A helper function for evaluating the smooth L1 (huber) loss\n",
|
||||||
|
" between the rendered silhouettes and colors.\n",
|
||||||
|
" \"\"\"\n",
|
||||||
|
" diff_sq = (x - y) ** 2\n",
|
||||||
|
" loss = ((1 + diff_sq / (scaling**2)).clamp(1e-4).sqrt() - 1) * float(scaling)\n",
|
||||||
|
" return loss\n",
|
||||||
|
"\n",
|
||||||
|
"def sample_images_at_mc_locs(target_images, sampled_rays_xy):\n",
|
||||||
|
" \"\"\"\n",
|
||||||
|
" Given a set of Monte Carlo pixel locations `sampled_rays_xy`,\n",
|
||||||
|
" this method samples the tensor `target_images` at the\n",
|
||||||
|
" respective 2D locations.\n",
|
||||||
|
" \n",
|
||||||
|
" This function is used in order to extract the colors from\n",
|
||||||
|
" ground truth images that correspond to the colors\n",
|
||||||
|
" rendered using `MonteCarloRaysampler`.\n",
|
||||||
|
" \"\"\"\n",
|
||||||
|
" ba = target_images.shape[0]\n",
|
||||||
|
" dim = target_images.shape[-1]\n",
|
||||||
|
" spatial_size = sampled_rays_xy.shape[1:-1]\n",
|
||||||
|
" # In order to sample target_images, we utilize\n",
|
||||||
|
" # the grid_sample function which implements a\n",
|
||||||
|
" # bilinear image sampler.\n",
|
||||||
|
" # Note that we have to invert the sign of the \n",
|
||||||
|
" # sampled ray positions to convert the NDC xy locations\n",
|
||||||
|
" # of the MonteCarloRaysampler to the coordinate\n",
|
||||||
|
" # convention of grid_sample.\n",
|
||||||
|
" images_sampled = torch.nn.functional.grid_sample(\n",
|
||||||
|
" target_images.permute(0, 3, 1, 2), \n",
|
||||||
|
" -sampled_rays_xy.view(ba, -1, 1, 2), # note the sign inversion\n",
|
||||||
|
" align_corners=True\n",
|
||||||
|
" )\n",
|
||||||
|
" return images_sampled.permute(0, 2, 3, 1).view(\n",
|
||||||
|
" ba, *spatial_size, dim\n",
|
||||||
|
" )\n",
|
||||||
|
"\n",
|
||||||
|
"def show_full_render(\n",
|
||||||
|
" neural_radiance_field, camera,\n",
|
||||||
|
" target_image, target_silhouette,\n",
|
||||||
|
" loss_history_color, loss_history_sil,\n",
|
||||||
|
"):\n",
|
||||||
|
" \"\"\"\n",
|
||||||
|
" This is a helper function for visualizing the\n",
|
||||||
|
" intermediate results of the learning. \n",
|
||||||
|
" \n",
|
||||||
|
" Since the `NeuralRadianceField` suffers from\n",
|
||||||
|
" a large memory footprint, which does not let us\n",
|
||||||
|
" render the full image grid in a single forward pass,\n",
|
||||||
|
" we utilize the `NeuralRadianceField.batched_forward`\n",
|
||||||
|
" function in combination with disabling the gradient caching.\n",
|
||||||
|
" This chunks the set of emitted rays to batches and \n",
|
||||||
|
" evaluates the implicit function on one batch at a time\n",
|
||||||
|
" to prevent GPU memory overflow.\n",
|
||||||
|
" \"\"\"\n",
|
||||||
|
" \n",
|
||||||
|
" # Prevent gradient caching.\n",
|
||||||
|
" with torch.no_grad():\n",
|
||||||
|
" # Render using the grid renderer and the\n",
|
||||||
|
" # batched_forward function of neural_radiance_field.\n",
|
||||||
|
" rendered_image_silhouette, _ = renderer_grid(\n",
|
||||||
|
" cameras=camera, \n",
|
||||||
|
" volumetric_function=neural_radiance_field.batched_forward\n",
|
||||||
|
" )\n",
|
||||||
|
" # Split the rendering result to a silhouette render\n",
|
||||||
|
" # and the image render.\n",
|
||||||
|
" rendered_image, rendered_silhouette = (\n",
|
||||||
|
" rendered_image_silhouette[0].split([3, 1], dim=-1)\n",
|
||||||
|
" )\n",
|
||||||
|
" \n",
|
||||||
|
" # Generate plots.\n",
|
||||||
|
" fig, ax = plt.subplots(2, 3, figsize=(15, 10))\n",
|
||||||
|
" ax = ax.ravel()\n",
|
||||||
|
" clamp_and_detach = lambda x: x.clamp(0.0, 1.0).cpu().detach().numpy()\n",
|
||||||
|
" ax[0].plot(list(range(len(loss_history_color))), loss_history_color, linewidth=1)\n",
|
||||||
|
" ax[1].imshow(clamp_and_detach(rendered_image))\n",
|
||||||
|
" ax[2].imshow(clamp_and_detach(rendered_silhouette[..., 0]))\n",
|
||||||
|
" ax[3].plot(list(range(len(loss_history_sil))), loss_history_sil, linewidth=1)\n",
|
||||||
|
" ax[4].imshow(clamp_and_detach(target_image))\n",
|
||||||
|
" ax[5].imshow(clamp_and_detach(target_silhouette))\n",
|
||||||
|
" for ax_, title_ in zip(\n",
|
||||||
|
" ax,\n",
|
||||||
|
" (\n",
|
||||||
|
" \"loss color\", \"rendered image\", \"rendered silhouette\",\n",
|
||||||
|
" \"loss silhouette\", \"target image\", \"target silhouette\",\n",
|
||||||
|
" )\n",
|
||||||
|
" ):\n",
|
||||||
|
" if not title_.startswith('loss'):\n",
|
||||||
|
" ax_.grid(\"off\")\n",
|
||||||
|
" ax_.axis(\"off\")\n",
|
||||||
|
" ax_.set_title(title_)\n",
|
||||||
|
" fig.canvas.draw(); fig.show()\n",
|
||||||
|
" display.clear_output(wait=True)\n",
|
||||||
|
" display.display(fig)\n",
|
||||||
|
" return fig\n"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## 5. Fit the radiance field\n",
|
||||||
|
"\n",
|
||||||
|
"Here we carry out the radiance field fitting with differentiable rendering.\n",
|
||||||
|
"\n",
|
||||||
|
"In order to fit the radiance field, we render it from the viewpoints of the `target_cameras`\n",
|
||||||
|
"and compare the resulting renders with the observed `target_images` and `target_silhouettes`.\n",
|
||||||
|
"\n",
|
||||||
|
"The comparison is done by evaluating the mean huber (smooth-l1) error between corresponding\n",
|
||||||
|
"pairs of `target_images`/`rendered_images` and `target_silhouettes`/`rendered_silhouettes`.\n",
|
||||||
|
"\n",
|
||||||
|
"Since we use the `MonteCarloRaysampler`, the outputs of the training renderer `renderer_mc`\n",
|
||||||
|
"are colors of pixels that are randomly sampled from the image plane, not a lattice of pixels forming\n",
|
||||||
|
"a valid image. Thus, in order to compare the rendered colors with the ground truth, we \n",
|
||||||
|
"utilize the random MonteCarlo pixel locations to sample the ground truth images/silhouettes\n",
|
||||||
|
"`target_silhouettes`/`rendered_silhouettes` at the xy locations corresponding to the render\n",
|
||||||
|
"locations. This is done with the helper function `sample_images_at_mc_locs`, which is\n",
|
||||||
|
"described in the previous cell."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# First move all relevant variables to the correct device.\n",
|
||||||
|
"renderer_grid = renderer_grid.to(device)\n",
|
||||||
|
"renderer_mc = renderer_mc.to(device)\n",
|
||||||
|
"target_cameras = target_cameras.to(device)\n",
|
||||||
|
"target_images = target_images.to(device)\n",
|
||||||
|
"target_silhouettes = target_silhouettes.to(device)\n",
|
||||||
|
"\n",
|
||||||
|
"# Set the seed for reproducibility\n",
|
||||||
|
"torch.manual_seed(1)\n",
|
||||||
|
"\n",
|
||||||
|
"# Instantiate the radiance field model.\n",
|
||||||
|
"neural_radiance_field = NeuralRadianceField().to(device)\n",
|
||||||
|
"\n",
|
||||||
|
"# Instantiate the Adam optimizer. We set its master learning rate to 1e-3.\n",
|
||||||
|
"lr = 1e-3\n",
|
||||||
|
"optimizer = torch.optim.Adam(neural_radiance_field.parameters(), lr=lr)\n",
|
||||||
|
"\n",
|
||||||
|
"# We sample 6 random cameras in a minibatch. Each camera\n",
|
||||||
|
"# emits raysampler_mc.n_pts_per_image rays.\n",
|
||||||
|
"batch_size = 6\n",
|
||||||
|
"\n",
|
||||||
|
"# 3000 iterations take ~20 min on a Tesla M40 and lead to\n",
|
||||||
|
"# reasonably sharp results. However, for the best possible\n",
|
||||||
|
"# results, we recommend setting n_iter=20000.\n",
|
||||||
|
"n_iter = 3000\n",
|
||||||
|
"\n",
|
||||||
|
"# Init the loss history buffers.\n",
|
||||||
|
"loss_history_color, loss_history_sil = [], []\n",
|
||||||
|
"\n",
|
||||||
|
"# The main optimization loop.\n",
|
||||||
|
"for iteration in range(n_iter): \n",
|
||||||
|
" # In case we reached the last 75% of iterations,\n",
|
||||||
|
" # decrease the learning rate of the optimizer 10-fold.\n",
|
||||||
|
" if iteration == round(n_iter * 0.75):\n",
|
||||||
|
" print('Decreasing LR 10-fold ...')\n",
|
||||||
|
" optimizer = torch.optim.Adam(\n",
|
||||||
|
" neural_radiance_field.parameters(), lr=lr * 0.1\n",
|
||||||
|
" )\n",
|
||||||
|
" \n",
|
||||||
|
" # Zero the optimizer gradient.\n",
|
||||||
|
" optimizer.zero_grad()\n",
|
||||||
|
" \n",
|
||||||
|
" # Sample random batch indices.\n",
|
||||||
|
" batch_idx = torch.randperm(len(target_cameras))[:batch_size]\n",
|
||||||
|
" \n",
|
||||||
|
" # Sample the minibatch of cameras.\n",
|
||||||
|
" batch_cameras = FoVPerspectiveCameras(\n",
|
||||||
|
" R = target_cameras.R[batch_idx], \n",
|
||||||
|
" T = target_cameras.T[batch_idx], \n",
|
||||||
|
" znear = target_cameras.znear[batch_idx],\n",
|
||||||
|
" zfar = target_cameras.zfar[batch_idx],\n",
|
||||||
|
" aspect_ratio = target_cameras.aspect_ratio[batch_idx],\n",
|
||||||
|
" fov = target_cameras.fov[batch_idx],\n",
|
||||||
|
" device = device,\n",
|
||||||
|
" )\n",
|
||||||
|
" \n",
|
||||||
|
" # Evaluate the nerf model.\n",
|
||||||
|
" rendered_images_silhouettes, sampled_rays = renderer_mc(\n",
|
||||||
|
" cameras=batch_cameras, \n",
|
||||||
|
" volumetric_function=neural_radiance_field\n",
|
||||||
|
" )\n",
|
||||||
|
" rendered_images, rendered_silhouettes = (\n",
|
||||||
|
" rendered_images_silhouettes.split([3, 1], dim=-1)\n",
|
||||||
|
" )\n",
|
||||||
|
" \n",
|
||||||
|
" # Compute the silhouette error as the mean huber\n",
|
||||||
|
" # loss between the predicted masks and the\n",
|
||||||
|
" # sampled target silhouettes.\n",
|
||||||
|
" silhouettes_at_rays = sample_images_at_mc_locs(\n",
|
||||||
|
" target_silhouettes[batch_idx, ..., None], \n",
|
||||||
|
" sampled_rays.xys\n",
|
||||||
|
" )\n",
|
||||||
|
" sil_err = huber(\n",
|
||||||
|
" rendered_silhouettes, \n",
|
||||||
|
" silhouettes_at_rays,\n",
|
||||||
|
" ).abs().mean()\n",
|
||||||
|
"\n",
|
||||||
|
" # Compute the color error as the mean huber\n",
|
||||||
|
" # loss between the rendered colors and the\n",
|
||||||
|
" # sampled target images.\n",
|
||||||
|
" colors_at_rays = sample_images_at_mc_locs(\n",
|
||||||
|
" target_images[batch_idx], \n",
|
||||||
|
" sampled_rays.xys\n",
|
||||||
|
" )\n",
|
||||||
|
" color_err = huber(\n",
|
||||||
|
" rendered_images, \n",
|
||||||
|
" colors_at_rays,\n",
|
||||||
|
" ).abs().mean()\n",
|
||||||
|
" \n",
|
||||||
|
" # The optimization loss is a simple\n",
|
||||||
|
" # sum of the color and silhouette errors.\n",
|
||||||
|
" loss = color_err + sil_err\n",
|
||||||
|
" \n",
|
||||||
|
" # Log the loss history.\n",
|
||||||
|
" loss_history_color.append(float(color_err))\n",
|
||||||
|
" loss_history_sil.append(float(sil_err))\n",
|
||||||
|
" \n",
|
||||||
|
" # Every 10 iterations, print the current values of the losses.\n",
|
||||||
|
" if iteration % 10 == 0:\n",
|
||||||
|
" print(\n",
|
||||||
|
" f'Iteration {iteration:05d}:'\n",
|
||||||
|
" + f' loss color = {float(color_err):1.2e}'\n",
|
||||||
|
" + f' loss silhouette = {float(sil_err):1.2e}'\n",
|
||||||
|
" )\n",
|
||||||
|
" \n",
|
||||||
|
" # Take the optimization step.\n",
|
||||||
|
" loss.backward()\n",
|
||||||
|
" optimizer.step()\n",
|
||||||
|
" \n",
|
||||||
|
" # Visualize the full renders every 100 iterations.\n",
|
||||||
|
" if iteration % 100 == 0:\n",
|
||||||
|
" show_idx = torch.randperm(len(target_cameras))[:1]\n",
|
||||||
|
" show_full_render(\n",
|
||||||
|
" neural_radiance_field,\n",
|
||||||
|
" FoVPerspectiveCameras(\n",
|
||||||
|
" R = target_cameras.R[show_idx], \n",
|
||||||
|
" T = target_cameras.T[show_idx], \n",
|
||||||
|
" znear = target_cameras.znear[show_idx],\n",
|
||||||
|
" zfar = target_cameras.zfar[show_idx],\n",
|
||||||
|
" aspect_ratio = target_cameras.aspect_ratio[show_idx],\n",
|
||||||
|
" fov = target_cameras.fov[show_idx],\n",
|
||||||
|
" device = device,\n",
|
||||||
|
" ), \n",
|
||||||
|
" target_images[show_idx][0],\n",
|
||||||
|
" target_silhouettes[show_idx][0],\n",
|
||||||
|
" loss_history_color,\n",
|
||||||
|
" loss_history_sil,\n",
|
||||||
|
" )"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## 6. Visualizing the optimized neural radiance field\n",
|
||||||
|
"\n",
|
||||||
|
"Finally, we visualize the neural radiance field by rendering from multiple viewpoints that rotate around the volume's y-axis."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"def generate_rotating_nerf(neural_radiance_field, n_frames = 50):\n",
|
||||||
|
" logRs = torch.zeros(n_frames, 3, device=device)\n",
|
||||||
|
" logRs[:, 1] = torch.linspace(-3.14, 3.14, n_frames, device=device)\n",
|
||||||
|
" Rs = so3_exp_map(logRs)\n",
|
||||||
|
" Ts = torch.zeros(n_frames, 3, device=device)\n",
|
||||||
|
" Ts[:, 2] = 2.7\n",
|
||||||
|
" frames = []\n",
|
||||||
|
" print('Rendering rotating NeRF ...')\n",
|
||||||
|
" for R, T in zip(tqdm(Rs), Ts):\n",
|
||||||
|
" camera = FoVPerspectiveCameras(\n",
|
||||||
|
" R=R[None], \n",
|
||||||
|
" T=T[None], \n",
|
||||||
|
" znear=target_cameras.znear[0],\n",
|
||||||
|
" zfar=target_cameras.zfar[0],\n",
|
||||||
|
" aspect_ratio=target_cameras.aspect_ratio[0],\n",
|
||||||
|
" fov=target_cameras.fov[0],\n",
|
||||||
|
" device=device,\n",
|
||||||
|
" )\n",
|
||||||
|
" # Note that we again render with `NDCMultinomialRaysampler`\n",
|
||||||
|
" # and the batched_forward function of neural_radiance_field.\n",
|
||||||
|
" frames.append(\n",
|
||||||
|
" renderer_grid(\n",
|
||||||
|
" cameras=camera, \n",
|
||||||
|
" volumetric_function=neural_radiance_field.batched_forward,\n",
|
||||||
|
" )[0][..., :3]\n",
|
||||||
|
" )\n",
|
||||||
|
" return torch.cat(frames)\n",
|
||||||
|
" \n",
|
||||||
|
"with torch.no_grad():\n",
|
||||||
|
" rotating_nerf_frames = generate_rotating_nerf(neural_radiance_field, n_frames=3*5)\n",
|
||||||
|
" \n",
|
||||||
|
"image_grid(rotating_nerf_frames.clamp(0., 1.).cpu().numpy(), rows=3, cols=5, rgb=True, fill=True)\n",
|
||||||
|
"plt.show()"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## 7. Conclusion\n",
|
||||||
|
"\n",
|
||||||
|
"In this tutorial, we have shown how to optimize an implicit representation of a scene such that the renders of the scene from known viewpoints match the observed images for each viewpoint. The rendering was carried out using the PyTorch3D's implicit function renderer composed of either a `MonteCarloRaysampler` or `NDCMultinomialRaysampler`, and an `EmissionAbsorptionRaymarcher`."
|
||||||
|
]
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"bento_stylesheets": {
|
||||||
|
"bento/extensions/flow/main.css": true,
|
||||||
|
"bento/extensions/kernel_selector/main.css": true,
|
||||||
|
"bento/extensions/kernel_ui/main.css": true,
|
||||||
|
"bento/extensions/new_kernel/main.css": true,
|
||||||
|
"bento/extensions/system_usage/main.css": true,
|
||||||
|
"bento/extensions/theme/main.css": true
|
||||||
|
},
|
||||||
|
"kernelspec": {
|
||||||
|
"display_name": "pytorch3d_etc (local)",
|
||||||
|
"language": "python",
|
||||||
|
"name": "pytorch3d_etc_local"
|
||||||
|
},
|
||||||
|
"language_info": {
|
||||||
|
"codemirror_mode": {
|
||||||
|
"name": "ipython",
|
||||||
|
"version": 3
|
||||||
|
},
|
||||||
|
"file_extension": ".py",
|
||||||
|
"mimetype": "text/x-python",
|
||||||
|
"name": "python",
|
||||||
|
"nbconvert_exporter": "python",
|
||||||
|
"pygments_lexer": "ipython3",
|
||||||
|
"version": "3.7.5+"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"nbformat": 4,
|
||||||
|
"nbformat_minor": 2
|
||||||
|
}
|
||||||
@@ -10,7 +10,7 @@
|
|||||||
},
|
},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved."
|
"# Copyright (c) Meta Platforms, Inc. and affiliates. All rights reserved."
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -46,7 +46,7 @@
|
|||||||
"id": "okLalbR_g7NS"
|
"id": "okLalbR_g7NS"
|
||||||
},
|
},
|
||||||
"source": [
|
"source": [
|
||||||
"If `torch`, `torchvision` and `pytorch3d` are not installed, run the following cell:"
|
"Ensure `torch` and `torchvision` are installed. If `pytorch3d` is not installed, install it using the following cell:"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -59,19 +59,27 @@
|
|||||||
},
|
},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"!pip install torch torchvision\n",
|
|
||||||
"import os\n",
|
"import os\n",
|
||||||
"import sys\n",
|
"import sys\n",
|
||||||
"import torch\n",
|
"import torch\n",
|
||||||
"if torch.__version__=='1.6.0+cu101' and sys.platform.startswith('linux'):\n",
|
|
||||||
" !pip install pytorch3d\n",
|
|
||||||
"else:\n",
|
|
||||||
"need_pytorch3d=False\n",
|
"need_pytorch3d=False\n",
|
||||||
"try:\n",
|
"try:\n",
|
||||||
" import pytorch3d\n",
|
" import pytorch3d\n",
|
||||||
"except ModuleNotFoundError:\n",
|
"except ModuleNotFoundError:\n",
|
||||||
" need_pytorch3d=True\n",
|
" need_pytorch3d=True\n",
|
||||||
"if need_pytorch3d:\n",
|
"if need_pytorch3d:\n",
|
||||||
|
" if torch.__version__.startswith(\"1.11.\") and sys.platform.startswith(\"linux\"):\n",
|
||||||
|
" # We try to install PyTorch3D via a released wheel.\n",
|
||||||
|
" pyt_version_str=torch.__version__.split(\"+\")[0].replace(\".\", \"\")\n",
|
||||||
|
" version_str=\"\".join([\n",
|
||||||
|
" f\"py3{sys.version_info.minor}_cu\",\n",
|
||||||
|
" torch.version.cuda.replace(\".\",\"\"),\n",
|
||||||
|
" f\"_pyt{pyt_version_str}\"\n",
|
||||||
|
" ])\n",
|
||||||
|
" !pip install fvcore iopath\n",
|
||||||
|
" !pip install --no-index --no-cache-dir pytorch3d -f https://dl.fbaipublicfiles.com/pytorch3d/packaging/wheels/{version_str}/download.html\n",
|
||||||
|
" else:\n",
|
||||||
|
" # We try to install PyTorch3D from source.\n",
|
||||||
" !curl -LO https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz\n",
|
" !curl -LO https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz\n",
|
||||||
" !tar xzf 1.10.0.tar.gz\n",
|
" !tar xzf 1.10.0.tar.gz\n",
|
||||||
" os.environ[\"CUB_HOME\"] = os.getcwd() + \"/cub-1.10.0\"\n",
|
" os.environ[\"CUB_HOME\"] = os.getcwd() + \"/cub-1.10.0\"\n",
|
||||||
@@ -91,7 +99,6 @@
|
|||||||
"import os\n",
|
"import os\n",
|
||||||
"import torch\n",
|
"import torch\n",
|
||||||
"import matplotlib.pyplot as plt\n",
|
"import matplotlib.pyplot as plt\n",
|
||||||
"from skimage.io import imread\n",
|
|
||||||
"\n",
|
"\n",
|
||||||
"from pytorch3d.utils import ico_sphere\n",
|
"from pytorch3d.utils import ico_sphere\n",
|
||||||
"import numpy as np\n",
|
"import numpy as np\n",
|
||||||
@@ -111,7 +118,7 @@
|
|||||||
"from pytorch3d.structures import Meshes\n",
|
"from pytorch3d.structures import Meshes\n",
|
||||||
"from pytorch3d.renderer import (\n",
|
"from pytorch3d.renderer import (\n",
|
||||||
" look_at_view_transform,\n",
|
" look_at_view_transform,\n",
|
||||||
" OpenGLPerspectiveCameras, \n",
|
" FoVPerspectiveCameras, \n",
|
||||||
" PointLights, \n",
|
" PointLights, \n",
|
||||||
" DirectionalLights, \n",
|
" DirectionalLights, \n",
|
||||||
" Materials, \n",
|
" Materials, \n",
|
||||||
@@ -150,7 +157,7 @@
|
|||||||
},
|
},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"!wget https://raw.githubusercontent.com/facebookresearch/pytorch3d/master/docs/tutorials/utils/plot_image_grid.py\n",
|
"!wget https://raw.githubusercontent.com/facebookresearch/pytorch3d/main/docs/tutorials/utils/plot_image_grid.py\n",
|
||||||
"from plot_image_grid import image_grid"
|
"from plot_image_grid import image_grid"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -187,11 +194,11 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"### 1. Load a mesh and texture file\n",
|
"### 1. Load a mesh and texture file\n",
|
||||||
"\n",
|
"\n",
|
||||||
"Load an `.obj` file and it's associated `.mtl` file and create a **Textures** and **Meshes** object. \n",
|
"Load an `.obj` file and its associated `.mtl` file and create a **Textures** and **Meshes** object. \n",
|
||||||
"\n",
|
"\n",
|
||||||
"**Meshes** is a unique datastructure provided in PyTorch3D for working with batches of meshes of different sizes. \n",
|
"**Meshes** is a unique datastructure provided in PyTorch3D for working with batches of meshes of different sizes. \n",
|
||||||
"\n",
|
"\n",
|
||||||
"**TexturesVertex** is an auxillary datastructure for storing vertex rgb texture information about meshes. \n",
|
"**TexturesVertex** is an auxiliary datastructure for storing vertex rgb texture information about meshes. \n",
|
||||||
"\n",
|
"\n",
|
||||||
"**Meshes** has several class methods which are used throughout the rendering pipeline."
|
"**Meshes** has several class methods which are used throughout the rendering pipeline."
|
||||||
]
|
]
|
||||||
@@ -255,7 +262,7 @@
|
|||||||
"N = verts.shape[0]\n",
|
"N = verts.shape[0]\n",
|
||||||
"center = verts.mean(0)\n",
|
"center = verts.mean(0)\n",
|
||||||
"scale = max((verts - center).abs().max(0)[0])\n",
|
"scale = max((verts - center).abs().max(0)[0])\n",
|
||||||
"mesh.offset_verts_(-center.expand(N, 3))\n",
|
"mesh.offset_verts_(-center)\n",
|
||||||
"mesh.scale_verts_((1.0 / float(scale)));"
|
"mesh.scale_verts_((1.0 / float(scale)));"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -297,11 +304,11 @@
|
|||||||
"# broadcasting. So we can view the camera from the a distance of dist=2.7, and \n",
|
"# broadcasting. So we can view the camera from the a distance of dist=2.7, and \n",
|
||||||
"# then specify elevation and azimuth angles for each viewpoint as tensors. \n",
|
"# then specify elevation and azimuth angles for each viewpoint as tensors. \n",
|
||||||
"R, T = look_at_view_transform(dist=2.7, elev=elev, azim=azim)\n",
|
"R, T = look_at_view_transform(dist=2.7, elev=elev, azim=azim)\n",
|
||||||
"cameras = OpenGLPerspectiveCameras(device=device, R=R, T=T)\n",
|
"cameras = FoVPerspectiveCameras(device=device, R=R, T=T)\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# We arbitrarily choose one particular view that will be used to visualize \n",
|
"# We arbitrarily choose one particular view that will be used to visualize \n",
|
||||||
"# results\n",
|
"# results\n",
|
||||||
"camera = OpenGLPerspectiveCameras(device=device, R=R[None, 1, ...], \n",
|
"camera = FoVPerspectiveCameras(device=device, R=R[None, 1, ...], \n",
|
||||||
" T=T[None, 1, ...]) \n",
|
" T=T[None, 1, ...]) \n",
|
||||||
"\n",
|
"\n",
|
||||||
"# Define the settings for rasterization and shading. Here we set the output \n",
|
"# Define the settings for rasterization and shading. Here we set the output \n",
|
||||||
@@ -309,7 +316,7 @@
|
|||||||
"# purposes only we will set faces_per_pixel=1 and blur_radius=0.0. Refer to \n",
|
"# purposes only we will set faces_per_pixel=1 and blur_radius=0.0. Refer to \n",
|
||||||
"# rasterize_meshes.py for explanations of these parameters. We also leave \n",
|
"# rasterize_meshes.py for explanations of these parameters. We also leave \n",
|
||||||
"# bin_size and max_faces_per_bin to their default values of None, which sets \n",
|
"# bin_size and max_faces_per_bin to their default values of None, which sets \n",
|
||||||
"# their values using huristics and ensures that the faster coarse-to-fine \n",
|
"# their values using heuristics and ensures that the faster coarse-to-fine \n",
|
||||||
"# rasterization method is used. Refer to docs/notes/renderer.md for an \n",
|
"# rasterization method is used. Refer to docs/notes/renderer.md for an \n",
|
||||||
"# explanation of the difference between naive and coarse-to-fine rasterization. \n",
|
"# explanation of the difference between naive and coarse-to-fine rasterization. \n",
|
||||||
"raster_settings = RasterizationSettings(\n",
|
"raster_settings = RasterizationSettings(\n",
|
||||||
@@ -318,8 +325,8 @@
|
|||||||
" faces_per_pixel=1, \n",
|
" faces_per_pixel=1, \n",
|
||||||
")\n",
|
")\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# Create a phong renderer by composing a rasterizer and a shader. The textured \n",
|
"# Create a Phong renderer by composing a rasterizer and a shader. The textured \n",
|
||||||
"# phong shader will interpolate the texture uv coordinates for each vertex, \n",
|
"# Phong shader will interpolate the texture uv coordinates for each vertex, \n",
|
||||||
"# sample from a texture image and apply the Phong lighting model\n",
|
"# sample from a texture image and apply the Phong lighting model\n",
|
||||||
"renderer = MeshRenderer(\n",
|
"renderer = MeshRenderer(\n",
|
||||||
" rasterizer=MeshRasterizer(\n",
|
" rasterizer=MeshRasterizer(\n",
|
||||||
@@ -344,7 +351,7 @@
|
|||||||
"# Our multi-view cow dataset will be represented by these 2 lists of tensors,\n",
|
"# Our multi-view cow dataset will be represented by these 2 lists of tensors,\n",
|
||||||
"# each of length num_views.\n",
|
"# each of length num_views.\n",
|
||||||
"target_rgb = [target_images[i, ..., :3] for i in range(num_views)]\n",
|
"target_rgb = [target_images[i, ..., :3] for i in range(num_views)]\n",
|
||||||
"target_cameras = [OpenGLPerspectiveCameras(device=device, R=R[None, i, ...], \n",
|
"target_cameras = [FoVPerspectiveCameras(device=device, R=R[None, i, ...], \n",
|
||||||
" T=T[None, i, ...]) for i in range(num_views)]"
|
" T=T[None, i, ...]) for i in range(num_views)]"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -380,7 +387,7 @@
|
|||||||
"id": "gOb4rYx65E8z"
|
"id": "gOb4rYx65E8z"
|
||||||
},
|
},
|
||||||
"source": [
|
"source": [
|
||||||
"Later in this tutorial, we will fit a mesh to the rendered RGB images, as well as to just images of just the cow silhouette. For the latter case, we will render a dataset of silhouette images. Most shaders in PyTorch3D will output an alpha channel along with the RGB image as a 4th channel in an RGBA image. The alpha channel encodes the probability that each pixel belongs to the foreground of the object. We contruct a soft silhouette shader to render this alpha channel."
|
"Later in this tutorial, we will fit a mesh to the rendered RGB images, as well as to just images of just the cow silhouette. For the latter case, we will render a dataset of silhouette images. Most shaders in PyTorch3D will output an alpha channel along with the RGB image as a 4th channel in an RGBA image. The alpha channel encodes the probability that each pixel belongs to the foreground of the object. We construct a soft silhouette shader to render this alpha channel."
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -449,6 +456,7 @@
|
|||||||
" target_image=target_rgb[1], title='', \n",
|
" target_image=target_rgb[1], title='', \n",
|
||||||
" silhouette=False):\n",
|
" silhouette=False):\n",
|
||||||
" inds = 3 if silhouette else range(3)\n",
|
" inds = 3 if silhouette else range(3)\n",
|
||||||
|
" with torch.no_grad():\n",
|
||||||
" predicted_images = renderer(predicted_mesh)\n",
|
" predicted_images = renderer(predicted_mesh)\n",
|
||||||
" plt.figure(figsize=(20, 10))\n",
|
" plt.figure(figsize=(20, 10))\n",
|
||||||
" plt.subplot(1, 2, 1)\n",
|
" plt.subplot(1, 2, 1)\n",
|
||||||
@@ -457,7 +465,6 @@
|
|||||||
" plt.subplot(1, 2, 2)\n",
|
" plt.subplot(1, 2, 2)\n",
|
||||||
" plt.imshow(target_image.cpu().detach().numpy())\n",
|
" plt.imshow(target_image.cpu().detach().numpy())\n",
|
||||||
" plt.title(title)\n",
|
" plt.title(title)\n",
|
||||||
" plt.grid(\"off\")\n",
|
|
||||||
" plt.axis(\"off\")\n",
|
" plt.axis(\"off\")\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# Plot losses as a function of optimization iteration\n",
|
"# Plot losses as a function of optimization iteration\n",
|
||||||
@@ -601,7 +608,7 @@
|
|||||||
"id": "QLc9zK8lEqFS"
|
"id": "QLc9zK8lEqFS"
|
||||||
},
|
},
|
||||||
"source": [
|
"source": [
|
||||||
"We write an optimization loop to iteratively refine our predicted mesh from the sphere mesh into a mesh that matches the sillhouettes of the target images:"
|
"We write an optimization loop to iteratively refine our predicted mesh from the sphere mesh into a mesh that matches the silhouettes of the target images:"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -640,7 +647,8 @@
|
|||||||
" sum_loss = torch.tensor(0.0, device=device)\n",
|
" sum_loss = torch.tensor(0.0, device=device)\n",
|
||||||
" for k, l in loss.items():\n",
|
" for k, l in loss.items():\n",
|
||||||
" sum_loss += l * losses[k][\"weight\"]\n",
|
" sum_loss += l * losses[k][\"weight\"]\n",
|
||||||
" losses[k][\"values\"].append(l)\n",
|
" losses[k][\"values\"].append(float(l.detach().cpu()))\n",
|
||||||
|
"\n",
|
||||||
" \n",
|
" \n",
|
||||||
" # Print the losses\n",
|
" # Print the losses\n",
|
||||||
" loop.set_description(\"total_loss = %.6f\" % sum_loss)\n",
|
" loop.set_description(\"total_loss = %.6f\" % sum_loss)\n",
|
||||||
@@ -700,6 +708,7 @@
|
|||||||
" image_size=128, \n",
|
" image_size=128, \n",
|
||||||
" blur_radius=np.log(1. / 1e-4 - 1.)*sigma, \n",
|
" blur_radius=np.log(1. / 1e-4 - 1.)*sigma, \n",
|
||||||
" faces_per_pixel=50, \n",
|
" faces_per_pixel=50, \n",
|
||||||
|
" perspective_correct=False, \n",
|
||||||
")\n",
|
")\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# Differentiable soft renderer using per vertex RGB colors for texture\n",
|
"# Differentiable soft renderer using per vertex RGB colors for texture\n",
|
||||||
@@ -824,7 +833,7 @@
|
|||||||
" sum_loss = torch.tensor(0.0, device=device)\n",
|
" sum_loss = torch.tensor(0.0, device=device)\n",
|
||||||
" for k, l in loss.items():\n",
|
" for k, l in loss.items():\n",
|
||||||
" sum_loss += l * losses[k][\"weight\"]\n",
|
" sum_loss += l * losses[k][\"weight\"]\n",
|
||||||
" losses[k][\"values\"].append(l)\n",
|
" losses[k][\"values\"].append(float(l.detach().cpu()))\n",
|
||||||
" \n",
|
" \n",
|
||||||
" # Print the losses\n",
|
" # Print the losses\n",
|
||||||
" loop.set_description(\"total_loss = %.6f\" % sum_loss)\n",
|
" loop.set_description(\"total_loss = %.6f\" % sum_loss)\n",
|
||||||
|
|||||||
498
docs/tutorials/fit_textured_volume.ipynb
Normal file
498
docs/tutorials/fit_textured_volume.ipynb
Normal file
@@ -0,0 +1,498 @@
|
|||||||
|
{
|
||||||
|
"cells": [
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# Copyright (c) Meta Platforms, Inc. and affiliates. All rights reserved."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"# Fit a volume via raymarching\n",
|
||||||
|
"\n",
|
||||||
|
"This tutorial shows how to fit a volume given a set of views of a scene using differentiable volumetric rendering.\n",
|
||||||
|
"\n",
|
||||||
|
"More specifically, this tutorial will explain how to:\n",
|
||||||
|
"1. Create a differentiable volumetric renderer.\n",
|
||||||
|
"2. Create a Volumetric model (including how to use the `Volumes` class).\n",
|
||||||
|
"3. Fit the volume based on the images using the differentiable volumetric renderer. \n",
|
||||||
|
"4. Visualize the predicted volume."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## 0. Install and Import modules\n",
|
||||||
|
"Ensure `torch` and `torchvision` are installed. If `pytorch3d` is not installed, install it using the following cell:"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"import os\n",
|
||||||
|
"import sys\n",
|
||||||
|
"import torch\n",
|
||||||
|
"need_pytorch3d=False\n",
|
||||||
|
"try:\n",
|
||||||
|
" import pytorch3d\n",
|
||||||
|
"except ModuleNotFoundError:\n",
|
||||||
|
" need_pytorch3d=True\n",
|
||||||
|
"if need_pytorch3d:\n",
|
||||||
|
" if torch.__version__.startswith(\"1.11.\") and sys.platform.startswith(\"linux\"):\n",
|
||||||
|
" # We try to install PyTorch3D via a released wheel.\n",
|
||||||
|
" pyt_version_str=torch.__version__.split(\"+\")[0].replace(\".\", \"\")\n",
|
||||||
|
" version_str=\"\".join([\n",
|
||||||
|
" f\"py3{sys.version_info.minor}_cu\",\n",
|
||||||
|
" torch.version.cuda.replace(\".\",\"\"),\n",
|
||||||
|
" f\"_pyt{pyt_version_str}\"\n",
|
||||||
|
" ])\n",
|
||||||
|
" !pip install fvcore iopath\n",
|
||||||
|
" !pip install --no-index --no-cache-dir pytorch3d -f https://dl.fbaipublicfiles.com/pytorch3d/packaging/wheels/{version_str}/download.html\n",
|
||||||
|
" else:\n",
|
||||||
|
" # We try to install PyTorch3D from source.\n",
|
||||||
|
" !curl -LO https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz\n",
|
||||||
|
" !tar xzf 1.10.0.tar.gz\n",
|
||||||
|
" os.environ[\"CUB_HOME\"] = os.getcwd() + \"/cub-1.10.0\"\n",
|
||||||
|
" !pip install 'git+https://github.com/facebookresearch/pytorch3d.git@stable'"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"import os\n",
|
||||||
|
"import sys\n",
|
||||||
|
"import time\n",
|
||||||
|
"import json\n",
|
||||||
|
"import glob\n",
|
||||||
|
"import torch\n",
|
||||||
|
"import math\n",
|
||||||
|
"from tqdm.notebook import tqdm\n",
|
||||||
|
"import matplotlib.pyplot as plt\n",
|
||||||
|
"import numpy as np\n",
|
||||||
|
"from PIL import Image\n",
|
||||||
|
"from IPython import display\n",
|
||||||
|
"\n",
|
||||||
|
"# Data structures and functions for rendering\n",
|
||||||
|
"from pytorch3d.structures import Volumes\n",
|
||||||
|
"from pytorch3d.renderer import (\n",
|
||||||
|
" FoVPerspectiveCameras, \n",
|
||||||
|
" VolumeRenderer,\n",
|
||||||
|
" NDCMultinomialRaysampler,\n",
|
||||||
|
" EmissionAbsorptionRaymarcher\n",
|
||||||
|
")\n",
|
||||||
|
"from pytorch3d.transforms import so3_exp_map\n",
|
||||||
|
"\n",
|
||||||
|
"# obtain the utilized device\n",
|
||||||
|
"if torch.cuda.is_available():\n",
|
||||||
|
" device = torch.device(\"cuda:0\")\n",
|
||||||
|
" torch.cuda.set_device(device)\n",
|
||||||
|
"else:\n",
|
||||||
|
" device = torch.device(\"cpu\")"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"!wget https://raw.githubusercontent.com/facebookresearch/pytorch3d/main/docs/tutorials/utils/plot_image_grid.py\n",
|
||||||
|
"!wget https://raw.githubusercontent.com/facebookresearch/pytorch3d/main/docs/tutorials/utils/generate_cow_renders.py\n",
|
||||||
|
"from plot_image_grid import image_grid\n",
|
||||||
|
"from generate_cow_renders import generate_cow_renders"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"OR if running locally uncomment and run the following cell:"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# from utils.generate_cow_renders import generate_cow_renders\n",
|
||||||
|
"# from utils import image_grid"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## 1. Generate images of the scene and masks\n",
|
||||||
|
"\n",
|
||||||
|
"The following cell generates our training data.\n",
|
||||||
|
"It renders the cow mesh from the `fit_textured_mesh.ipynb` tutorial from several viewpoints and returns:\n",
|
||||||
|
"1. A batch of image and silhouette tensors that are produced by the cow mesh renderer.\n",
|
||||||
|
"2. A set of cameras corresponding to each render.\n",
|
||||||
|
"\n",
|
||||||
|
"Note: For the purpose of this tutorial, which aims at explaining the details of volumetric rendering, we do not explain how the mesh rendering, implemented in the `generate_cow_renders` function, works. Please refer to `fit_textured_mesh.ipynb` for a detailed explanation of mesh rendering."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"target_cameras, target_images, target_silhouettes = generate_cow_renders(num_views=40)\n",
|
||||||
|
"print(f'Generated {len(target_images)} images/silhouettes/cameras.')"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## 2. Initialize the volumetric renderer\n",
|
||||||
|
"\n",
|
||||||
|
"The following initializes a volumetric renderer that emits a ray from each pixel of a target image and samples a set of uniformly-spaced points along the ray. At each ray-point, the corresponding density and color value is obtained by querying the corresponding location in the volumetric model of the scene (the model is described & instantiated in a later cell).\n",
|
||||||
|
"\n",
|
||||||
|
"The renderer is composed of a *raymarcher* and a *raysampler*.\n",
|
||||||
|
"- The *raysampler* is responsible for emitting rays from image pixels and sampling the points along them. Here, we use the `NDCMultinomialRaysampler` which follows the standard PyTorch3D coordinate grid convention (+X from right to left; +Y from bottom to top; +Z away from the user).\n",
|
||||||
|
"- The *raymarcher* takes the densities and colors sampled along each ray and renders each ray into a color and an opacity value of the ray's source pixel. Here we use the `EmissionAbsorptionRaymarcher` which implements the standard Emission-Absorption raymarching algorithm."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# render_size describes the size of both sides of the \n",
|
||||||
|
"# rendered images in pixels. We set this to the same size\n",
|
||||||
|
"# as the target images. I.e. we render at the same\n",
|
||||||
|
"# size as the ground truth images.\n",
|
||||||
|
"render_size = target_images.shape[1]\n",
|
||||||
|
"\n",
|
||||||
|
"# Our rendered scene is centered around (0,0,0) \n",
|
||||||
|
"# and is enclosed inside a bounding box\n",
|
||||||
|
"# whose side is roughly equal to 3.0 (world units).\n",
|
||||||
|
"volume_extent_world = 3.0\n",
|
||||||
|
"\n",
|
||||||
|
"# 1) Instantiate the raysampler.\n",
|
||||||
|
"# Here, NDCMultinomialRaysampler generates a rectangular image\n",
|
||||||
|
"# grid of rays whose coordinates follow the PyTorch3D\n",
|
||||||
|
"# coordinate conventions.\n",
|
||||||
|
"# Since we use a volume of size 128^3, we sample n_pts_per_ray=150,\n",
|
||||||
|
"# which roughly corresponds to a one ray-point per voxel.\n",
|
||||||
|
"# We further set the min_depth=0.1 since there is no surface within\n",
|
||||||
|
"# 0.1 units of any camera plane.\n",
|
||||||
|
"raysampler = NDCMultinomialRaysampler(\n",
|
||||||
|
" image_width=render_size,\n",
|
||||||
|
" image_height=render_size,\n",
|
||||||
|
" n_pts_per_ray=150,\n",
|
||||||
|
" min_depth=0.1,\n",
|
||||||
|
" max_depth=volume_extent_world,\n",
|
||||||
|
")\n",
|
||||||
|
"\n",
|
||||||
|
"\n",
|
||||||
|
"# 2) Instantiate the raymarcher.\n",
|
||||||
|
"# Here, we use the standard EmissionAbsorptionRaymarcher \n",
|
||||||
|
"# which marches along each ray in order to render\n",
|
||||||
|
"# each ray into a single 3D color vector \n",
|
||||||
|
"# and an opacity scalar.\n",
|
||||||
|
"raymarcher = EmissionAbsorptionRaymarcher()\n",
|
||||||
|
"\n",
|
||||||
|
"# Finally, instantiate the volumetric render\n",
|
||||||
|
"# with the raysampler and raymarcher objects.\n",
|
||||||
|
"renderer = VolumeRenderer(\n",
|
||||||
|
" raysampler=raysampler, raymarcher=raymarcher,\n",
|
||||||
|
")"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## 3. Initialize the volumetric model\n",
|
||||||
|
"\n",
|
||||||
|
"Next we instantiate a volumetric model of the scene. This quantizes the 3D space to cubical voxels, where each voxel is described with a 3D vector representing the voxel's RGB color and a density scalar which describes the opacity of the voxel (ranging between [0-1], the higher the more opaque).\n",
|
||||||
|
"\n",
|
||||||
|
"In order to ensure the range of densities and colors is between [0-1], we represent both volume colors and densities in the logarithmic space. During the forward function of the model, the log-space values are passed through the sigmoid function to bring the log-space values to the correct range.\n",
|
||||||
|
"\n",
|
||||||
|
"Additionally, `VolumeModel` contains the renderer object. This object stays unaltered throughout the optimization.\n",
|
||||||
|
"\n",
|
||||||
|
"In this cell we also define the `huber` loss function which computes the discrepancy between the rendered colors and masks."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"class VolumeModel(torch.nn.Module):\n",
|
||||||
|
" def __init__(self, renderer, volume_size=[64] * 3, voxel_size=0.1):\n",
|
||||||
|
" super().__init__()\n",
|
||||||
|
" # After evaluating torch.sigmoid(self.log_colors), we get \n",
|
||||||
|
" # densities close to zero.\n",
|
||||||
|
" self.log_densities = torch.nn.Parameter(-4.0 * torch.ones(1, *volume_size))\n",
|
||||||
|
" # After evaluating torch.sigmoid(self.log_colors), we get \n",
|
||||||
|
" # a neutral gray color everywhere.\n",
|
||||||
|
" self.log_colors = torch.nn.Parameter(torch.zeros(3, *volume_size))\n",
|
||||||
|
" self._voxel_size = voxel_size\n",
|
||||||
|
" # Store the renderer module as well.\n",
|
||||||
|
" self._renderer = renderer\n",
|
||||||
|
" \n",
|
||||||
|
" def forward(self, cameras):\n",
|
||||||
|
" batch_size = cameras.R.shape[0]\n",
|
||||||
|
"\n",
|
||||||
|
" # Convert the log-space values to the densities/colors\n",
|
||||||
|
" densities = torch.sigmoid(self.log_densities)\n",
|
||||||
|
" colors = torch.sigmoid(self.log_colors)\n",
|
||||||
|
" \n",
|
||||||
|
" # Instantiate the Volumes object, making sure\n",
|
||||||
|
" # the densities and colors are correctly\n",
|
||||||
|
" # expanded batch_size-times.\n",
|
||||||
|
" volumes = Volumes(\n",
|
||||||
|
" densities = densities[None].expand(\n",
|
||||||
|
" batch_size, *self.log_densities.shape),\n",
|
||||||
|
" features = colors[None].expand(\n",
|
||||||
|
" batch_size, *self.log_colors.shape),\n",
|
||||||
|
" voxel_size=self._voxel_size,\n",
|
||||||
|
" )\n",
|
||||||
|
" \n",
|
||||||
|
" # Given cameras and volumes, run the renderer\n",
|
||||||
|
" # and return only the first output value \n",
|
||||||
|
" # (the 2nd output is a representation of the sampled\n",
|
||||||
|
" # rays which can be omitted for our purpose).\n",
|
||||||
|
" return self._renderer(cameras=cameras, volumes=volumes)[0]\n",
|
||||||
|
" \n",
|
||||||
|
"# A helper function for evaluating the smooth L1 (huber) loss\n",
|
||||||
|
"# between the rendered silhouettes and colors.\n",
|
||||||
|
"def huber(x, y, scaling=0.1):\n",
|
||||||
|
" diff_sq = (x - y) ** 2\n",
|
||||||
|
" loss = ((1 + diff_sq / (scaling**2)).clamp(1e-4).sqrt() - 1) * float(scaling)\n",
|
||||||
|
" return loss"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## 4. Fit the volume\n",
|
||||||
|
"\n",
|
||||||
|
"Here we carry out the volume fitting with differentiable rendering.\n",
|
||||||
|
"\n",
|
||||||
|
"In order to fit the volume, we render it from the viewpoints of the `target_cameras`\n",
|
||||||
|
"and compare the resulting renders with the observed `target_images` and `target_silhouettes`.\n",
|
||||||
|
"\n",
|
||||||
|
"The comparison is done by evaluating the mean huber (smooth-l1) error between corresponding\n",
|
||||||
|
"pairs of `target_images`/`rendered_images` and `target_silhouettes`/`rendered_silhouettes`."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# First move all relevant variables to the correct device.\n",
|
||||||
|
"target_cameras = target_cameras.to(device)\n",
|
||||||
|
"target_images = target_images.to(device)\n",
|
||||||
|
"target_silhouettes = target_silhouettes.to(device)\n",
|
||||||
|
"\n",
|
||||||
|
"# Instantiate the volumetric model.\n",
|
||||||
|
"# We use a cubical volume with the size of \n",
|
||||||
|
"# one side = 128. The size of each voxel of the volume \n",
|
||||||
|
"# is set to volume_extent_world / volume_size s.t. the\n",
|
||||||
|
"# volume represents the space enclosed in a 3D bounding box\n",
|
||||||
|
"# centered at (0, 0, 0) with the size of each side equal to 3.\n",
|
||||||
|
"volume_size = 128\n",
|
||||||
|
"volume_model = VolumeModel(\n",
|
||||||
|
" renderer,\n",
|
||||||
|
" volume_size=[volume_size] * 3, \n",
|
||||||
|
" voxel_size = volume_extent_world / volume_size,\n",
|
||||||
|
").to(device)\n",
|
||||||
|
"\n",
|
||||||
|
"# Instantiate the Adam optimizer. We set its master learning rate to 0.1.\n",
|
||||||
|
"lr = 0.1\n",
|
||||||
|
"optimizer = torch.optim.Adam(volume_model.parameters(), lr=lr)\n",
|
||||||
|
"\n",
|
||||||
|
"# We do 300 Adam iterations and sample 10 random images in each minibatch.\n",
|
||||||
|
"batch_size = 10\n",
|
||||||
|
"n_iter = 300\n",
|
||||||
|
"for iteration in range(n_iter):\n",
|
||||||
|
"\n",
|
||||||
|
" # In case we reached the last 75% of iterations,\n",
|
||||||
|
" # decrease the learning rate of the optimizer 10-fold.\n",
|
||||||
|
" if iteration == round(n_iter * 0.75):\n",
|
||||||
|
" print('Decreasing LR 10-fold ...')\n",
|
||||||
|
" optimizer = torch.optim.Adam(\n",
|
||||||
|
" volume_model.parameters(), lr=lr * 0.1\n",
|
||||||
|
" )\n",
|
||||||
|
" \n",
|
||||||
|
" # Zero the optimizer gradient.\n",
|
||||||
|
" optimizer.zero_grad()\n",
|
||||||
|
" \n",
|
||||||
|
" # Sample random batch indices.\n",
|
||||||
|
" batch_idx = torch.randperm(len(target_cameras))[:batch_size]\n",
|
||||||
|
" \n",
|
||||||
|
" # Sample the minibatch of cameras.\n",
|
||||||
|
" batch_cameras = FoVPerspectiveCameras(\n",
|
||||||
|
" R = target_cameras.R[batch_idx], \n",
|
||||||
|
" T = target_cameras.T[batch_idx], \n",
|
||||||
|
" znear = target_cameras.znear[batch_idx],\n",
|
||||||
|
" zfar = target_cameras.zfar[batch_idx],\n",
|
||||||
|
" aspect_ratio = target_cameras.aspect_ratio[batch_idx],\n",
|
||||||
|
" fov = target_cameras.fov[batch_idx],\n",
|
||||||
|
" device = device,\n",
|
||||||
|
" )\n",
|
||||||
|
" \n",
|
||||||
|
" # Evaluate the volumetric model.\n",
|
||||||
|
" rendered_images, rendered_silhouettes = volume_model(\n",
|
||||||
|
" batch_cameras\n",
|
||||||
|
" ).split([3, 1], dim=-1)\n",
|
||||||
|
" \n",
|
||||||
|
" # Compute the silhouette error as the mean huber\n",
|
||||||
|
" # loss between the predicted masks and the\n",
|
||||||
|
" # target silhouettes.\n",
|
||||||
|
" sil_err = huber(\n",
|
||||||
|
" rendered_silhouettes[..., 0], target_silhouettes[batch_idx],\n",
|
||||||
|
" ).abs().mean()\n",
|
||||||
|
"\n",
|
||||||
|
" # Compute the color error as the mean huber\n",
|
||||||
|
" # loss between the rendered colors and the\n",
|
||||||
|
" # target ground truth images.\n",
|
||||||
|
" color_err = huber(\n",
|
||||||
|
" rendered_images, target_images[batch_idx],\n",
|
||||||
|
" ).abs().mean()\n",
|
||||||
|
" \n",
|
||||||
|
" # The optimization loss is a simple\n",
|
||||||
|
" # sum of the color and silhouette errors.\n",
|
||||||
|
" loss = color_err + sil_err \n",
|
||||||
|
" \n",
|
||||||
|
" # Print the current values of the losses.\n",
|
||||||
|
" if iteration % 10 == 0:\n",
|
||||||
|
" print(\n",
|
||||||
|
" f'Iteration {iteration:05d}:'\n",
|
||||||
|
" + f' color_err = {float(color_err):1.2e}'\n",
|
||||||
|
" + f' mask_err = {float(sil_err):1.2e}'\n",
|
||||||
|
" )\n",
|
||||||
|
" \n",
|
||||||
|
" # Take the optimization step.\n",
|
||||||
|
" loss.backward()\n",
|
||||||
|
" optimizer.step()\n",
|
||||||
|
" \n",
|
||||||
|
" # Visualize the renders every 40 iterations.\n",
|
||||||
|
" if iteration % 40 == 0:\n",
|
||||||
|
" # Visualize only a single randomly selected element of the batch.\n",
|
||||||
|
" im_show_idx = int(torch.randint(low=0, high=batch_size, size=(1,)))\n",
|
||||||
|
" fig, ax = plt.subplots(2, 2, figsize=(10, 10))\n",
|
||||||
|
" ax = ax.ravel()\n",
|
||||||
|
" clamp_and_detach = lambda x: x.clamp(0.0, 1.0).cpu().detach().numpy()\n",
|
||||||
|
" ax[0].imshow(clamp_and_detach(rendered_images[im_show_idx]))\n",
|
||||||
|
" ax[1].imshow(clamp_and_detach(target_images[batch_idx[im_show_idx], ..., :3]))\n",
|
||||||
|
" ax[2].imshow(clamp_and_detach(rendered_silhouettes[im_show_idx, ..., 0]))\n",
|
||||||
|
" ax[3].imshow(clamp_and_detach(target_silhouettes[batch_idx[im_show_idx]]))\n",
|
||||||
|
" for ax_, title_ in zip(\n",
|
||||||
|
" ax, \n",
|
||||||
|
" (\"rendered image\", \"target image\", \"rendered silhouette\", \"target silhouette\")\n",
|
||||||
|
" ):\n",
|
||||||
|
" ax_.grid(\"off\")\n",
|
||||||
|
" ax_.axis(\"off\")\n",
|
||||||
|
" ax_.set_title(title_)\n",
|
||||||
|
" fig.canvas.draw(); fig.show()\n",
|
||||||
|
" display.clear_output(wait=True)\n",
|
||||||
|
" display.display(fig)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## 5. Visualizing the optimized volume\n",
|
||||||
|
"\n",
|
||||||
|
"Finally, we visualize the optimized volume by rendering from multiple viewpoints that rotate around the volume's y-axis."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"def generate_rotating_volume(volume_model, n_frames = 50):\n",
|
||||||
|
" logRs = torch.zeros(n_frames, 3, device=device)\n",
|
||||||
|
" logRs[:, 1] = torch.linspace(0.0, 2.0 * 3.14, n_frames, device=device)\n",
|
||||||
|
" Rs = so3_exp_map(logRs)\n",
|
||||||
|
" Ts = torch.zeros(n_frames, 3, device=device)\n",
|
||||||
|
" Ts[:, 2] = 2.7\n",
|
||||||
|
" frames = []\n",
|
||||||
|
" print('Generating rotating volume ...')\n",
|
||||||
|
" for R, T in zip(tqdm(Rs), Ts):\n",
|
||||||
|
" camera = FoVPerspectiveCameras(\n",
|
||||||
|
" R=R[None], \n",
|
||||||
|
" T=T[None], \n",
|
||||||
|
" znear = target_cameras.znear[0],\n",
|
||||||
|
" zfar = target_cameras.zfar[0],\n",
|
||||||
|
" aspect_ratio = target_cameras.aspect_ratio[0],\n",
|
||||||
|
" fov = target_cameras.fov[0],\n",
|
||||||
|
" device=device,\n",
|
||||||
|
" )\n",
|
||||||
|
" frames.append(volume_model(camera)[..., :3].clamp(0.0, 1.0))\n",
|
||||||
|
" return torch.cat(frames)\n",
|
||||||
|
" \n",
|
||||||
|
"with torch.no_grad():\n",
|
||||||
|
" rotating_volume_frames = generate_rotating_volume(volume_model, n_frames=7*4)\n",
|
||||||
|
"\n",
|
||||||
|
"image_grid(rotating_volume_frames.clamp(0., 1.).cpu().numpy(), rows=4, cols=7, rgb=True, fill=True)\n",
|
||||||
|
"plt.show()"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## 6. Conclusion\n",
|
||||||
|
"\n",
|
||||||
|
"In this tutorial, we have shown how to optimize a 3D volumetric representation of a scene such that the renders of the volume from known viewpoints match the observed images for each viewpoint. The rendering was carried out using the PyTorch3D's volumetric renderer composed of an `NDCMultinomialRaysampler` and an `EmissionAbsorptionRaymarcher`."
|
||||||
|
]
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"bento_stylesheets": {
|
||||||
|
"bento/extensions/flow/main.css": true,
|
||||||
|
"bento/extensions/kernel_selector/main.css": true,
|
||||||
|
"bento/extensions/kernel_ui/main.css": true,
|
||||||
|
"bento/extensions/new_kernel/main.css": true,
|
||||||
|
"bento/extensions/system_usage/main.css": true,
|
||||||
|
"bento/extensions/theme/main.css": true
|
||||||
|
},
|
||||||
|
"kernelspec": {
|
||||||
|
"display_name": "pytorch3d_etc (local)",
|
||||||
|
"language": "python",
|
||||||
|
"name": "pytorch3d_etc_local"
|
||||||
|
},
|
||||||
|
"language_info": {
|
||||||
|
"codemirror_mode": {
|
||||||
|
"name": "ipython",
|
||||||
|
"version": 3
|
||||||
|
},
|
||||||
|
"file_extension": ".py",
|
||||||
|
"mimetype": "text/x-python",
|
||||||
|
"name": "python",
|
||||||
|
"nbconvert_exporter": "python",
|
||||||
|
"pygments_lexer": "ipython3",
|
||||||
|
"version": "3.7.5+"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"nbformat": 4,
|
||||||
|
"nbformat_minor": 2
|
||||||
|
}
|
||||||
@@ -6,7 +6,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved."
|
"# Copyright (c) Meta Platforms, Inc. and affiliates. All rights reserved."
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -32,7 +32,7 @@
|
|||||||
"cell_type": "markdown",
|
"cell_type": "markdown",
|
||||||
"metadata": {},
|
"metadata": {},
|
||||||
"source": [
|
"source": [
|
||||||
"If `torch`, `torchvision` and `pytorch3d` are not installed, run the following cell:"
|
"Ensure `torch` and `torchvision` are installed. If `pytorch3d` is not installed, install it using the following cell:"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -41,19 +41,27 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"!pip install torch torchvision\n",
|
|
||||||
"import os\n",
|
"import os\n",
|
||||||
"import sys\n",
|
"import sys\n",
|
||||||
"import torch\n",
|
"import torch\n",
|
||||||
"if torch.__version__=='1.6.0+cu101' and sys.platform.startswith('linux'):\n",
|
|
||||||
" !pip install pytorch3d\n",
|
|
||||||
"else:\n",
|
|
||||||
"need_pytorch3d=False\n",
|
"need_pytorch3d=False\n",
|
||||||
"try:\n",
|
"try:\n",
|
||||||
" import pytorch3d\n",
|
" import pytorch3d\n",
|
||||||
"except ModuleNotFoundError:\n",
|
"except ModuleNotFoundError:\n",
|
||||||
" need_pytorch3d=True\n",
|
" need_pytorch3d=True\n",
|
||||||
"if need_pytorch3d:\n",
|
"if need_pytorch3d:\n",
|
||||||
|
" if torch.__version__.startswith(\"1.11.\") and sys.platform.startswith(\"linux\"):\n",
|
||||||
|
" # We try to install PyTorch3D via a released wheel.\n",
|
||||||
|
" pyt_version_str=torch.__version__.split(\"+\")[0].replace(\".\", \"\")\n",
|
||||||
|
" version_str=\"\".join([\n",
|
||||||
|
" f\"py3{sys.version_info.minor}_cu\",\n",
|
||||||
|
" torch.version.cuda.replace(\".\",\"\"),\n",
|
||||||
|
" f\"_pyt{pyt_version_str}\"\n",
|
||||||
|
" ])\n",
|
||||||
|
" !pip install fvcore iopath\n",
|
||||||
|
" !pip install --no-index --no-cache-dir pytorch3d -f https://dl.fbaipublicfiles.com/pytorch3d/packaging/wheels/{version_str}/download.html\n",
|
||||||
|
" else:\n",
|
||||||
|
" # We try to install PyTorch3D from source.\n",
|
||||||
" !curl -LO https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz\n",
|
" !curl -LO https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz\n",
|
||||||
" !tar xzf 1.10.0.tar.gz\n",
|
" !tar xzf 1.10.0.tar.gz\n",
|
||||||
" os.environ[\"CUB_HOME\"] = os.getcwd() + \"/cub-1.10.0\"\n",
|
" os.environ[\"CUB_HOME\"] = os.getcwd() + \"/cub-1.10.0\"\n",
|
||||||
@@ -70,7 +78,6 @@
|
|||||||
"import torch\n",
|
"import torch\n",
|
||||||
"import torch.nn.functional as F\n",
|
"import torch.nn.functional as F\n",
|
||||||
"import matplotlib.pyplot as plt\n",
|
"import matplotlib.pyplot as plt\n",
|
||||||
"from skimage.io import imread\n",
|
|
||||||
"\n",
|
"\n",
|
||||||
"# Util function for loading point clouds|\n",
|
"# Util function for loading point clouds|\n",
|
||||||
"import numpy as np\n",
|
"import numpy as np\n",
|
||||||
@@ -151,7 +158,7 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"## Create a renderer\n",
|
"## Create a renderer\n",
|
||||||
"\n",
|
"\n",
|
||||||
"A renderer in PyTorch3D is composed of a **rasterizer** and a **shader** which each have a number of subcomponents such as a **camera** (orthgraphic/perspective). Here we initialize some of these components and use default values for the rest.\n",
|
"A renderer in PyTorch3D is composed of a **rasterizer** and a **shader** which each have a number of subcomponents such as a **camera** (orthographic/perspective). Here we initialize some of these components and use default values for the rest.\n",
|
||||||
"\n",
|
"\n",
|
||||||
"In this example we will first create a **renderer** which uses an **orthographic camera**, and applies **alpha compositing**. Then we learn how to vary different components using the modular API. \n",
|
"In this example we will first create a **renderer** which uses an **orthographic camera**, and applies **alpha compositing**. Then we learn how to vary different components using the modular API. \n",
|
||||||
"\n",
|
"\n",
|
||||||
@@ -196,7 +203,6 @@
|
|||||||
"images = renderer(point_cloud)\n",
|
"images = renderer(point_cloud)\n",
|
||||||
"plt.figure(figsize=(10, 10))\n",
|
"plt.figure(figsize=(10, 10))\n",
|
||||||
"plt.imshow(images[0, ..., :3].cpu().numpy())\n",
|
"plt.imshow(images[0, ..., :3].cpu().numpy())\n",
|
||||||
"plt.grid(\"off\")\n",
|
|
||||||
"plt.axis(\"off\");"
|
"plt.axis(\"off\");"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -223,7 +229,6 @@
|
|||||||
"\n",
|
"\n",
|
||||||
"plt.figure(figsize=(10, 10))\n",
|
"plt.figure(figsize=(10, 10))\n",
|
||||||
"plt.imshow(images[0, ..., :3].cpu().numpy())\n",
|
"plt.imshow(images[0, ..., :3].cpu().numpy())\n",
|
||||||
"plt.grid(\"off\")\n",
|
|
||||||
"plt.axis(\"off\");"
|
"plt.axis(\"off\");"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -271,7 +276,6 @@
|
|||||||
"images = renderer(point_cloud)\n",
|
"images = renderer(point_cloud)\n",
|
||||||
"plt.figure(figsize=(10, 10))\n",
|
"plt.figure(figsize=(10, 10))\n",
|
||||||
"plt.imshow(images[0, ..., :3].cpu().numpy())\n",
|
"plt.imshow(images[0, ..., :3].cpu().numpy())\n",
|
||||||
"plt.grid(\"off\")\n",
|
|
||||||
"plt.axis(\"off\");"
|
"plt.axis(\"off\");"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -297,7 +301,6 @@
|
|||||||
"images = renderer(point_cloud)\n",
|
"images = renderer(point_cloud)\n",
|
||||||
"plt.figure(figsize=(10, 10))\n",
|
"plt.figure(figsize=(10, 10))\n",
|
||||||
"plt.imshow(images[0, ..., :3].cpu().numpy())\n",
|
"plt.imshow(images[0, ..., :3].cpu().numpy())\n",
|
||||||
"plt.grid(\"off\")\n",
|
|
||||||
"plt.axis(\"off\");"
|
"plt.axis(\"off\");"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -330,7 +333,6 @@
|
|||||||
" bg_col=torch.tensor([0.0, 1.0, 0.0, 1.0], dtype=torch.float32, device=device))\n",
|
" bg_col=torch.tensor([0.0, 1.0, 0.0, 1.0], dtype=torch.float32, device=device))\n",
|
||||||
"plt.figure(figsize=(10, 10))\n",
|
"plt.figure(figsize=(10, 10))\n",
|
||||||
"plt.imshow(images[0, ..., :3].cpu().numpy())\n",
|
"plt.imshow(images[0, ..., :3].cpu().numpy())\n",
|
||||||
"plt.grid(\"off\")\n",
|
|
||||||
"plt.axis(\"off\");"
|
"plt.axis(\"off\");"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
|
|||||||
@@ -6,7 +6,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved."
|
"# Copyright (c) Meta Platforms, Inc. and affiliates. All rights reserved."
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -39,7 +39,7 @@
|
|||||||
"cell_type": "markdown",
|
"cell_type": "markdown",
|
||||||
"metadata": {},
|
"metadata": {},
|
||||||
"source": [
|
"source": [
|
||||||
"If torch, torchvision and PyTorch3D are not installed, run the following cell:"
|
"Ensure `torch` and `torchvision` are installed. If `pytorch3d` is not installed, install it using the following cell:"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -48,19 +48,27 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"!pip install torch torchvision\n",
|
|
||||||
"import os\n",
|
"import os\n",
|
||||||
"import sys\n",
|
"import sys\n",
|
||||||
"import torch\n",
|
"import torch\n",
|
||||||
"if torch.__version__=='1.6.0+cu101' and sys.platform.startswith('linux'):\n",
|
|
||||||
" !pip install pytorch3d\n",
|
|
||||||
"else:\n",
|
|
||||||
"need_pytorch3d=False\n",
|
"need_pytorch3d=False\n",
|
||||||
"try:\n",
|
"try:\n",
|
||||||
" import pytorch3d\n",
|
" import pytorch3d\n",
|
||||||
"except ModuleNotFoundError:\n",
|
"except ModuleNotFoundError:\n",
|
||||||
" need_pytorch3d=True\n",
|
" need_pytorch3d=True\n",
|
||||||
"if need_pytorch3d:\n",
|
"if need_pytorch3d:\n",
|
||||||
|
" if torch.__version__.startswith(\"1.11.\") and sys.platform.startswith(\"linux\"):\n",
|
||||||
|
" # We try to install PyTorch3D via a released wheel.\n",
|
||||||
|
" pyt_version_str=torch.__version__.split(\"+\")[0].replace(\".\", \"\")\n",
|
||||||
|
" version_str=\"\".join([\n",
|
||||||
|
" f\"py3{sys.version_info.minor}_cu\",\n",
|
||||||
|
" torch.version.cuda.replace(\".\",\"\"),\n",
|
||||||
|
" f\"_pyt{pyt_version_str}\"\n",
|
||||||
|
" ])\n",
|
||||||
|
" !pip install fvcore iopath\n",
|
||||||
|
" !pip install --no-index --no-cache-dir pytorch3d -f https://dl.fbaipublicfiles.com/pytorch3d/packaging/wheels/{version_str}/download.html\n",
|
||||||
|
" else:\n",
|
||||||
|
" # We try to install PyTorch3D from source.\n",
|
||||||
" !curl -LO https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz\n",
|
" !curl -LO https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz\n",
|
||||||
" !tar xzf 1.10.0.tar.gz\n",
|
" !tar xzf 1.10.0.tar.gz\n",
|
||||||
" os.environ[\"CUB_HOME\"] = os.getcwd() + \"/cub-1.10.0\"\n",
|
" os.environ[\"CUB_HOME\"] = os.getcwd() + \"/cub-1.10.0\"\n",
|
||||||
@@ -86,12 +94,11 @@
|
|||||||
"import os\n",
|
"import os\n",
|
||||||
"import torch\n",
|
"import torch\n",
|
||||||
"import matplotlib.pyplot as plt\n",
|
"import matplotlib.pyplot as plt\n",
|
||||||
"from skimage.io import imread\n",
|
|
||||||
"import numpy as np\n",
|
"import numpy as np\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# libraries for reading data from files\n",
|
"# libraries for reading data from files\n",
|
||||||
"from scipy.io import loadmat\n",
|
"from scipy.io import loadmat\n",
|
||||||
"from pytorch3d.io.utils import _read_image\n",
|
"from PIL import Image\n",
|
||||||
"import pickle\n",
|
"import pickle\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# Data structures and functions for rendering\n",
|
"# Data structures and functions for rendering\n",
|
||||||
@@ -178,13 +185,15 @@
|
|||||||
" data = pickle.load(f, encoding='latin1') \n",
|
" data = pickle.load(f, encoding='latin1') \n",
|
||||||
" v_template = torch.Tensor(data['v_template']).to(device) # (6890, 3)\n",
|
" v_template = torch.Tensor(data['v_template']).to(device) # (6890, 3)\n",
|
||||||
"ALP_UV = loadmat(data_filename)\n",
|
"ALP_UV = loadmat(data_filename)\n",
|
||||||
"tex = torch.from_numpy(_read_image(file_name=tex_filename, format='RGB') / 255. ).unsqueeze(0).to(device)\n",
|
"with Image.open(tex_filename) as image:\n",
|
||||||
|
" np_image = np.asarray(image.convert(\"RGB\")).astype(np.float32)\n",
|
||||||
|
"tex = torch.from_numpy(np_image / 255.)[None].to(device)\n",
|
||||||
"\n",
|
"\n",
|
||||||
"verts = torch.from_numpy((ALP_UV[\"All_vertices\"]).astype(int)).squeeze().to(device) # (7829, 1)\n",
|
"verts = torch.from_numpy((ALP_UV[\"All_vertices\"]).astype(int)).squeeze().to(device) # (7829,)\n",
|
||||||
"U = torch.Tensor(ALP_UV['All_U_norm']).to(device) # (7829, 1)\n",
|
"U = torch.Tensor(ALP_UV['All_U_norm']).to(device) # (7829, 1)\n",
|
||||||
"V = torch.Tensor(ALP_UV['All_V_norm']).to(device) # (7829, 1)\n",
|
"V = torch.Tensor(ALP_UV['All_V_norm']).to(device) # (7829, 1)\n",
|
||||||
"faces = torch.from_numpy((ALP_UV['All_Faces'] - 1).astype(int)).to(device) # (13774, 3)\n",
|
"faces = torch.from_numpy((ALP_UV['All_Faces'] - 1).astype(int)).to(device) # (13774, 3)\n",
|
||||||
"face_indices = torch.Tensor(ALP_UV['All_FaceIndices']).squeeze()"
|
"face_indices = torch.Tensor(ALP_UV['All_FaceIndices']).squeeze() # (13774,)"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -196,7 +205,6 @@
|
|||||||
"# Display the texture image\n",
|
"# Display the texture image\n",
|
||||||
"plt.figure(figsize=(10, 10))\n",
|
"plt.figure(figsize=(10, 10))\n",
|
||||||
"plt.imshow(tex.squeeze(0).cpu())\n",
|
"plt.imshow(tex.squeeze(0).cpu())\n",
|
||||||
"plt.grid(\"off\");\n",
|
|
||||||
"plt.axis(\"off\");"
|
"plt.axis(\"off\");"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -222,6 +230,9 @@
|
|||||||
" part = rows * i + j + 1 # parts are 1-indexed in face_indices\n",
|
" part = rows * i + j + 1 # parts are 1-indexed in face_indices\n",
|
||||||
" offset_per_part[part] = (u, v)\n",
|
" offset_per_part[part] = (u, v)\n",
|
||||||
"\n",
|
"\n",
|
||||||
|
"U_norm = U.clone()\n",
|
||||||
|
"V_norm = V.clone()\n",
|
||||||
|
"\n",
|
||||||
"# iterate over faces and offset the corresponding vertex u and v values\n",
|
"# iterate over faces and offset the corresponding vertex u and v values\n",
|
||||||
"for i in range(len(faces)):\n",
|
"for i in range(len(faces)):\n",
|
||||||
" face_vert_idxs = faces[i]\n",
|
" face_vert_idxs = faces[i]\n",
|
||||||
@@ -232,15 +243,15 @@
|
|||||||
" # vertices are reused, but we don't want to offset multiple times\n",
|
" # vertices are reused, but we don't want to offset multiple times\n",
|
||||||
" if vert_idx.item() not in already_offset:\n",
|
" if vert_idx.item() not in already_offset:\n",
|
||||||
" # offset u value\n",
|
" # offset u value\n",
|
||||||
" U[vert_idx] = U[vert_idx] / cols + offset_u\n",
|
" U_norm[vert_idx] = U[vert_idx] / cols + offset_u\n",
|
||||||
" # offset v value\n",
|
" # offset v value\n",
|
||||||
" # this also flips each part locally, as each part is upside down\n",
|
" # this also flips each part locally, as each part is upside down\n",
|
||||||
" V[vert_idx] = (1 - V[vert_idx]) / rows + offset_v\n",
|
" V_norm[vert_idx] = (1 - V[vert_idx]) / rows + offset_v\n",
|
||||||
" # add vertex to our set tracking offsetted vertices\n",
|
" # add vertex to our set tracking offsetted vertices\n",
|
||||||
" already_offset.add(vert_idx.item())\n",
|
" already_offset.add(vert_idx.item())\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# invert V values\n",
|
"# invert V values\n",
|
||||||
"U_norm, V_norm = U, 1 - V"
|
"V_norm = 1 - V_norm"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -257,10 +268,7 @@
|
|||||||
"# Therefore when initializing the Meshes class,\n",
|
"# Therefore when initializing the Meshes class,\n",
|
||||||
"# we need to map each of the vertices referenced by the DensePose faces (in verts, which is the \"All_vertices\" field)\n",
|
"# we need to map each of the vertices referenced by the DensePose faces (in verts, which is the \"All_vertices\" field)\n",
|
||||||
"# to the correct xyz coordinate in the SMPL template mesh.\n",
|
"# to the correct xyz coordinate in the SMPL template mesh.\n",
|
||||||
"v_template_extended = torch.stack(list(map(lambda vert: v_template[vert-1], verts))).unsqueeze(0).to(device) # (1, 7829, 3)\n",
|
"v_template_extended = v_template[verts-1][None] # (1, 7829, 3)"
|
||||||
"\n",
|
|
||||||
"# add a batch dimension to faces\n",
|
|
||||||
"faces = faces.unsqueeze(0)"
|
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -271,7 +279,7 @@
|
|||||||
"\n",
|
"\n",
|
||||||
"**Meshes** is a unique datastructure provided in PyTorch3D for working with batches of meshes of different sizes.\n",
|
"**Meshes** is a unique datastructure provided in PyTorch3D for working with batches of meshes of different sizes.\n",
|
||||||
"\n",
|
"\n",
|
||||||
"**TexturesUV** is an auxillary datastructure for storing vertex uv and texture maps for meshes."
|
"**TexturesUV** is an auxiliary datastructure for storing vertex uv and texture maps for meshes."
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -280,8 +288,8 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"texture = TexturesUV(maps=tex, faces_uvs=faces, verts_uvs=verts_uv)\n",
|
"texture = TexturesUV(maps=tex, faces_uvs=faces[None], verts_uvs=verts_uv)\n",
|
||||||
"mesh = Meshes(v_template_extended, faces, texture)"
|
"mesh = Meshes(v_template_extended, faces[None], texture)"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -314,7 +322,7 @@
|
|||||||
"# Place a point light in front of the person. \n",
|
"# Place a point light in front of the person. \n",
|
||||||
"lights = PointLights(device=device, location=[[0.0, 0.0, 2.0]])\n",
|
"lights = PointLights(device=device, location=[[0.0, 0.0, 2.0]])\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# Create a phong renderer by composing a rasterizer and a shader. The textured phong shader will \n",
|
"# Create a Phong renderer by composing a rasterizer and a shader. The textured Phong shader will \n",
|
||||||
"# interpolate the texture uv coordinates for each vertex, sample from a texture image and \n",
|
"# interpolate the texture uv coordinates for each vertex, sample from a texture image and \n",
|
||||||
"# apply the Phong lighting model\n",
|
"# apply the Phong lighting model\n",
|
||||||
"renderer = MeshRenderer(\n",
|
"renderer = MeshRenderer(\n",
|
||||||
@@ -346,7 +354,6 @@
|
|||||||
"images = renderer(mesh)\n",
|
"images = renderer(mesh)\n",
|
||||||
"plt.figure(figsize=(10, 10))\n",
|
"plt.figure(figsize=(10, 10))\n",
|
||||||
"plt.imshow(images[0, ..., :3].cpu().numpy())\n",
|
"plt.imshow(images[0, ..., :3].cpu().numpy())\n",
|
||||||
"plt.grid(\"off\");\n",
|
|
||||||
"plt.axis(\"off\");"
|
"plt.axis(\"off\");"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -387,7 +394,6 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"plt.figure(figsize=(10, 10))\n",
|
"plt.figure(figsize=(10, 10))\n",
|
||||||
"plt.imshow(images[0, ..., :3].cpu().numpy())\n",
|
"plt.imshow(images[0, ..., :3].cpu().numpy())\n",
|
||||||
"plt.grid(\"off\");\n",
|
|
||||||
"plt.axis(\"off\");"
|
"plt.axis(\"off\");"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
|
|||||||
@@ -10,7 +10,7 @@
|
|||||||
},
|
},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved."
|
"# Copyright (c) Meta Platforms, Inc. and affiliates. All rights reserved."
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -47,7 +47,7 @@
|
|||||||
"id": "okLalbR_g7NS"
|
"id": "okLalbR_g7NS"
|
||||||
},
|
},
|
||||||
"source": [
|
"source": [
|
||||||
"If `torch`, `torchvision` and `pytorch3d` are not installed, run the following cell:"
|
"Ensure `torch` and `torchvision` are installed. If `pytorch3d` is not installed, install it using the following cell:"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -64,19 +64,27 @@
|
|||||||
},
|
},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"!pip install torch torchvision\n",
|
|
||||||
"import os\n",
|
"import os\n",
|
||||||
"import sys\n",
|
"import sys\n",
|
||||||
"import torch\n",
|
"import torch\n",
|
||||||
"if torch.__version__=='1.6.0+cu101' and sys.platform.startswith('linux'):\n",
|
|
||||||
" !pip install pytorch3d\n",
|
|
||||||
"else:\n",
|
|
||||||
"need_pytorch3d=False\n",
|
"need_pytorch3d=False\n",
|
||||||
"try:\n",
|
"try:\n",
|
||||||
" import pytorch3d\n",
|
" import pytorch3d\n",
|
||||||
"except ModuleNotFoundError:\n",
|
"except ModuleNotFoundError:\n",
|
||||||
" need_pytorch3d=True\n",
|
" need_pytorch3d=True\n",
|
||||||
"if need_pytorch3d:\n",
|
"if need_pytorch3d:\n",
|
||||||
|
" if torch.__version__.startswith(\"1.11.\") and sys.platform.startswith(\"linux\"):\n",
|
||||||
|
" # We try to install PyTorch3D via a released wheel.\n",
|
||||||
|
" pyt_version_str=torch.__version__.split(\"+\")[0].replace(\".\", \"\")\n",
|
||||||
|
" version_str=\"\".join([\n",
|
||||||
|
" f\"py3{sys.version_info.minor}_cu\",\n",
|
||||||
|
" torch.version.cuda.replace(\".\",\"\"),\n",
|
||||||
|
" f\"_pyt{pyt_version_str}\"\n",
|
||||||
|
" ])\n",
|
||||||
|
" !pip install fvcore iopath\n",
|
||||||
|
" !pip install --no-index --no-cache-dir pytorch3d -f https://dl.fbaipublicfiles.com/pytorch3d/packaging/wheels/{version_str}/download.html\n",
|
||||||
|
" else:\n",
|
||||||
|
" # We try to install PyTorch3D from source.\n",
|
||||||
" !curl -LO https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz\n",
|
" !curl -LO https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz\n",
|
||||||
" !tar xzf 1.10.0.tar.gz\n",
|
" !tar xzf 1.10.0.tar.gz\n",
|
||||||
" os.environ[\"CUB_HOME\"] = os.getcwd() + \"/cub-1.10.0\"\n",
|
" os.environ[\"CUB_HOME\"] = os.getcwd() + \"/cub-1.10.0\"\n",
|
||||||
@@ -96,7 +104,6 @@
|
|||||||
"import os\n",
|
"import os\n",
|
||||||
"import torch\n",
|
"import torch\n",
|
||||||
"import matplotlib.pyplot as plt\n",
|
"import matplotlib.pyplot as plt\n",
|
||||||
"from skimage.io import imread\n",
|
|
||||||
"\n",
|
"\n",
|
||||||
"# Util function for loading meshes\n",
|
"# Util function for loading meshes\n",
|
||||||
"from pytorch3d.io import load_objs_as_meshes, load_obj\n",
|
"from pytorch3d.io import load_objs_as_meshes, load_obj\n",
|
||||||
@@ -149,7 +156,7 @@
|
|||||||
},
|
},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"!wget https://raw.githubusercontent.com/facebookresearch/pytorch3d/master/docs/tutorials/utils/plot_image_grid.py\n",
|
"!wget https://raw.githubusercontent.com/facebookresearch/pytorch3d/main/docs/tutorials/utils/plot_image_grid.py\n",
|
||||||
"from plot_image_grid import image_grid"
|
"from plot_image_grid import image_grid"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -185,11 +192,11 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"### 1. Load a mesh and texture file\n",
|
"### 1. Load a mesh and texture file\n",
|
||||||
"\n",
|
"\n",
|
||||||
"Load an `.obj` file and it's associated `.mtl` file and create a **Textures** and **Meshes** object. \n",
|
"Load an `.obj` file and its associated `.mtl` file and create a **Textures** and **Meshes** object. \n",
|
||||||
"\n",
|
"\n",
|
||||||
"**Meshes** is a unique datastructure provided in PyTorch3D for working with batches of meshes of different sizes. \n",
|
"**Meshes** is a unique datastructure provided in PyTorch3D for working with batches of meshes of different sizes. \n",
|
||||||
"\n",
|
"\n",
|
||||||
"**TexturesUV** is an auxillary datastructure for storing vertex uv and texture maps for meshes. \n",
|
"**TexturesUV** is an auxiliary datastructure for storing vertex uv and texture maps for meshes. \n",
|
||||||
"\n",
|
"\n",
|
||||||
"**Meshes** has several class methods which are used throughout the rendering pipeline."
|
"**Meshes** has several class methods which are used throughout the rendering pipeline."
|
||||||
]
|
]
|
||||||
@@ -277,7 +284,6 @@
|
|||||||
"plt.figure(figsize=(7,7))\n",
|
"plt.figure(figsize=(7,7))\n",
|
||||||
"texture_image=mesh.textures.maps_padded()\n",
|
"texture_image=mesh.textures.maps_padded()\n",
|
||||||
"plt.imshow(texture_image.squeeze().cpu().numpy())\n",
|
"plt.imshow(texture_image.squeeze().cpu().numpy())\n",
|
||||||
"plt.grid(\"off\");\n",
|
|
||||||
"plt.axis(\"off\");"
|
"plt.axis(\"off\");"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -296,7 +302,6 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"plt.figure(figsize=(7,7))\n",
|
"plt.figure(figsize=(7,7))\n",
|
||||||
"texturesuv_image_matplotlib(mesh.textures, subsample=None)\n",
|
"texturesuv_image_matplotlib(mesh.textures, subsample=None)\n",
|
||||||
"plt.grid(\"off\");\n",
|
|
||||||
"plt.axis(\"off\");"
|
"plt.axis(\"off\");"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -311,7 +316,7 @@
|
|||||||
"\n",
|
"\n",
|
||||||
"A renderer in PyTorch3D is composed of a **rasterizer** and a **shader** which each have a number of subcomponents such as a **camera** (orthographic/perspective). Here we initialize some of these components and use default values for the rest.\n",
|
"A renderer in PyTorch3D is composed of a **rasterizer** and a **shader** which each have a number of subcomponents such as a **camera** (orthographic/perspective). Here we initialize some of these components and use default values for the rest.\n",
|
||||||
"\n",
|
"\n",
|
||||||
"In this example we will first create a **renderer** which uses a **perspective camera**, a **point light** and applies **phong shading**. Then we learn how to vary different components using the modular API. "
|
"In this example we will first create a **renderer** which uses a **perspective camera**, a **point light** and applies **Phong shading**. Then we learn how to vary different components using the modular API. "
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -346,7 +351,7 @@
|
|||||||
"# -z direction. \n",
|
"# -z direction. \n",
|
||||||
"lights = PointLights(device=device, location=[[0.0, 0.0, -3.0]])\n",
|
"lights = PointLights(device=device, location=[[0.0, 0.0, -3.0]])\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# Create a phong renderer by composing a rasterizer and a shader. The textured phong shader will \n",
|
"# Create a Phong renderer by composing a rasterizer and a shader. The textured Phong shader will \n",
|
||||||
"# interpolate the texture uv coordinates for each vertex, sample from a texture image and \n",
|
"# interpolate the texture uv coordinates for each vertex, sample from a texture image and \n",
|
||||||
"# apply the Phong lighting model\n",
|
"# apply the Phong lighting model\n",
|
||||||
"renderer = MeshRenderer(\n",
|
"renderer = MeshRenderer(\n",
|
||||||
@@ -399,7 +404,6 @@
|
|||||||
"images = renderer(mesh)\n",
|
"images = renderer(mesh)\n",
|
||||||
"plt.figure(figsize=(10, 10))\n",
|
"plt.figure(figsize=(10, 10))\n",
|
||||||
"plt.imshow(images[0, ..., :3].cpu().numpy())\n",
|
"plt.imshow(images[0, ..., :3].cpu().numpy())\n",
|
||||||
"plt.grid(\"off\");\n",
|
|
||||||
"plt.axis(\"off\");"
|
"plt.axis(\"off\");"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -412,7 +416,7 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"## 4. Move the light behind the object and re-render\n",
|
"## 4. Move the light behind the object and re-render\n",
|
||||||
"\n",
|
"\n",
|
||||||
"We can pass arbirary keyword arguments to the `rasterizer`/`shader` via the call to the `renderer` so the renderer does not need to be reinitialized if any of the settings change/\n",
|
"We can pass arbitrary keyword arguments to the `rasterizer`/`shader` via the call to the `renderer` so the renderer does not need to be reinitialized if any of the settings change/\n",
|
||||||
"\n",
|
"\n",
|
||||||
"In this case, we can simply update the location of the lights and pass them into the call to the renderer. \n",
|
"In this case, we can simply update the location of the lights and pass them into the call to the renderer. \n",
|
||||||
"\n",
|
"\n",
|
||||||
@@ -450,7 +454,6 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"plt.figure(figsize=(10, 10))\n",
|
"plt.figure(figsize=(10, 10))\n",
|
||||||
"plt.imshow(images[0, ..., :3].cpu().numpy())\n",
|
"plt.imshow(images[0, ..., :3].cpu().numpy())\n",
|
||||||
"plt.grid(\"off\");\n",
|
|
||||||
"plt.axis(\"off\");"
|
"plt.axis(\"off\");"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -514,7 +517,6 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"plt.figure(figsize=(10, 10))\n",
|
"plt.figure(figsize=(10, 10))\n",
|
||||||
"plt.imshow(images[0, ..., :3].cpu().numpy())\n",
|
"plt.imshow(images[0, ..., :3].cpu().numpy())\n",
|
||||||
"plt.grid(\"off\");\n",
|
|
||||||
"plt.axis(\"off\");"
|
"plt.axis(\"off\");"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -573,7 +575,7 @@
|
|||||||
},
|
},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"# We can pass arbirary keyword arguments to the rasterizer/shader via the renderer\n",
|
"# We can pass arbitrary keyword arguments to the rasterizer/shader via the renderer\n",
|
||||||
"# so the renderer does not need to be reinitialized if any of the settings change.\n",
|
"# so the renderer does not need to be reinitialized if any of the settings change.\n",
|
||||||
"images = renderer(meshes, cameras=cameras, lights=lights)"
|
"images = renderer(meshes, cameras=cameras, lights=lights)"
|
||||||
]
|
]
|
||||||
|
|||||||
@@ -1,4 +1,8 @@
|
|||||||
# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
from .camera_visualization import get_camera_wireframe, plot_camera_scene, plot_cameras
|
from .camera_visualization import get_camera_wireframe, plot_camera_scene, plot_cameras
|
||||||
from .plot_image_grid import image_grid
|
from .plot_image_grid import image_grid
|
||||||
|
|||||||
@@ -1,4 +1,8 @@
|
|||||||
# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
import matplotlib.pyplot as plt
|
import matplotlib.pyplot as plt
|
||||||
from mpl_toolkits.mplot3d import Axes3D # noqa: F401 unused import
|
from mpl_toolkits.mplot3d import Axes3D # noqa: F401 unused import
|
||||||
|
|||||||
167
docs/tutorials/utils/generate_cow_renders.py
Normal file
167
docs/tutorials/utils/generate_cow_renders.py
Normal file
@@ -0,0 +1,167 @@
|
|||||||
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
|
import os
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import torch
|
||||||
|
from pytorch3d.io import load_objs_as_meshes
|
||||||
|
from pytorch3d.renderer import (
|
||||||
|
BlendParams,
|
||||||
|
FoVPerspectiveCameras,
|
||||||
|
look_at_view_transform,
|
||||||
|
MeshRasterizer,
|
||||||
|
MeshRenderer,
|
||||||
|
PointLights,
|
||||||
|
RasterizationSettings,
|
||||||
|
SoftPhongShader,
|
||||||
|
SoftSilhouetteShader,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
# create the default data directory
|
||||||
|
current_dir = os.path.dirname(os.path.realpath(__file__))
|
||||||
|
DATA_DIR = os.path.join(current_dir, "..", "data", "cow_mesh")
|
||||||
|
|
||||||
|
|
||||||
|
def generate_cow_renders(
|
||||||
|
num_views: int = 40, data_dir: str = DATA_DIR, azimuth_range: float = 180
|
||||||
|
):
|
||||||
|
"""
|
||||||
|
This function generates `num_views` renders of a cow mesh.
|
||||||
|
The renders are generated from viewpoints sampled at uniformly distributed
|
||||||
|
azimuth intervals. The elevation is kept constant so that the camera's
|
||||||
|
vertical position coincides with the equator.
|
||||||
|
|
||||||
|
For a more detailed explanation of this code, please refer to the
|
||||||
|
docs/tutorials/fit_textured_mesh.ipynb notebook.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
num_views: The number of generated renders.
|
||||||
|
data_dir: The folder that contains the cow mesh files. If the cow mesh
|
||||||
|
files do not exist in the folder, this function will automatically
|
||||||
|
download them.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
cameras: A batch of `num_views` `FoVPerspectiveCameras` from which the
|
||||||
|
images are rendered.
|
||||||
|
images: A tensor of shape `(num_views, height, width, 3)` containing
|
||||||
|
the rendered images.
|
||||||
|
silhouettes: A tensor of shape `(num_views, height, width)` containing
|
||||||
|
the rendered silhouettes.
|
||||||
|
"""
|
||||||
|
|
||||||
|
# set the paths
|
||||||
|
|
||||||
|
# download the cow mesh if not done before
|
||||||
|
cow_mesh_files = [
|
||||||
|
os.path.join(data_dir, fl) for fl in ("cow.obj", "cow.mtl", "cow_texture.png")
|
||||||
|
]
|
||||||
|
if any(not os.path.isfile(f) for f in cow_mesh_files):
|
||||||
|
os.makedirs(data_dir, exist_ok=True)
|
||||||
|
os.system(
|
||||||
|
f"wget -P {data_dir} "
|
||||||
|
+ "https://dl.fbaipublicfiles.com/pytorch3d/data/cow_mesh/cow.obj"
|
||||||
|
)
|
||||||
|
os.system(
|
||||||
|
f"wget -P {data_dir} "
|
||||||
|
+ "https://dl.fbaipublicfiles.com/pytorch3d/data/cow_mesh/cow.mtl"
|
||||||
|
)
|
||||||
|
os.system(
|
||||||
|
f"wget -P {data_dir} "
|
||||||
|
+ "https://dl.fbaipublicfiles.com/pytorch3d/data/cow_mesh/cow_texture.png"
|
||||||
|
)
|
||||||
|
|
||||||
|
# Setup
|
||||||
|
if torch.cuda.is_available():
|
||||||
|
device = torch.device("cuda:0")
|
||||||
|
torch.cuda.set_device(device)
|
||||||
|
else:
|
||||||
|
device = torch.device("cpu")
|
||||||
|
|
||||||
|
# Load obj file
|
||||||
|
obj_filename = os.path.join(data_dir, "cow.obj")
|
||||||
|
mesh = load_objs_as_meshes([obj_filename], device=device)
|
||||||
|
|
||||||
|
# We scale normalize and center the target mesh to fit in a sphere of radius 1
|
||||||
|
# centered at (0,0,0). (scale, center) will be used to bring the predicted mesh
|
||||||
|
# to its original center and scale. Note that normalizing the target mesh,
|
||||||
|
# speeds up the optimization but is not necessary!
|
||||||
|
verts = mesh.verts_packed()
|
||||||
|
N = verts.shape[0]
|
||||||
|
center = verts.mean(0)
|
||||||
|
scale = max((verts - center).abs().max(0)[0])
|
||||||
|
mesh.offset_verts_(-(center.expand(N, 3)))
|
||||||
|
mesh.scale_verts_((1.0 / float(scale)))
|
||||||
|
|
||||||
|
# Get a batch of viewing angles.
|
||||||
|
elev = torch.linspace(0, 0, num_views) # keep constant
|
||||||
|
azim = torch.linspace(-azimuth_range, azimuth_range, num_views) + 180.0
|
||||||
|
|
||||||
|
# Place a point light in front of the object. As mentioned above, the front of
|
||||||
|
# the cow is facing the -z direction.
|
||||||
|
lights = PointLights(device=device, location=[[0.0, 0.0, -3.0]])
|
||||||
|
|
||||||
|
# Initialize an OpenGL perspective camera that represents a batch of different
|
||||||
|
# viewing angles. All the cameras helper methods support mixed type inputs and
|
||||||
|
# broadcasting. So we can view the camera from the a distance of dist=2.7, and
|
||||||
|
# then specify elevation and azimuth angles for each viewpoint as tensors.
|
||||||
|
R, T = look_at_view_transform(dist=2.7, elev=elev, azim=azim)
|
||||||
|
cameras = FoVPerspectiveCameras(device=device, R=R, T=T)
|
||||||
|
|
||||||
|
# Define the settings for rasterization and shading. Here we set the output
|
||||||
|
# image to be of size 128X128. As we are rendering images for visualization
|
||||||
|
# purposes only we will set faces_per_pixel=1 and blur_radius=0.0. Refer to
|
||||||
|
# rasterize_meshes.py for explanations of these parameters. We also leave
|
||||||
|
# bin_size and max_faces_per_bin to their default values of None, which sets
|
||||||
|
# their values using heuristics and ensures that the faster coarse-to-fine
|
||||||
|
# rasterization method is used. Refer to docs/notes/renderer.md for an
|
||||||
|
# explanation of the difference between naive and coarse-to-fine rasterization.
|
||||||
|
raster_settings = RasterizationSettings(
|
||||||
|
image_size=128, blur_radius=0.0, faces_per_pixel=1
|
||||||
|
)
|
||||||
|
|
||||||
|
# Create a Phong renderer by composing a rasterizer and a shader. The textured
|
||||||
|
# Phong shader will interpolate the texture uv coordinates for each vertex,
|
||||||
|
# sample from a texture image and apply the Phong lighting model
|
||||||
|
blend_params = BlendParams(sigma=1e-4, gamma=1e-4, background_color=(0.0, 0.0, 0.0))
|
||||||
|
renderer = MeshRenderer(
|
||||||
|
rasterizer=MeshRasterizer(cameras=cameras, raster_settings=raster_settings),
|
||||||
|
shader=SoftPhongShader(
|
||||||
|
device=device, cameras=cameras, lights=lights, blend_params=blend_params
|
||||||
|
),
|
||||||
|
)
|
||||||
|
|
||||||
|
# Create a batch of meshes by repeating the cow mesh and associated textures.
|
||||||
|
# Meshes has a useful `extend` method which allows us do this very easily.
|
||||||
|
# This also extends the textures.
|
||||||
|
meshes = mesh.extend(num_views)
|
||||||
|
|
||||||
|
# Render the cow mesh from each viewing angle
|
||||||
|
target_images = renderer(meshes, cameras=cameras, lights=lights)
|
||||||
|
|
||||||
|
# Rasterization settings for silhouette rendering
|
||||||
|
sigma = 1e-4
|
||||||
|
raster_settings_silhouette = RasterizationSettings(
|
||||||
|
image_size=128, blur_radius=np.log(1.0 / 1e-4 - 1.0) * sigma, faces_per_pixel=50
|
||||||
|
)
|
||||||
|
|
||||||
|
# Silhouette renderer
|
||||||
|
renderer_silhouette = MeshRenderer(
|
||||||
|
rasterizer=MeshRasterizer(
|
||||||
|
cameras=cameras, raster_settings=raster_settings_silhouette
|
||||||
|
),
|
||||||
|
shader=SoftSilhouetteShader(),
|
||||||
|
)
|
||||||
|
|
||||||
|
# Render silhouette images. The 3rd channel of the rendering output is
|
||||||
|
# the alpha/silhouette channel
|
||||||
|
silhouette_images = renderer_silhouette(meshes, cameras=cameras, lights=lights)
|
||||||
|
|
||||||
|
# binary silhouettes
|
||||||
|
silhouette_binary = (silhouette_images[..., 3] > 1e-4).float()
|
||||||
|
|
||||||
|
return cameras, target_images[..., :3], silhouette_binary
|
||||||
@@ -1,4 +1,8 @@
|
|||||||
# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
import matplotlib.pyplot as plt
|
import matplotlib.pyplot as plt
|
||||||
|
|
||||||
|
|||||||
@@ -1,5 +1,10 @@
|
|||||||
#!/bin/bash
|
#!/bin/bash
|
||||||
# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
set -ex
|
set -ex
|
||||||
|
|
||||||
script_dir="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )"
|
script_dir="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )"
|
||||||
@@ -16,5 +21,14 @@ export SOURCE_ROOT_DIR="$PWD"
|
|||||||
setup_conda_pytorch_constraint
|
setup_conda_pytorch_constraint
|
||||||
setup_conda_cudatoolkit_constraint
|
setup_conda_cudatoolkit_constraint
|
||||||
setup_visual_studio_constraint
|
setup_visual_studio_constraint
|
||||||
|
|
||||||
|
if [[ "$JUST_TESTRUN" == "1" ]]
|
||||||
|
then
|
||||||
|
# We are not building for other users, we
|
||||||
|
# are only trying to see if the tests pass.
|
||||||
|
# So save time by only building for our own GPU.
|
||||||
|
unset NVCC_FLAGS
|
||||||
|
fi
|
||||||
|
|
||||||
# shellcheck disable=SC2086
|
# shellcheck disable=SC2086
|
||||||
conda build $CONDA_CHANNEL_FLAGS ${TEST_FLAG:-} -c bottler -c defaults -c conda-forge --no-anaconda-upload -c fvcore --python "$PYTHON_VERSION" packaging/pytorch3d
|
conda build $CONDA_CHANNEL_FLAGS ${TEST_FLAG:-} -c bottler -c fvcore -c iopath -c conda-forge --no-anaconda-upload --python "$PYTHON_VERSION" packaging/pytorch3d
|
||||||
|
|||||||
@@ -1,5 +1,10 @@
|
|||||||
#!/bin/bash
|
#!/bin/bash
|
||||||
# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
set -ex
|
set -ex
|
||||||
|
|
||||||
script_dir="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )"
|
script_dir="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )"
|
||||||
|
|||||||
@@ -1,5 +1,10 @@
|
|||||||
#!/usr/bin/env bash
|
#!/usr/bin/env bash
|
||||||
# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
if [[ -x "/remote/anaconda_token" ]]; then
|
if [[ -x "/remote/anaconda_token" ]]; then
|
||||||
. /remote/anaconda_token || true
|
. /remote/anaconda_token || true
|
||||||
fi
|
fi
|
||||||
|
|||||||
@@ -1,2 +1,7 @@
|
|||||||
:: Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
@REM Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
@REM All rights reserved.
|
||||||
|
@REM
|
||||||
|
@REM This source code is licensed under the BSD-style license found in the
|
||||||
|
@REM LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
start /wait "" "%miniconda_exe%" /S /InstallationType=JustMe /RegisterPython=0 /AddToPath=0 /D=%tmp_conda%
|
start /wait "" "%miniconda_exe%" /S /InstallationType=JustMe /RegisterPython=0 /AddToPath=0 /D=%tmp_conda%
|
||||||
|
|||||||
@@ -1,5 +1,10 @@
|
|||||||
#!/usr/bin/env bash
|
#!/usr/bin/env bash
|
||||||
# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
if [[ "$OSTYPE" == "msys" ]]; then
|
if [[ "$OSTYPE" == "msys" ]]; then
|
||||||
CUDA_DIR="/c/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v$1"
|
CUDA_DIR="/c/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v$1"
|
||||||
else
|
else
|
||||||
|
|||||||
26
packaging/cub_conda/README.md
Normal file
26
packaging/cub_conda/README.md
Normal file
@@ -0,0 +1,26 @@
|
|||||||
|
## For building conda package for NVIDIA CUB
|
||||||
|
|
||||||
|
CUB is required for building PyTorch3D so it makes sense
|
||||||
|
to provide a conda package to make its header files available.
|
||||||
|
This directory is used to do that, it is independent of the rest
|
||||||
|
of this repo.
|
||||||
|
|
||||||
|
Make sure you are in a conda environment with
|
||||||
|
anaconda-client and conda-build installed.
|
||||||
|
|
||||||
|
From this directory, build the package with the following.
|
||||||
|
```
|
||||||
|
mkdir -p ./out
|
||||||
|
conda build --no-anaconda-upload --output-folder ./out cub
|
||||||
|
```
|
||||||
|
|
||||||
|
You can then upload the package with the following.
|
||||||
|
```
|
||||||
|
retry () {
|
||||||
|
# run a command, and try again if it fails
|
||||||
|
$* || (echo && sleep 8 && echo retrying && $*)
|
||||||
|
}
|
||||||
|
|
||||||
|
file=out/linux-64/nvidiacub-1.10.0-0.tar.bz2
|
||||||
|
retry anaconda --verbose -t ${TOKEN} upload -u pytorch3d --force ${file} --no-progress
|
||||||
|
```
|
||||||
12
packaging/cub_conda/cub/meta.yaml
Normal file
12
packaging/cub_conda/cub/meta.yaml
Normal file
@@ -0,0 +1,12 @@
|
|||||||
|
package:
|
||||||
|
name: nvidiacub
|
||||||
|
version: 1.10.0
|
||||||
|
source:
|
||||||
|
url: https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz
|
||||||
|
folder: source
|
||||||
|
build:
|
||||||
|
script: mkdir $PREFIX/include && cp -r source/cub $PREFIX/include/cub
|
||||||
|
|
||||||
|
about:
|
||||||
|
home: https://github.com/NVIDIA/cub
|
||||||
|
summary: CUB provides state-of-the-art, reusable software components for every layer of the CUDA programming model.
|
||||||
30
packaging/linux_wheels/README.md
Normal file
30
packaging/linux_wheels/README.md
Normal file
@@ -0,0 +1,30 @@
|
|||||||
|
## Building Linux pip Packages
|
||||||
|
|
||||||
|
1. Make sure this directory is on a filesystem which docker can
|
||||||
|
use - e.g. not NFS. If you are using a local hard drive there is
|
||||||
|
nothing to do here.
|
||||||
|
|
||||||
|
2. You may want to `docker pull pytorch/conda-cuda:latest`.
|
||||||
|
|
||||||
|
3. Run `bash go.sh` in this directory. This takes ages
|
||||||
|
and writes packages to `inside/output`.
|
||||||
|
|
||||||
|
4. You can upload the packages to s3, along with basic html files
|
||||||
|
which enable them to be used, with `bash after.sh`.
|
||||||
|
|
||||||
|
|
||||||
|
In particular, if you are in a jupyter/colab notebook you can
|
||||||
|
then install using these wheels with the following series of
|
||||||
|
commands.
|
||||||
|
|
||||||
|
```
|
||||||
|
import sys
|
||||||
|
import torch
|
||||||
|
pyt_version_str=torch.__version__.split("+")[0].replace(".", "")
|
||||||
|
version_str="".join([
|
||||||
|
f"py3{sys.version_info.minor}_cu",
|
||||||
|
torch.version.cuda.replace(".",""),
|
||||||
|
f"_pyt{pyt_version_str}"
|
||||||
|
])
|
||||||
|
!pip install --no-index --no-cache-dir pytorch3d -f https://dl.fbaipublicfiles.com/pytorch3d/packaging/wheels/{version_str}/download.html
|
||||||
|
```
|
||||||
10
packaging/linux_wheels/after.sh
Normal file
10
packaging/linux_wheels/after.sh
Normal file
@@ -0,0 +1,10 @@
|
|||||||
|
#!/usr/bin/bash
|
||||||
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
|
set -ex
|
||||||
|
sudo chown -R "$USER" output
|
||||||
|
python publish.py
|
||||||
11
packaging/linux_wheels/go.sh
Normal file
11
packaging/linux_wheels/go.sh
Normal file
@@ -0,0 +1,11 @@
|
|||||||
|
#!/usr/bin/bash
|
||||||
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
|
sudo docker run --rm -v "$PWD/../../:/inside" pytorch/conda-cuda bash inside/packaging/linux_wheels/inside.sh
|
||||||
|
sudo docker run --rm -v "$PWD/../../:/inside" -e SELECTED_CUDA=cu113 pytorch/conda-builder:cuda113 bash inside/packaging/linux_wheels/inside.sh
|
||||||
|
sudo docker run --rm -v "$PWD/../../:/inside" -e SELECTED_CUDA=cu115 pytorch/conda-builder:cuda115 bash inside/packaging/linux_wheels/inside.sh
|
||||||
|
sudo docker run --rm -v "$PWD/../../:/inside" -e SELECTED_CUDA=cu116 pytorch/conda-builder:cuda116 bash inside/packaging/linux_wheels/inside.sh
|
||||||
150
packaging/linux_wheels/inside.sh
Normal file
150
packaging/linux_wheels/inside.sh
Normal file
@@ -0,0 +1,150 @@
|
|||||||
|
#!/bin/bash
|
||||||
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
|
set -ex
|
||||||
|
|
||||||
|
conda init bash
|
||||||
|
# shellcheck source=/dev/null
|
||||||
|
source ~/.bashrc
|
||||||
|
|
||||||
|
cd /inside
|
||||||
|
VERSION=$(python -c "exec(open('pytorch3d/__init__.py').read()); print(__version__)")
|
||||||
|
|
||||||
|
export BUILD_VERSION=$VERSION
|
||||||
|
export FORCE_CUDA=1
|
||||||
|
|
||||||
|
wget --no-verbose https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz
|
||||||
|
tar xzf 1.10.0.tar.gz
|
||||||
|
CUB_HOME=$(realpath ./cub-1.10.0)
|
||||||
|
export CUB_HOME
|
||||||
|
echo "CUB_HOME is now $CUB_HOME"
|
||||||
|
|
||||||
|
# As a rule, we want to build for any combination of dependencies which is supported by
|
||||||
|
# PyTorch3D and not older than the current Google Colab set up.
|
||||||
|
|
||||||
|
PYTHON_VERSIONS="3.7 3.8 3.9 3.10"
|
||||||
|
# the keys are pytorch versions
|
||||||
|
declare -A CONDA_CUDA_VERSIONS=(
|
||||||
|
["1.10.1"]="cu111 cu113"
|
||||||
|
["1.10.2"]="cu111 cu113"
|
||||||
|
["1.10.0"]="cu111 cu113"
|
||||||
|
["1.11.0"]="cu111 cu113 cu115"
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
for python_version in $PYTHON_VERSIONS
|
||||||
|
do
|
||||||
|
for pytorch_version in "${!CONDA_CUDA_VERSIONS[@]}"
|
||||||
|
do
|
||||||
|
if [[ "3.7 3.8" != *$python_version* ]] && [[ "1.7.0" == *$pytorch_version* ]]
|
||||||
|
then
|
||||||
|
#python 3.9 and later not supported by pytorch 1.7.0 and before
|
||||||
|
continue
|
||||||
|
fi
|
||||||
|
if [[ "3.7 3.8 3.9" != *$python_version* ]] && [[ "1.7.0 1.7.1 1.8.0 1.8.1 1.9.0 1.9.1 1.10.0 1.10.1 1.10.2" == *$pytorch_version* ]]
|
||||||
|
then
|
||||||
|
#python 3.10 and later not supported by pytorch 1.10.2 and before
|
||||||
|
continue
|
||||||
|
fi
|
||||||
|
|
||||||
|
extra_channel="-c conda-forge"
|
||||||
|
if [[ "1.11.0" == "$pytorch_version" ]]
|
||||||
|
then
|
||||||
|
extra_channel=""
|
||||||
|
fi
|
||||||
|
|
||||||
|
for cu_version in ${CONDA_CUDA_VERSIONS[$pytorch_version]}
|
||||||
|
do
|
||||||
|
if [[ "cu113 cu115 cu116" == *$cu_version* ]]
|
||||||
|
# ^^^ CUDA versions listed here have to be built
|
||||||
|
# in their own containers.
|
||||||
|
then
|
||||||
|
if [[ $SELECTED_CUDA != "$cu_version" ]]
|
||||||
|
then
|
||||||
|
continue
|
||||||
|
fi
|
||||||
|
elif [[ $SELECTED_CUDA != "" ]]
|
||||||
|
then
|
||||||
|
continue
|
||||||
|
fi
|
||||||
|
|
||||||
|
case "$cu_version" in
|
||||||
|
cu116)
|
||||||
|
export CUDA_HOME=/usr/local/cuda-11.6/
|
||||||
|
export CUDA_TAG=11.6
|
||||||
|
export NVCC_FLAGS="-gencode=arch=compute_35,code=sm_35 -gencode=arch=compute_50,code=sm_50 -gencode=arch=compute_60,code=sm_60 -gencode=arch=compute_70,code=sm_70 -gencode=arch=compute_75,code=sm_75 -gencode=arch=compute_80,code=sm_80 -gencode=arch=compute_86,code=sm_86 -gencode=arch=compute_50,code=compute_50"
|
||||||
|
;;
|
||||||
|
cu115)
|
||||||
|
export CUDA_HOME=/usr/local/cuda-11.5/
|
||||||
|
export CUDA_TAG=11.5
|
||||||
|
export NVCC_FLAGS="-gencode=arch=compute_35,code=sm_35 -gencode=arch=compute_50,code=sm_50 -gencode=arch=compute_60,code=sm_60 -gencode=arch=compute_70,code=sm_70 -gencode=arch=compute_75,code=sm_75 -gencode=arch=compute_80,code=sm_80 -gencode=arch=compute_86,code=sm_86 -gencode=arch=compute_50,code=compute_50"
|
||||||
|
;;
|
||||||
|
cu113)
|
||||||
|
export CUDA_HOME=/usr/local/cuda-11.3/
|
||||||
|
export CUDA_TAG=11.3
|
||||||
|
export NVCC_FLAGS="-gencode=arch=compute_35,code=sm_35 -gencode=arch=compute_50,code=sm_50 -gencode=arch=compute_60,code=sm_60 -gencode=arch=compute_70,code=sm_70 -gencode=arch=compute_75,code=sm_75 -gencode=arch=compute_80,code=sm_80 -gencode=arch=compute_86,code=sm_86 -gencode=arch=compute_50,code=compute_50"
|
||||||
|
;;
|
||||||
|
cu112)
|
||||||
|
export CUDA_HOME=/usr/local/cuda-11.2/
|
||||||
|
export CUDA_TAG=11.2
|
||||||
|
export NVCC_FLAGS="-gencode=arch=compute_35,code=sm_35 -gencode=arch=compute_50,code=sm_50 -gencode=arch=compute_60,code=sm_60 -gencode=arch=compute_70,code=sm_70 -gencode=arch=compute_75,code=sm_75 -gencode=arch=compute_80,code=sm_80 -gencode=arch=compute_86,code=sm_86 -gencode=arch=compute_50,code=compute_50"
|
||||||
|
;;
|
||||||
|
cu111)
|
||||||
|
export CUDA_HOME=/usr/local/cuda-11.1/
|
||||||
|
export CUDA_TAG=11.1
|
||||||
|
export NVCC_FLAGS="-gencode=arch=compute_35,code=sm_35 -gencode=arch=compute_50,code=sm_50 -gencode=arch=compute_60,code=sm_60 -gencode=arch=compute_70,code=sm_70 -gencode=arch=compute_75,code=sm_75 -gencode=arch=compute_80,code=sm_80 -gencode=arch=compute_86,code=sm_86 -gencode=arch=compute_50,code=compute_50"
|
||||||
|
;;
|
||||||
|
cu110)
|
||||||
|
export CUDA_HOME=/usr/local/cuda-11.0/
|
||||||
|
export CUDA_TAG=11.0
|
||||||
|
export NVCC_FLAGS="-gencode=arch=compute_35,code=sm_35 -gencode=arch=compute_50,code=sm_50 -gencode=arch=compute_60,code=sm_60 -gencode=arch=compute_70,code=sm_70 -gencode=arch=compute_75,code=sm_75 -gencode=arch=compute_80,code=sm_80 -gencode=arch=compute_50,code=compute_50"
|
||||||
|
;;
|
||||||
|
cu102)
|
||||||
|
export CUDA_HOME=/usr/local/cuda-10.2/
|
||||||
|
export CUDA_TAG=10.2
|
||||||
|
export NVCC_FLAGS="-gencode=arch=compute_35,code=sm_35 -gencode=arch=compute_50,code=sm_50 -gencode=arch=compute_60,code=sm_60 -gencode=arch=compute_70,code=sm_70 -gencode=arch=compute_75,code=sm_75 -gencode=arch=compute_50,code=compute_50"
|
||||||
|
;;
|
||||||
|
cu101)
|
||||||
|
export CUDA_HOME=/usr/local/cuda-10.1/
|
||||||
|
export CUDA_TAG=10.1
|
||||||
|
export NVCC_FLAGS="-gencode=arch=compute_35,code=sm_35 -gencode=arch=compute_50,code=sm_50 -gencode=arch=compute_60,code=sm_60 -gencode=arch=compute_70,code=sm_70 -gencode=arch=compute_75,code=sm_75 -gencode=arch=compute_50,code=compute_50"
|
||||||
|
;;
|
||||||
|
*)
|
||||||
|
echo "Unrecognized cu_version=$cu_version"
|
||||||
|
exit 1
|
||||||
|
;;
|
||||||
|
esac
|
||||||
|
tag=py"${python_version//./}"_"${cu_version}"_pyt"${pytorch_version//./}"
|
||||||
|
|
||||||
|
outdir="/inside/packaging/linux_wheels/output/$tag"
|
||||||
|
if [[ -d "$outdir" ]]
|
||||||
|
then
|
||||||
|
continue
|
||||||
|
fi
|
||||||
|
|
||||||
|
conda create -y -n "$tag" "python=$python_version"
|
||||||
|
conda activate "$tag"
|
||||||
|
# shellcheck disable=SC2086
|
||||||
|
conda install -y -c pytorch $extra_channel "pytorch=$pytorch_version" "cudatoolkit=$CUDA_TAG" torchvision
|
||||||
|
pip install fvcore iopath
|
||||||
|
echo "python version" "$python_version" "pytorch version" "$pytorch_version" "cuda version" "$cu_version" "tag" "$tag"
|
||||||
|
|
||||||
|
rm -rf dist
|
||||||
|
|
||||||
|
python setup.py clean
|
||||||
|
python setup.py bdist_wheel
|
||||||
|
|
||||||
|
rm -rf "$outdir"
|
||||||
|
mkdir -p "$outdir"
|
||||||
|
cp dist/*whl "$outdir"
|
||||||
|
|
||||||
|
conda deactivate
|
||||||
|
done
|
||||||
|
done
|
||||||
|
done
|
||||||
|
echo "DONE"
|
||||||
87
packaging/linux_wheels/publish.py
Normal file
87
packaging/linux_wheels/publish.py
Normal file
@@ -0,0 +1,87 @@
|
|||||||
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
|
import subprocess
|
||||||
|
from pathlib import Path
|
||||||
|
from typing import List
|
||||||
|
|
||||||
|
|
||||||
|
dest = "s3://dl.fbaipublicfiles.com/pytorch3d/packaging/wheels/"
|
||||||
|
|
||||||
|
output = Path("output")
|
||||||
|
|
||||||
|
|
||||||
|
def aws_s3_cmd(args) -> List[str]:
|
||||||
|
"""
|
||||||
|
This function returns the full args for subprocess to do a command
|
||||||
|
with aws.
|
||||||
|
"""
|
||||||
|
cmd_args = ["aws", "s3", "--profile", "saml"] + args
|
||||||
|
return cmd_args
|
||||||
|
|
||||||
|
|
||||||
|
def fs3_exists(path) -> bool:
|
||||||
|
"""
|
||||||
|
Returns True if the path exists inside dest on S3.
|
||||||
|
In fact, will also return True if there is a file which has the given
|
||||||
|
path as a prefix, but we are careful about this.
|
||||||
|
"""
|
||||||
|
out = subprocess.check_output(aws_s3_cmd(["ls", path]))
|
||||||
|
return len(out) != 0
|
||||||
|
|
||||||
|
|
||||||
|
def get_html_wrappers() -> None:
|
||||||
|
for directory in sorted(output.iterdir()):
|
||||||
|
output_wrapper = directory / "download.html"
|
||||||
|
assert not output_wrapper.exists()
|
||||||
|
dest_wrapper = dest + directory.name + "/download.html"
|
||||||
|
if fs3_exists(dest_wrapper):
|
||||||
|
subprocess.check_call(aws_s3_cmd(["cp", dest_wrapper, str(output_wrapper)]))
|
||||||
|
|
||||||
|
|
||||||
|
def write_html_wrappers() -> None:
|
||||||
|
html = """
|
||||||
|
<a href="$">$</a><br>
|
||||||
|
"""
|
||||||
|
|
||||||
|
for directory in sorted(output.iterdir()):
|
||||||
|
files = list(directory.glob("*.whl"))
|
||||||
|
assert len(files) == 1, files
|
||||||
|
[wheel] = files
|
||||||
|
|
||||||
|
this_html = html.replace("$", wheel.name)
|
||||||
|
output_wrapper = directory / "download.html"
|
||||||
|
if output_wrapper.exists():
|
||||||
|
contents = output_wrapper.read_text()
|
||||||
|
if this_html not in contents:
|
||||||
|
with open(output_wrapper, "a") as f:
|
||||||
|
f.write(this_html)
|
||||||
|
else:
|
||||||
|
output_wrapper.write_text(this_html)
|
||||||
|
|
||||||
|
|
||||||
|
def to_aws() -> None:
|
||||||
|
for directory in output.iterdir():
|
||||||
|
for file in directory.iterdir():
|
||||||
|
print(file)
|
||||||
|
subprocess.check_call(
|
||||||
|
aws_s3_cmd(["cp", str(file), dest + str(file.relative_to(output))])
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
# Uncomment this for subsequent releases.
|
||||||
|
# get_html_wrappers()
|
||||||
|
write_html_wrappers()
|
||||||
|
to_aws()
|
||||||
|
|
||||||
|
|
||||||
|
# see all files with
|
||||||
|
# aws s3 --profile saml ls --recursive s3://dl.fbaipublicfiles.com/pytorch3d/
|
||||||
|
|
||||||
|
# empty current with
|
||||||
|
# aws s3 --profile saml rm --recursive
|
||||||
|
# s3://dl.fbaipublicfiles.com/pytorch3d/packaging/wheels/
|
||||||
@@ -1,9 +1,13 @@
|
|||||||
# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
# shellcheck shell=bash
|
# shellcheck shell=bash
|
||||||
# A set of useful bash functions for common functionality we need to do in
|
# A set of useful bash functions for common functionality we need to do in
|
||||||
# many build scripts
|
# many build scripts
|
||||||
|
|
||||||
|
|
||||||
# Setup CUDA environment variables, based on CU_VERSION
|
# Setup CUDA environment variables, based on CU_VERSION
|
||||||
#
|
#
|
||||||
# Inputs:
|
# Inputs:
|
||||||
@@ -51,6 +55,61 @@ setup_cuda() {
|
|||||||
|
|
||||||
# Now work out the CUDA settings
|
# Now work out the CUDA settings
|
||||||
case "$CU_VERSION" in
|
case "$CU_VERSION" in
|
||||||
|
cu116)
|
||||||
|
if [[ "$OSTYPE" == "msys" ]]; then
|
||||||
|
export CUDA_HOME="C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v11.6"
|
||||||
|
else
|
||||||
|
export CUDA_HOME=/usr/local/cuda-11.6/
|
||||||
|
fi
|
||||||
|
export FORCE_CUDA=1
|
||||||
|
# Hard-coding gencode flags is temporary situation until
|
||||||
|
# https://github.com/pytorch/pytorch/pull/23408 lands
|
||||||
|
export NVCC_FLAGS="-gencode=arch=compute_35,code=sm_35 -gencode=arch=compute_50,code=sm_50 -gencode=arch=compute_60,code=sm_60 -gencode=arch=compute_70,code=sm_70 -gencode=arch=compute_75,code=sm_75 -gencode=arch=compute_80,code=sm_80 -gencode=arch=compute_86,code=sm_86 -gencode=arch=compute_50,code=compute_50"
|
||||||
|
;;
|
||||||
|
cu115)
|
||||||
|
if [[ "$OSTYPE" == "msys" ]]; then
|
||||||
|
export CUDA_HOME="C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v11.5"
|
||||||
|
else
|
||||||
|
export CUDA_HOME=/usr/local/cuda-11.5/
|
||||||
|
fi
|
||||||
|
export FORCE_CUDA=1
|
||||||
|
# Hard-coding gencode flags is temporary situation until
|
||||||
|
# https://github.com/pytorch/pytorch/pull/23408 lands
|
||||||
|
export NVCC_FLAGS="-gencode=arch=compute_35,code=sm_35 -gencode=arch=compute_50,code=sm_50 -gencode=arch=compute_60,code=sm_60 -gencode=arch=compute_70,code=sm_70 -gencode=arch=compute_75,code=sm_75 -gencode=arch=compute_80,code=sm_80 -gencode=arch=compute_86,code=sm_86 -gencode=arch=compute_50,code=compute_50"
|
||||||
|
;;
|
||||||
|
cu113)
|
||||||
|
if [[ "$OSTYPE" == "msys" ]]; then
|
||||||
|
export CUDA_HOME="C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v11.3"
|
||||||
|
else
|
||||||
|
export CUDA_HOME=/usr/local/cuda-11.3/
|
||||||
|
fi
|
||||||
|
export FORCE_CUDA=1
|
||||||
|
# Hard-coding gencode flags is temporary situation until
|
||||||
|
# https://github.com/pytorch/pytorch/pull/23408 lands
|
||||||
|
export NVCC_FLAGS="-gencode=arch=compute_35,code=sm_35 -gencode=arch=compute_50,code=sm_50 -gencode=arch=compute_60,code=sm_60 -gencode=arch=compute_70,code=sm_70 -gencode=arch=compute_75,code=sm_75 -gencode=arch=compute_80,code=sm_80 -gencode=arch=compute_86,code=sm_86 -gencode=arch=compute_50,code=compute_50"
|
||||||
|
;;
|
||||||
|
cu112)
|
||||||
|
if [[ "$OSTYPE" == "msys" ]]; then
|
||||||
|
export CUDA_HOME="C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v11.2"
|
||||||
|
else
|
||||||
|
export CUDA_HOME=/usr/local/cuda-11.2/
|
||||||
|
fi
|
||||||
|
export FORCE_CUDA=1
|
||||||
|
# Hard-coding gencode flags is temporary situation until
|
||||||
|
# https://github.com/pytorch/pytorch/pull/23408 lands
|
||||||
|
export NVCC_FLAGS="-gencode=arch=compute_35,code=sm_35 -gencode=arch=compute_50,code=sm_50 -gencode=arch=compute_60,code=sm_60 -gencode=arch=compute_70,code=sm_70 -gencode=arch=compute_75,code=sm_75 -gencode=arch=compute_80,code=sm_80 -gencode=arch=compute_86,code=sm_86 -gencode=arch=compute_50,code=compute_50"
|
||||||
|
;;
|
||||||
|
cu111)
|
||||||
|
if [[ "$OSTYPE" == "msys" ]]; then
|
||||||
|
export CUDA_HOME="C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v11.1"
|
||||||
|
else
|
||||||
|
export CUDA_HOME=/usr/local/cuda-11.1/
|
||||||
|
fi
|
||||||
|
export FORCE_CUDA=1
|
||||||
|
# Hard-coding gencode flags is temporary situation until
|
||||||
|
# https://github.com/pytorch/pytorch/pull/23408 lands
|
||||||
|
export NVCC_FLAGS="-gencode=arch=compute_35,code=sm_35 -gencode=arch=compute_50,code=sm_50 -gencode=arch=compute_60,code=sm_60 -gencode=arch=compute_70,code=sm_70 -gencode=arch=compute_75,code=sm_75 -gencode=arch=compute_80,code=sm_80 -gencode=arch=compute_86,code=sm_86 -gencode=arch=compute_50,code=compute_50"
|
||||||
|
;;
|
||||||
cu110)
|
cu110)
|
||||||
if [[ "$OSTYPE" == "msys" ]]; then
|
if [[ "$OSTYPE" == "msys" ]]; then
|
||||||
export CUDA_HOME="C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v11.0"
|
export CUDA_HOME="C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v11.0"
|
||||||
@@ -236,7 +295,7 @@ setup_conda_pytorch_constraint() {
|
|||||||
exit 1
|
exit 1
|
||||||
fi
|
fi
|
||||||
else
|
else
|
||||||
export CONDA_CHANNEL_FLAGS="-c pytorch -c pytorch-nightly"
|
export CONDA_CHANNEL_FLAGS="-c pytorch"
|
||||||
fi
|
fi
|
||||||
if [[ "$CU_VERSION" == cpu ]]; then
|
if [[ "$CU_VERSION" == cpu ]]; then
|
||||||
export CONDA_PYTORCH_BUILD_CONSTRAINT="- pytorch==$PYTORCH_VERSION${PYTORCH_VERSION_SUFFIX}"
|
export CONDA_PYTORCH_BUILD_CONSTRAINT="- pytorch==$PYTORCH_VERSION${PYTORCH_VERSION_SUFFIX}"
|
||||||
@@ -256,6 +315,21 @@ setup_conda_cudatoolkit_constraint() {
|
|||||||
export CONDA_CUDATOOLKIT_CONSTRAINT=""
|
export CONDA_CUDATOOLKIT_CONSTRAINT=""
|
||||||
else
|
else
|
||||||
case "$CU_VERSION" in
|
case "$CU_VERSION" in
|
||||||
|
cu116)
|
||||||
|
export CONDA_CUDATOOLKIT_CONSTRAINT="- cudatoolkit >=11.6,<11.7 # [not osx]"
|
||||||
|
;;
|
||||||
|
cu115)
|
||||||
|
export CONDA_CUDATOOLKIT_CONSTRAINT="- cudatoolkit >=11.5,<11.6 # [not osx]"
|
||||||
|
;;
|
||||||
|
cu113)
|
||||||
|
export CONDA_CUDATOOLKIT_CONSTRAINT="- cudatoolkit >=11.3,<11.4 # [not osx]"
|
||||||
|
;;
|
||||||
|
cu112)
|
||||||
|
export CONDA_CUDATOOLKIT_CONSTRAINT="- cudatoolkit >=11.2,<11.3 # [not osx]"
|
||||||
|
;;
|
||||||
|
cu111)
|
||||||
|
export CONDA_CUDATOOLKIT_CONSTRAINT="- cudatoolkit >=11.1,<11.2 # [not osx]"
|
||||||
|
;;
|
||||||
cu110)
|
cu110)
|
||||||
export CONDA_CUDATOOLKIT_CONSTRAINT="- cudatoolkit >=11.0,<11.1 # [not osx]"
|
export CONDA_CUDATOOLKIT_CONSTRAINT="- cudatoolkit >=11.0,<11.1 # [not osx]"
|
||||||
# Even though cudatoolkit 11.0 provides CUB we need our own, to control the
|
# Even though cudatoolkit 11.0 provides CUB we need our own, to control the
|
||||||
|
|||||||
@@ -1,24 +0,0 @@
|
|||||||
blas_impl:
|
|
||||||
- mkl # [x86_64]
|
|
||||||
c_compiler:
|
|
||||||
- vs2017 # [win]
|
|
||||||
cxx_compiler:
|
|
||||||
- vs2017 # [win]
|
|
||||||
python:
|
|
||||||
- 3.5
|
|
||||||
- 3.6
|
|
||||||
# This differs from target_platform in that it determines what subdir the compiler
|
|
||||||
# will target, not what subdir the compiler package will be itself.
|
|
||||||
# For example, we need a win-64 vs2008_win-32 package, so that we compile win-32
|
|
||||||
# code on win-64 miniconda.
|
|
||||||
cross_compiler_target_platform:
|
|
||||||
- win-64 # [win]
|
|
||||||
target_platform:
|
|
||||||
- win-64 # [win]
|
|
||||||
vc:
|
|
||||||
- 14
|
|
||||||
zip_keys:
|
|
||||||
- # [win]
|
|
||||||
- vc # [win]
|
|
||||||
- c_compiler # [win]
|
|
||||||
- cxx_compiler # [win]
|
|
||||||
@@ -22,6 +22,7 @@ requirements:
|
|||||||
- numpy >=1.11
|
- numpy >=1.11
|
||||||
- torchvision >=0.5
|
- torchvision >=0.5
|
||||||
- fvcore
|
- fvcore
|
||||||
|
- iopath
|
||||||
{{ environ.get('CONDA_PYTORCH_CONSTRAINT') }}
|
{{ environ.get('CONDA_PYTORCH_CONSTRAINT') }}
|
||||||
{{ environ.get('CONDA_CUDATOOLKIT_CONSTRAINT') }}
|
{{ environ.get('CONDA_CUDATOOLKIT_CONSTRAINT') }}
|
||||||
|
|
||||||
@@ -44,9 +45,12 @@ test:
|
|||||||
- docs
|
- docs
|
||||||
requires:
|
requires:
|
||||||
- imageio
|
- imageio
|
||||||
|
- hydra-core
|
||||||
|
- accelerate
|
||||||
|
- lpips
|
||||||
commands:
|
commands:
|
||||||
#pytest .
|
#pytest .
|
||||||
python -m unittest discover -v -s tests
|
python -m unittest discover -v -s tests -t .
|
||||||
|
|
||||||
|
|
||||||
about:
|
about:
|
||||||
|
|||||||
@@ -1,4 +1,9 @@
|
|||||||
:: Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
@REM Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
@REM All rights reserved.
|
||||||
|
@REM
|
||||||
|
@REM This source code is licensed under the BSD-style license found in the
|
||||||
|
@REM LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
:: Set env vars that tell distutils to use the compiler that we put on path
|
:: Set env vars that tell distutils to use the compiler that we put on path
|
||||||
SET DISTUTILS_USE_SDK=1
|
SET DISTUTILS_USE_SDK=1
|
||||||
SET MSSdk=1
|
SET MSSdk=1
|
||||||
|
|||||||
@@ -1,4 +1,9 @@
|
|||||||
:: Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
@REM Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
@REM All rights reserved.
|
||||||
|
@REM
|
||||||
|
@REM This source code is licensed under the BSD-style license found in the
|
||||||
|
@REM LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
set YEAR=2017
|
set YEAR=2017
|
||||||
set VER=15
|
set VER=15
|
||||||
|
|
||||||
|
|||||||
@@ -1,4 +1,9 @@
|
|||||||
:: Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
@REM Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
@REM All rights reserved.
|
||||||
|
@REM
|
||||||
|
@REM This source code is licensed under the BSD-style license found in the
|
||||||
|
@REM LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
set VC_PATH=x86
|
set VC_PATH=x86
|
||||||
if "%ARCH%"=="64" (
|
if "%ARCH%"=="64" (
|
||||||
set VC_PATH=x64
|
set VC_PATH=x64
|
||||||
|
|||||||
@@ -1,4 +1,9 @@
|
|||||||
:: Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
@REM Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
@REM All rights reserved.
|
||||||
|
@REM
|
||||||
|
@REM This source code is licensed under the BSD-style license found in the
|
||||||
|
@REM LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
:: Set env vars that tell distutils to use the compiler that we put on path
|
:: Set env vars that tell distutils to use the compiler that we put on path
|
||||||
SET DISTUTILS_USE_SDK=1
|
SET DISTUTILS_USE_SDK=1
|
||||||
SET MSSdk=1
|
SET MSSdk=1
|
||||||
|
|||||||
@@ -1,4 +1,9 @@
|
|||||||
:: Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
@REM Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
@REM All rights reserved.
|
||||||
|
@REM
|
||||||
|
@REM This source code is licensed under the BSD-style license found in the
|
||||||
|
@REM LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
set YEAR=2019
|
set YEAR=2019
|
||||||
set VER=16
|
set VER=16
|
||||||
|
|
||||||
|
|||||||
@@ -1,4 +1,9 @@
|
|||||||
:: Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
|
@REM Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
@REM All rights reserved.
|
||||||
|
@REM
|
||||||
|
@REM This source code is licensed under the BSD-style license found in the
|
||||||
|
@REM LICENSE file in the root directory of this source tree.
|
||||||
|
|
||||||
set VC_PATH=x86
|
set VC_PATH=x86
|
||||||
if "%ARCH%"=="64" (
|
if "%ARCH%"=="64" (
|
||||||
set VC_PATH=x64
|
set VC_PATH=x64
|
||||||
|
|||||||
5
projects/__init__.py
Normal file
5
projects/__init__.py
Normal file
@@ -0,0 +1,5 @@
|
|||||||
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
280
projects/implicitron_trainer/README.md
Normal file
280
projects/implicitron_trainer/README.md
Normal file
@@ -0,0 +1,280 @@
|
|||||||
|
# Introduction
|
||||||
|
|
||||||
|
Implicitron is a PyTorch3D-based framework for new-view synthesis via modeling the neural-network based representations.
|
||||||
|
|
||||||
|
# License
|
||||||
|
|
||||||
|
Implicitron is distributed as part of PyTorch3D under the [BSD license](https://github.com/facebookresearch/pytorch3d/blob/main/LICENSE).
|
||||||
|
It includes code from the [NeRF](https://github.com/bmild/nerf), [SRN](http://github.com/vsitzmann/scene-representation-networks) and [IDR](http://github.com/lioryariv/idr) repos.
|
||||||
|
See [LICENSE-3RD-PARTY](https://github.com/facebookresearch/pytorch3d/blob/main/LICENSE-3RD-PARTY) for their licenses.
|
||||||
|
|
||||||
|
|
||||||
|
# Installation
|
||||||
|
|
||||||
|
There are three ways to set up Implicitron, depending on the flexibility level required.
|
||||||
|
If you only want to train or evaluate models as they are implemented changing only the parameters, you can just install the package.
|
||||||
|
Implicitron also provides a flexible API that supports user-defined plug-ins;
|
||||||
|
if you want to re-implement some of the components without changing the high-level pipeline, you need to create a custom launcher script.
|
||||||
|
The most flexible option, though, is cloning PyTorch3D repo and building it from sources, which allows changing the code in arbitrary ways.
|
||||||
|
Below, we descibe all three options in more details.
|
||||||
|
|
||||||
|
|
||||||
|
## [Option 1] Running an executable from the package
|
||||||
|
|
||||||
|
This option allows you to use the code as is without changing the implementations.
|
||||||
|
Only configuration can be changed (see [Configuration system](#configuration-system)).
|
||||||
|
|
||||||
|
For this setup, install the dependencies and PyTorch3D from conda following [the guide](https://github.com/facebookresearch/pytorch3d/blob/master/INSTALL.md#1-install-with-cuda-support-from-anaconda-cloud-on-linux-only). Then, install implicitron-specific dependencies:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
pip install "hydra-core>=1.1" visdom lpips matplotlib accelerate
|
||||||
|
```
|
||||||
|
|
||||||
|
Runner executable is available as `pytorch3d_implicitron_runner` shell command.
|
||||||
|
See [Running](#running) section below for examples of training and evaluation commands.
|
||||||
|
|
||||||
|
## [Option 2] Supporting custom implementations
|
||||||
|
|
||||||
|
To plug in custom implementations, for example, of renderer or implicit-function protocols, you need to create your own runner script and import the plug-in implementations there.
|
||||||
|
First, install PyTorch3D and Implicitron dependencies as described in the previous section.
|
||||||
|
Then, implement the custom script; copying `pytorch3d/projects/implicitron_trainer/experiment.py` is a good place to start.
|
||||||
|
See [Custom plugins](#custom-plugins) for more information on how to import implementations and enable them in the configs.
|
||||||
|
|
||||||
|
|
||||||
|
## [Option 3] Cloning PyTorch3D repo
|
||||||
|
|
||||||
|
This is the most flexible way to set up Implicitron as it allows changing the code directly.
|
||||||
|
It allows modifying the high-level rendering pipeline or implementing yet-unsupported loss functions.
|
||||||
|
Please follow the instructions to [install PyTorch3D from a local clone](https://github.com/facebookresearch/pytorch3d/blob/main/INSTALL.md#2-install-from-a-local-clone).
|
||||||
|
Then, install Implicitron-specific dependencies:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
pip install "hydra-core>=1.1" visdom lpips matplotlib accelerate
|
||||||
|
```
|
||||||
|
|
||||||
|
You are still encouraged to implement custom plugins as above where possible as it makes reusing the code easier.
|
||||||
|
The executable is located in `pytorch3d/projects/implicitron_trainer`.
|
||||||
|
|
||||||
|
|
||||||
|
# Running
|
||||||
|
|
||||||
|
This section assumes that you use the executable provided by the installed package.
|
||||||
|
If you have a custom `experiment.py` script (as in the Option 2 above), replace the executable with the path to your script.
|
||||||
|
|
||||||
|
## Training
|
||||||
|
|
||||||
|
To run training, pass a yaml config file, followed by a list of overridden arguments.
|
||||||
|
For example, to train NeRF on the first skateboard sequence from CO3D dataset, you can run:
|
||||||
|
```shell
|
||||||
|
dataset_args=data_source_args.dataset_map_provider_JsonIndexDatasetMapProvider_args
|
||||||
|
pytorch3d_implicitron_runner --config-path ./configs/ --config-name repro_singleseq_nerf $dataset_args.dataset_root=<DATASET_ROOT> $dataset_args.category='skateboard' $dataset_args.test_restrict_sequence_id=0 test_when_finished=True exp_dir=<CHECKPOINT_DIR>
|
||||||
|
```
|
||||||
|
|
||||||
|
Here, `--config-path` points to the config path relative to `pytorch3d_implicitron_runner` location;
|
||||||
|
`--config-name` picks the config (in this case, `repro_singleseq_nerf.yaml`);
|
||||||
|
`test_when_finished` will launch evaluation script once training is finished.
|
||||||
|
Replace `<DATASET_ROOT>` with the location where the dataset in Implicitron format is stored
|
||||||
|
and `<CHECKPOINT_DIR>` with a directory where checkpoints will be dumped during training.
|
||||||
|
Other configuration parameters can be overridden in the same way.
|
||||||
|
See [Configuration system](#configuration-system) section for more information on this.
|
||||||
|
|
||||||
|
|
||||||
|
## Evaluation
|
||||||
|
|
||||||
|
To run evaluation on the latest checkpoint after (or during) training, simply add `eval_only=True` to your training command.
|
||||||
|
|
||||||
|
E.g. for executing the evaluation on the NeRF skateboard sequence, you can run:
|
||||||
|
```shell
|
||||||
|
dataset_args=data_source_args.dataset_map_provider_JsonIndexDatasetMapProvider_args
|
||||||
|
pytorch3d_implicitron_runner --config-path ./configs/ --config-name repro_singleseq_nerf $dataset_args.dataset_root=<CO3D_DATASET_ROOT> $dataset_args.category='skateboard' $dataset_args.test_restrict_sequence_id=0 exp_dir=<CHECKPOINT_DIR> eval_only=True
|
||||||
|
```
|
||||||
|
Evaluation prints the metrics to `stdout` and dumps them to a json file in `exp_dir`.
|
||||||
|
|
||||||
|
## Visualisation
|
||||||
|
|
||||||
|
The script produces a video of renders by a trained model assuming a pre-defined camera trajectory.
|
||||||
|
In order for it to work, `ffmpeg` needs to be installed:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
conda install ffmpeg
|
||||||
|
```
|
||||||
|
|
||||||
|
Here is an example of calling the script:
|
||||||
|
```shell
|
||||||
|
projects/implicitron_trainer/visualize_reconstruction.py exp_dir=<CHECKPOINT_DIR> visdom_show_preds=True n_eval_cameras=40 render_size="[64,64]" video_size="[256,256]"
|
||||||
|
```
|
||||||
|
|
||||||
|
The argument `n_eval_cameras` sets the number of renderring viewpoints sampled on a trajectory, which defaults to a circular fly-around;
|
||||||
|
`render_size` sets the size of a render passed to the model, which can be resized to `video_size` before writing.
|
||||||
|
|
||||||
|
Rendered videos of images, masks, and depth maps will be saved to `<CHECKPOINT_DIR>/vis`.
|
||||||
|
|
||||||
|
|
||||||
|
# Configuration system
|
||||||
|
|
||||||
|
We use hydra and OmegaConf to parse the configs.
|
||||||
|
The config schema and default values are defined by the dataclasses implementing the modules.
|
||||||
|
More specifically, if a class derives from `Configurable`, its fields can be set in config yaml files or overridden in CLI.
|
||||||
|
For example, `GenericModel` has a field `render_image_width` with the default value 400.
|
||||||
|
If it is specified in the yaml config file or in CLI command, the new value will be used.
|
||||||
|
|
||||||
|
Configurables can form hierarchies.
|
||||||
|
For example, `GenericModel` has a field `raysampler: RaySampler`, which is also Configurable.
|
||||||
|
In the config, inner parameters can be propagated using `_args` postfix, e.g. to change `raysampler.n_pts_per_ray_training` (the number of sampled points per ray), the node `raysampler_args.n_pts_per_ray_training` should be specified.
|
||||||
|
|
||||||
|
The root of the hierarchy is defined by `ExperimentConfig` dataclass.
|
||||||
|
It has top-level fields like `eval_only` which was used above for running evaluation by adding a CLI override.
|
||||||
|
Additionally, it has non-leaf nodes like `generic_model_args`, which dispatches the config parameters to `GenericModel`. Thus, changing the model parameters may be achieved in two ways: either by editing the config file, e.g.
|
||||||
|
```yaml
|
||||||
|
generic_model_args:
|
||||||
|
render_image_width: 800
|
||||||
|
raysampler_args:
|
||||||
|
n_pts_per_ray_training: 128
|
||||||
|
```
|
||||||
|
|
||||||
|
or, equivalently, by adding the following to `pytorch3d_implicitron_runner` arguments:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
generic_model_args.render_image_width=800 generic_model_args.raysampler_args.n_pts_per_ray_training=128
|
||||||
|
```
|
||||||
|
|
||||||
|
See the documentation in `pytorch3d/implicitron/tools/config.py` for more details.
|
||||||
|
|
||||||
|
## Replaceable implementations
|
||||||
|
|
||||||
|
Sometimes changing the model parameters does not provide enough flexibility, and you want to provide a new implementation for a building block.
|
||||||
|
The configuration system also supports it!
|
||||||
|
Abstract classes like `BaseRenderer` derive from `ReplaceableBase` instead of `Configurable`.
|
||||||
|
This means that other Configurables can refer to them using the base type, while the specific implementation is chosen in the config using `_class_type`-postfixed node.
|
||||||
|
In that case, `_args` node name has to include the implementation type.
|
||||||
|
More specifically, to change renderer settings, the config will look like this:
|
||||||
|
```yaml
|
||||||
|
generic_model_args:
|
||||||
|
renderer_class_type: LSTMRenderer
|
||||||
|
renderer_LSTMRenderer_args:
|
||||||
|
num_raymarch_steps: 10
|
||||||
|
hidden_size: 16
|
||||||
|
```
|
||||||
|
|
||||||
|
See the documentation in `pytorch3d/implicitron/tools/config.py` for more details on the configuration system.
|
||||||
|
|
||||||
|
## Custom plugins
|
||||||
|
|
||||||
|
If you have an idea for another implementation of a replaceable component, it can be plugged in without changing the core code.
|
||||||
|
For that, you need to set up Implicitron through option 2 or 3 above.
|
||||||
|
Let's say you want to implement a renderer that accumulates opacities similar to an X-ray machine.
|
||||||
|
First, create a module `x_ray_renderer.py` with a class deriving from `BaseRenderer`:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from pytorch3d.implicitron.tools.config import registry
|
||||||
|
|
||||||
|
@registry.register
|
||||||
|
class XRayRenderer(BaseRenderer, torch.nn.Module):
|
||||||
|
n_pts_per_ray: int = 64
|
||||||
|
|
||||||
|
# if there are other base classes, make sure to call `super().__init__()` explicitly
|
||||||
|
def __post_init__(self):
|
||||||
|
super().__init__()
|
||||||
|
# custom initialization
|
||||||
|
|
||||||
|
def forward(
|
||||||
|
self,
|
||||||
|
ray_bundle,
|
||||||
|
implicit_functions=[],
|
||||||
|
evaluation_mode: EvaluationMode = EvaluationMode.EVALUATION,
|
||||||
|
**kwargs,
|
||||||
|
) -> RendererOutput:
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
Please note `@registry.register` decorator that registers the plug-in as an implementation of `Renderer`.
|
||||||
|
IMPORTANT: In order for it to run, the class (or its enclosing module) has to be imported in your launch script. Additionally, this has to be done before parsing the root configuration class `ExperimentConfig`.
|
||||||
|
Simply add `import .x_ray_renderer` in the beginning of `experiment.py`.
|
||||||
|
|
||||||
|
After that, you should be able to change the config with:
|
||||||
|
```yaml
|
||||||
|
generic_model_args:
|
||||||
|
renderer_class_type: XRayRenderer
|
||||||
|
renderer_XRayRenderer_args:
|
||||||
|
n_pts_per_ray: 128
|
||||||
|
```
|
||||||
|
|
||||||
|
to replace the implementation and potentially override the parameters.
|
||||||
|
|
||||||
|
# Code and config structure
|
||||||
|
|
||||||
|
As per above, the config structure is parsed automatically from the module hierarchy.
|
||||||
|
In particular, model parameters are contained in `generic_model_args` node, and dataset parameters in `data_source_args` node.
|
||||||
|
|
||||||
|
Here is the class structure (single-line edges show aggregation, while double lines show available implementations):
|
||||||
|
```
|
||||||
|
generic_model_args: GenericModel
|
||||||
|
└-- sequence_autodecoder_args: Autodecoder
|
||||||
|
└-- raysampler_args: RaySampler
|
||||||
|
└-- renderer_*_args: BaseRenderer
|
||||||
|
╘== MultiPassEmissionAbsorptionRenderer
|
||||||
|
╘== LSTMRenderer
|
||||||
|
╘== SignedDistanceFunctionRenderer
|
||||||
|
└-- ray_tracer_args: RayTracing
|
||||||
|
└-- ray_normal_coloring_network_args: RayNormalColoringNetwork
|
||||||
|
└-- implicit_function_*_args: ImplicitFunctionBase
|
||||||
|
╘== NeuralRadianceFieldImplicitFunction
|
||||||
|
╘== SRNImplicitFunction
|
||||||
|
└-- raymarch_function_args: SRNRaymarchFunction
|
||||||
|
└-- pixel_generator_args: SRNPixelGenerator
|
||||||
|
╘== SRNHyperNetImplicitFunction
|
||||||
|
└-- hypernet_args: SRNRaymarchHyperNet
|
||||||
|
└-- pixel_generator_args: SRNPixelGenerator
|
||||||
|
╘== IdrFeatureField
|
||||||
|
└-- image_feature_extractor_*_args: FeatureExtractorBase
|
||||||
|
╘== ResNetFeatureExtractor
|
||||||
|
└-- view_sampler_args: ViewSampler
|
||||||
|
└-- feature_aggregator_*_args: FeatureAggregatorBase
|
||||||
|
╘== IdentityFeatureAggregator
|
||||||
|
╘== AngleWeightedIdentityFeatureAggregator
|
||||||
|
╘== AngleWeightedReductionFeatureAggregator
|
||||||
|
╘== ReductionFeatureAggregator
|
||||||
|
solver_args: init_optimizer
|
||||||
|
data_source_args: ImplicitronDataSource
|
||||||
|
└-- dataset_map_provider_*_args
|
||||||
|
└-- data_loader_map_provider_*_args
|
||||||
|
```
|
||||||
|
|
||||||
|
Please look at the annotations of the respective classes or functions for the lists of hyperparameters.
|
||||||
|
|
||||||
|
# Reproducing CO3D experiments
|
||||||
|
|
||||||
|
Common Objects in 3D (CO3D) is a large-scale dataset of videos of rigid objects grouped into 50 common categories.
|
||||||
|
Implicitron provides implementations and config files to reproduce the results from [the paper](https://arxiv.org/abs/2109.00512).
|
||||||
|
Please follow [the link](https://github.com/facebookresearch/co3d#automatic-batch-download) for the instructions to download the dataset.
|
||||||
|
In training and evaluation scripts, use the download location as `<DATASET_ROOT>`.
|
||||||
|
It is also possible to define environment variable `CO3D_DATASET_ROOT` instead of specifying it.
|
||||||
|
To reproduce the experiments from the paper, use the following configs. For single-sequence experiments:
|
||||||
|
|
||||||
|
| Method | config file |
|
||||||
|
|-----------------|-------------------------------------|
|
||||||
|
| NeRF | repro_singleseq_nerf.yaml |
|
||||||
|
| NeRF + WCE | repro_singleseq_nerf_wce.yaml |
|
||||||
|
| NerFormer | repro_singleseq_nerformer.yaml |
|
||||||
|
| IDR | repro_singleseq_idr.yaml |
|
||||||
|
| SRN | repro_singleseq_srn_noharm.yaml |
|
||||||
|
| SRN + γ | repro_singleseq_srn.yaml |
|
||||||
|
| SRN + WCE | repro_singleseq_srn_wce_noharm.yaml |
|
||||||
|
| SRN + WCE + γ | repro_singleseq_srn_wce_noharm.yaml |
|
||||||
|
|
||||||
|
For multi-sequence experiments (without generalisation to new sequences):
|
||||||
|
|
||||||
|
| Method | config file |
|
||||||
|
|-----------------|--------------------------------------------|
|
||||||
|
| NeRF + AD | repro_multiseq_nerf_ad.yaml |
|
||||||
|
| SRN + AD | repro_multiseq_srn_ad_hypernet_noharm.yaml |
|
||||||
|
| SRN + γ + AD | repro_multiseq_srn_ad_hypernet.yaml |
|
||||||
|
|
||||||
|
For multi-sequence experiments (with generalisation to new sequences):
|
||||||
|
|
||||||
|
| Method | config file |
|
||||||
|
|-----------------|--------------------------------------|
|
||||||
|
| NeRF + WCE | repro_multiseq_nerf_wce.yaml |
|
||||||
|
| NerFormer | repro_multiseq_nerformer.yaml |
|
||||||
|
| SRN + WCE | repro_multiseq_srn_wce_noharm.yaml |
|
||||||
|
| SRN + WCE + γ | repro_multiseq_srn_wce.yaml |
|
||||||
5
projects/implicitron_trainer/__init__.py
Normal file
5
projects/implicitron_trainer/__init__.py
Normal file
@@ -0,0 +1,5 @@
|
|||||||
|
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
||||||
|
# All rights reserved.
|
||||||
|
#
|
||||||
|
# This source code is licensed under the BSD-style license found in the
|
||||||
|
# LICENSE file in the root directory of this source tree.
|
||||||
75
projects/implicitron_trainer/configs/repro_base.yaml
Normal file
75
projects/implicitron_trainer/configs/repro_base.yaml
Normal file
@@ -0,0 +1,75 @@
|
|||||||
|
defaults:
|
||||||
|
- default_config
|
||||||
|
- _self_
|
||||||
|
exp_dir: ./data/exps/base/
|
||||||
|
architecture: generic
|
||||||
|
visualize_interval: 0
|
||||||
|
visdom_port: 8097
|
||||||
|
data_source_args:
|
||||||
|
data_loader_map_provider_class_type: SequenceDataLoaderMapProvider
|
||||||
|
dataset_map_provider_class_type: JsonIndexDatasetMapProvider
|
||||||
|
data_loader_map_provider_SequenceDataLoaderMapProvider_args:
|
||||||
|
dataset_length_train: 1000
|
||||||
|
dataset_length_val: 1
|
||||||
|
num_workers: 8
|
||||||
|
dataset_map_provider_JsonIndexDatasetMapProvider_args:
|
||||||
|
dataset_root: ${oc.env:CO3D_DATASET_ROOT}
|
||||||
|
n_frames_per_sequence: -1
|
||||||
|
test_on_train: true
|
||||||
|
test_restrict_sequence_id: 0
|
||||||
|
dataset_JsonIndexDataset_args:
|
||||||
|
load_point_clouds: false
|
||||||
|
mask_depths: false
|
||||||
|
mask_images: false
|
||||||
|
generic_model_args:
|
||||||
|
loss_weights:
|
||||||
|
loss_mask_bce: 1.0
|
||||||
|
loss_prev_stage_mask_bce: 1.0
|
||||||
|
loss_autodecoder_norm: 0.01
|
||||||
|
loss_rgb_mse: 1.0
|
||||||
|
loss_prev_stage_rgb_mse: 1.0
|
||||||
|
output_rasterized_mc: false
|
||||||
|
chunk_size_grid: 102400
|
||||||
|
render_image_height: 400
|
||||||
|
render_image_width: 400
|
||||||
|
num_passes: 2
|
||||||
|
implicit_function_NeuralRadianceFieldImplicitFunction_args:
|
||||||
|
n_harmonic_functions_xyz: 10
|
||||||
|
n_harmonic_functions_dir: 4
|
||||||
|
n_hidden_neurons_xyz: 256
|
||||||
|
n_hidden_neurons_dir: 128
|
||||||
|
n_layers_xyz: 8
|
||||||
|
append_xyz:
|
||||||
|
- 5
|
||||||
|
latent_dim: 0
|
||||||
|
raysampler_AdaptiveRaySampler_args:
|
||||||
|
n_rays_per_image_sampled_from_mask: 1024
|
||||||
|
scene_extent: 8.0
|
||||||
|
n_pts_per_ray_training: 64
|
||||||
|
n_pts_per_ray_evaluation: 64
|
||||||
|
stratified_point_sampling_training: true
|
||||||
|
stratified_point_sampling_evaluation: false
|
||||||
|
renderer_MultiPassEmissionAbsorptionRenderer_args:
|
||||||
|
n_pts_per_ray_fine_training: 64
|
||||||
|
n_pts_per_ray_fine_evaluation: 64
|
||||||
|
append_coarse_samples_to_fine: true
|
||||||
|
density_noise_std_train: 1.0
|
||||||
|
view_pooler_args:
|
||||||
|
view_sampler_args:
|
||||||
|
masked_sampling: false
|
||||||
|
image_feature_extractor_ResNetFeatureExtractor_args:
|
||||||
|
stages:
|
||||||
|
- 1
|
||||||
|
- 2
|
||||||
|
- 3
|
||||||
|
- 4
|
||||||
|
proj_dim: 16
|
||||||
|
image_rescale: 0.32
|
||||||
|
first_max_pool: false
|
||||||
|
solver_args:
|
||||||
|
breed: adam
|
||||||
|
lr: 0.0005
|
||||||
|
lr_policy: multistep
|
||||||
|
max_epochs: 2000
|
||||||
|
momentum: 0.9
|
||||||
|
weight_decay: 0.0
|
||||||
@@ -0,0 +1,17 @@
|
|||||||
|
generic_model_args:
|
||||||
|
image_feature_extractor_class_type: ResNetFeatureExtractor
|
||||||
|
image_feature_extractor_ResNetFeatureExtractor_args:
|
||||||
|
add_images: true
|
||||||
|
add_masks: true
|
||||||
|
first_max_pool: true
|
||||||
|
image_rescale: 0.375
|
||||||
|
l2_norm: true
|
||||||
|
name: resnet34
|
||||||
|
normalize_image: true
|
||||||
|
pretrained: true
|
||||||
|
stages:
|
||||||
|
- 1
|
||||||
|
- 2
|
||||||
|
- 3
|
||||||
|
- 4
|
||||||
|
proj_dim: 32
|
||||||
@@ -0,0 +1,17 @@
|
|||||||
|
generic_model_args:
|
||||||
|
image_feature_extractor_class_type: ResNetFeatureExtractor
|
||||||
|
image_feature_extractor_ResNetFeatureExtractor_args:
|
||||||
|
add_images: true
|
||||||
|
add_masks: true
|
||||||
|
first_max_pool: false
|
||||||
|
image_rescale: 0.375
|
||||||
|
l2_norm: true
|
||||||
|
name: resnet34
|
||||||
|
normalize_image: true
|
||||||
|
pretrained: true
|
||||||
|
stages:
|
||||||
|
- 1
|
||||||
|
- 2
|
||||||
|
- 3
|
||||||
|
- 4
|
||||||
|
proj_dim: 16
|
||||||
@@ -0,0 +1,18 @@
|
|||||||
|
generic_model_args:
|
||||||
|
image_feature_extractor_class_type: ResNetFeatureExtractor
|
||||||
|
image_feature_extractor_ResNetFeatureExtractor_args:
|
||||||
|
stages:
|
||||||
|
- 1
|
||||||
|
- 2
|
||||||
|
- 3
|
||||||
|
first_max_pool: false
|
||||||
|
proj_dim: -1
|
||||||
|
l2_norm: false
|
||||||
|
image_rescale: 0.375
|
||||||
|
name: resnet34
|
||||||
|
normalize_image: true
|
||||||
|
pretrained: true
|
||||||
|
view_pooler_args:
|
||||||
|
feature_aggregator_AngleWeightedReductionFeatureAggregator_args:
|
||||||
|
reduction_functions:
|
||||||
|
- AVG
|
||||||
@@ -0,0 +1,35 @@
|
|||||||
|
defaults:
|
||||||
|
- repro_base.yaml
|
||||||
|
- _self_
|
||||||
|
data_source_args:
|
||||||
|
data_loader_map_provider_SequenceDataLoaderMapProvider_args:
|
||||||
|
batch_size: 10
|
||||||
|
dataset_length_train: 1000
|
||||||
|
dataset_length_val: 1
|
||||||
|
num_workers: 8
|
||||||
|
train_conditioning_type: SAME
|
||||||
|
val_conditioning_type: SAME
|
||||||
|
test_conditioning_type: SAME
|
||||||
|
images_per_seq_options:
|
||||||
|
- 2
|
||||||
|
- 3
|
||||||
|
- 4
|
||||||
|
- 5
|
||||||
|
- 6
|
||||||
|
- 7
|
||||||
|
- 8
|
||||||
|
- 9
|
||||||
|
- 10
|
||||||
|
dataset_map_provider_JsonIndexDatasetMapProvider_args:
|
||||||
|
assert_single_seq: false
|
||||||
|
task_str: multisequence
|
||||||
|
n_frames_per_sequence: -1
|
||||||
|
test_on_train: true
|
||||||
|
test_restrict_sequence_id: 0
|
||||||
|
solver_args:
|
||||||
|
max_epochs: 3000
|
||||||
|
milestones:
|
||||||
|
- 1000
|
||||||
|
camera_difficulty_bin_breaks:
|
||||||
|
- 0.666667
|
||||||
|
- 0.833334
|
||||||
@@ -0,0 +1,65 @@
|
|||||||
|
defaults:
|
||||||
|
- repro_multiseq_base.yaml
|
||||||
|
- _self_
|
||||||
|
generic_model_args:
|
||||||
|
loss_weights:
|
||||||
|
loss_mask_bce: 100.0
|
||||||
|
loss_kl: 0.0
|
||||||
|
loss_rgb_mse: 1.0
|
||||||
|
loss_eikonal: 0.1
|
||||||
|
chunk_size_grid: 65536
|
||||||
|
num_passes: 1
|
||||||
|
output_rasterized_mc: true
|
||||||
|
sampling_mode_training: mask_sample
|
||||||
|
global_encoder_class_type: SequenceAutodecoder
|
||||||
|
global_encoder_SequenceAutodecoder_args:
|
||||||
|
autodecoder_args:
|
||||||
|
n_instances: 20000
|
||||||
|
init_scale: 1.0
|
||||||
|
encoding_dim: 256
|
||||||
|
implicit_function_IdrFeatureField_args:
|
||||||
|
n_harmonic_functions_xyz: 6
|
||||||
|
bias: 0.6
|
||||||
|
d_in: 3
|
||||||
|
d_out: 1
|
||||||
|
dims:
|
||||||
|
- 512
|
||||||
|
- 512
|
||||||
|
- 512
|
||||||
|
- 512
|
||||||
|
- 512
|
||||||
|
- 512
|
||||||
|
- 512
|
||||||
|
- 512
|
||||||
|
geometric_init: true
|
||||||
|
pooled_feature_dim: 0
|
||||||
|
skip_in:
|
||||||
|
- 6
|
||||||
|
weight_norm: true
|
||||||
|
renderer_SignedDistanceFunctionRenderer_args:
|
||||||
|
ray_tracer_args:
|
||||||
|
line_search_step: 0.5
|
||||||
|
line_step_iters: 3
|
||||||
|
n_secant_steps: 8
|
||||||
|
n_steps: 100
|
||||||
|
object_bounding_sphere: 8.0
|
||||||
|
sdf_threshold: 5.0e-05
|
||||||
|
ray_normal_coloring_network_args:
|
||||||
|
d_in: 9
|
||||||
|
d_out: 3
|
||||||
|
dims:
|
||||||
|
- 512
|
||||||
|
- 512
|
||||||
|
- 512
|
||||||
|
- 512
|
||||||
|
mode: idr
|
||||||
|
n_harmonic_functions_dir: 4
|
||||||
|
pooled_feature_dim: 0
|
||||||
|
weight_norm: true
|
||||||
|
raysampler_AdaptiveRaySampler_args:
|
||||||
|
n_rays_per_image_sampled_from_mask: 1024
|
||||||
|
n_pts_per_ray_training: 0
|
||||||
|
n_pts_per_ray_evaluation: 0
|
||||||
|
scene_extent: 8.0
|
||||||
|
renderer_class_type: SignedDistanceFunctionRenderer
|
||||||
|
implicit_function_class_type: IdrFeatureField
|
||||||
@@ -0,0 +1,11 @@
|
|||||||
|
defaults:
|
||||||
|
- repro_multiseq_base.yaml
|
||||||
|
- _self_
|
||||||
|
generic_model_args:
|
||||||
|
chunk_size_grid: 16000
|
||||||
|
view_pooler_enabled: false
|
||||||
|
global_encoder_class_type: SequenceAutodecoder
|
||||||
|
global_encoder_SequenceAutodecoder_args:
|
||||||
|
autodecoder_args:
|
||||||
|
n_instances: 20000
|
||||||
|
encoding_dim: 256
|
||||||
@@ -0,0 +1,10 @@
|
|||||||
|
defaults:
|
||||||
|
- repro_multiseq_base.yaml
|
||||||
|
- repro_feat_extractor_unnormed.yaml
|
||||||
|
- _self_
|
||||||
|
clip_grad: 1.0
|
||||||
|
generic_model_args:
|
||||||
|
chunk_size_grid: 16000
|
||||||
|
view_pooler_enabled: true
|
||||||
|
raysampler_AdaptiveRaySampler_args:
|
||||||
|
n_rays_per_image_sampled_from_mask: 850
|
||||||
@@ -0,0 +1,17 @@
|
|||||||
|
defaults:
|
||||||
|
- repro_multiseq_base.yaml
|
||||||
|
- repro_feat_extractor_transformer.yaml
|
||||||
|
- _self_
|
||||||
|
generic_model_args:
|
||||||
|
chunk_size_grid: 16000
|
||||||
|
raysampler_AdaptiveRaySampler_args:
|
||||||
|
n_rays_per_image_sampled_from_mask: 800
|
||||||
|
n_pts_per_ray_training: 32
|
||||||
|
n_pts_per_ray_evaluation: 32
|
||||||
|
renderer_MultiPassEmissionAbsorptionRenderer_args:
|
||||||
|
n_pts_per_ray_fine_training: 16
|
||||||
|
n_pts_per_ray_fine_evaluation: 16
|
||||||
|
implicit_function_class_type: NeRFormerImplicitFunction
|
||||||
|
view_pooler_enabled: true
|
||||||
|
view_pooler_args:
|
||||||
|
feature_aggregator_class_type: IdentityFeatureAggregator
|
||||||
@@ -0,0 +1,6 @@
|
|||||||
|
defaults:
|
||||||
|
- repro_multiseq_nerformer.yaml
|
||||||
|
- _self_
|
||||||
|
generic_model_args:
|
||||||
|
view_pooler_args:
|
||||||
|
feature_aggregator_class_type: AngleWeightedIdentityFeatureAggregator
|
||||||
@@ -0,0 +1,34 @@
|
|||||||
|
defaults:
|
||||||
|
- repro_multiseq_base.yaml
|
||||||
|
- _self_
|
||||||
|
generic_model_args:
|
||||||
|
chunk_size_grid: 16000
|
||||||
|
view_pooler_enabled: false
|
||||||
|
n_train_target_views: -1
|
||||||
|
num_passes: 1
|
||||||
|
loss_weights:
|
||||||
|
loss_rgb_mse: 200.0
|
||||||
|
loss_prev_stage_rgb_mse: 0.0
|
||||||
|
loss_mask_bce: 1.0
|
||||||
|
loss_prev_stage_mask_bce: 0.0
|
||||||
|
loss_autodecoder_norm: 0.001
|
||||||
|
depth_neg_penalty: 10000.0
|
||||||
|
global_encoder_class_type: SequenceAutodecoder
|
||||||
|
global_encoder_SequenceAutodecoder_args:
|
||||||
|
autodecoder_args:
|
||||||
|
encoding_dim: 256
|
||||||
|
n_instances: 20000
|
||||||
|
raysampler_class_type: NearFarRaySampler
|
||||||
|
raysampler_NearFarRaySampler_args:
|
||||||
|
n_rays_per_image_sampled_from_mask: 2048
|
||||||
|
min_depth: 0.05
|
||||||
|
max_depth: 0.05
|
||||||
|
n_pts_per_ray_training: 1
|
||||||
|
n_pts_per_ray_evaluation: 1
|
||||||
|
stratified_point_sampling_training: false
|
||||||
|
stratified_point_sampling_evaluation: false
|
||||||
|
renderer_class_type: LSTMRenderer
|
||||||
|
implicit_function_class_type: SRNHyperNetImplicitFunction
|
||||||
|
solver_args:
|
||||||
|
breed: adam
|
||||||
|
lr: 5.0e-05
|
||||||
@@ -0,0 +1,10 @@
|
|||||||
|
defaults:
|
||||||
|
- repro_multiseq_srn_ad_hypernet.yaml
|
||||||
|
- _self_
|
||||||
|
generic_model_args:
|
||||||
|
num_passes: 1
|
||||||
|
implicit_function_SRNHyperNetImplicitFunction_args:
|
||||||
|
pixel_generator_args:
|
||||||
|
n_harmonic_functions: 0
|
||||||
|
hypernet_args:
|
||||||
|
n_harmonic_functions: 0
|
||||||
@@ -0,0 +1,30 @@
|
|||||||
|
defaults:
|
||||||
|
- repro_multiseq_base.yaml
|
||||||
|
- repro_feat_extractor_normed.yaml
|
||||||
|
- _self_
|
||||||
|
generic_model_args:
|
||||||
|
chunk_size_grid: 32000
|
||||||
|
num_passes: 1
|
||||||
|
n_train_target_views: -1
|
||||||
|
loss_weights:
|
||||||
|
loss_rgb_mse: 200.0
|
||||||
|
loss_prev_stage_rgb_mse: 0.0
|
||||||
|
loss_mask_bce: 1.0
|
||||||
|
loss_prev_stage_mask_bce: 0.0
|
||||||
|
loss_autodecoder_norm: 0.0
|
||||||
|
depth_neg_penalty: 10000.0
|
||||||
|
raysampler_class_type: NearFarRaySampler
|
||||||
|
raysampler_NearFarRaySampler_args:
|
||||||
|
n_rays_per_image_sampled_from_mask: 2048
|
||||||
|
min_depth: 0.05
|
||||||
|
max_depth: 0.05
|
||||||
|
n_pts_per_ray_training: 1
|
||||||
|
n_pts_per_ray_evaluation: 1
|
||||||
|
stratified_point_sampling_training: false
|
||||||
|
stratified_point_sampling_evaluation: false
|
||||||
|
renderer_class_type: LSTMRenderer
|
||||||
|
implicit_function_class_type: SRNImplicitFunction
|
||||||
|
view_pooler_enabled: true
|
||||||
|
solver_args:
|
||||||
|
breed: adam
|
||||||
|
lr: 5.0e-05
|
||||||
@@ -0,0 +1,10 @@
|
|||||||
|
defaults:
|
||||||
|
- repro_multiseq_srn_wce.yaml
|
||||||
|
- _self_
|
||||||
|
generic_model_args:
|
||||||
|
num_passes: 1
|
||||||
|
implicit_function_SRNImplicitFunction_args:
|
||||||
|
pixel_generator_args:
|
||||||
|
n_harmonic_functions: 0
|
||||||
|
raymarch_function_args:
|
||||||
|
n_harmonic_functions: 0
|
||||||
@@ -0,0 +1,39 @@
|
|||||||
|
defaults:
|
||||||
|
- repro_base
|
||||||
|
- _self_
|
||||||
|
data_source_args:
|
||||||
|
data_loader_map_provider_SequenceDataLoaderMapProvider_args:
|
||||||
|
batch_size: 1
|
||||||
|
dataset_length_train: 1000
|
||||||
|
dataset_length_val: 1
|
||||||
|
num_workers: 8
|
||||||
|
dataset_map_provider_JsonIndexDatasetMapProvider_args:
|
||||||
|
assert_single_seq: true
|
||||||
|
n_frames_per_sequence: -1
|
||||||
|
test_restrict_sequence_id: 0
|
||||||
|
test_on_train: false
|
||||||
|
generic_model_args:
|
||||||
|
render_image_height: 800
|
||||||
|
render_image_width: 800
|
||||||
|
log_vars:
|
||||||
|
- loss_rgb_psnr_fg
|
||||||
|
- loss_rgb_psnr
|
||||||
|
- loss_eikonal
|
||||||
|
- loss_prev_stage_rgb_psnr
|
||||||
|
- loss_mask_bce
|
||||||
|
- loss_prev_stage_mask_bce
|
||||||
|
- loss_rgb_mse
|
||||||
|
- loss_prev_stage_rgb_mse
|
||||||
|
- loss_depth_abs
|
||||||
|
- loss_depth_abs_fg
|
||||||
|
- loss_kl
|
||||||
|
- loss_mask_neg_iou
|
||||||
|
- objective
|
||||||
|
- epoch
|
||||||
|
- sec/it
|
||||||
|
solver_args:
|
||||||
|
lr: 0.0005
|
||||||
|
max_epochs: 400
|
||||||
|
milestones:
|
||||||
|
- 200
|
||||||
|
- 300
|
||||||
@@ -0,0 +1,57 @@
|
|||||||
|
defaults:
|
||||||
|
- repro_singleseq_base
|
||||||
|
- _self_
|
||||||
|
generic_model_args:
|
||||||
|
loss_weights:
|
||||||
|
loss_mask_bce: 100.0
|
||||||
|
loss_kl: 0.0
|
||||||
|
loss_rgb_mse: 1.0
|
||||||
|
loss_eikonal: 0.1
|
||||||
|
chunk_size_grid: 65536
|
||||||
|
num_passes: 1
|
||||||
|
view_pooler_enabled: false
|
||||||
|
implicit_function_IdrFeatureField_args:
|
||||||
|
n_harmonic_functions_xyz: 6
|
||||||
|
bias: 0.6
|
||||||
|
d_in: 3
|
||||||
|
d_out: 1
|
||||||
|
dims:
|
||||||
|
- 512
|
||||||
|
- 512
|
||||||
|
- 512
|
||||||
|
- 512
|
||||||
|
- 512
|
||||||
|
- 512
|
||||||
|
- 512
|
||||||
|
- 512
|
||||||
|
geometric_init: true
|
||||||
|
pooled_feature_dim: 0
|
||||||
|
skip_in:
|
||||||
|
- 6
|
||||||
|
weight_norm: true
|
||||||
|
renderer_SignedDistanceFunctionRenderer_args:
|
||||||
|
ray_tracer_args:
|
||||||
|
line_search_step: 0.5
|
||||||
|
line_step_iters: 3
|
||||||
|
n_secant_steps: 8
|
||||||
|
n_steps: 100
|
||||||
|
object_bounding_sphere: 8.0
|
||||||
|
sdf_threshold: 5.0e-05
|
||||||
|
ray_normal_coloring_network_args:
|
||||||
|
d_in: 9
|
||||||
|
d_out: 3
|
||||||
|
dims:
|
||||||
|
- 512
|
||||||
|
- 512
|
||||||
|
- 512
|
||||||
|
- 512
|
||||||
|
mode: idr
|
||||||
|
n_harmonic_functions_dir: 4
|
||||||
|
pooled_feature_dim: 0
|
||||||
|
weight_norm: true
|
||||||
|
raysampler_AdaptiveRaySampler_args:
|
||||||
|
n_rays_per_image_sampled_from_mask: 1024
|
||||||
|
n_pts_per_ray_training: 0
|
||||||
|
n_pts_per_ray_evaluation: 0
|
||||||
|
renderer_class_type: SignedDistanceFunctionRenderer
|
||||||
|
implicit_function_class_type: IdrFeatureField
|
||||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user