Summary: Cpu implementation for packed to padded and added gradients ``` Benchmark Avg Time(μs) Peak Time(μs) Iterations -------------------------------------------------------------------------------- PACKED_TO_PADDED_2_100_300_1_cpu 138 221 3625 PACKED_TO_PADDED_2_100_300_1_cuda:0 184 261 2716 PACKED_TO_PADDED_2_100_300_16_cpu 555 726 901 PACKED_TO_PADDED_2_100_300_16_cuda:0 179 260 2794 PACKED_TO_PADDED_2_100_3000_1_cpu 396 519 1262 PACKED_TO_PADDED_2_100_3000_1_cuda:0 181 274 2764 PACKED_TO_PADDED_2_100_3000_16_cpu 4517 5003 111 PACKED_TO_PADDED_2_100_3000_16_cuda:0 224 397 2235 PACKED_TO_PADDED_2_1000_300_1_cpu 138 212 3616 PACKED_TO_PADDED_2_1000_300_1_cuda:0 180 282 2775 PACKED_TO_PADDED_2_1000_300_16_cpu 565 711 885 PACKED_TO_PADDED_2_1000_300_16_cuda:0 179 264 2797 PACKED_TO_PADDED_2_1000_3000_1_cpu 389 494 1287 PACKED_TO_PADDED_2_1000_3000_1_cuda:0 180 271 2777 PACKED_TO_PADDED_2_1000_3000_16_cpu 4522 5170 111 PACKED_TO_PADDED_2_1000_3000_16_cuda:0 216 286 2313 PACKED_TO_PADDED_10_100_300_1_cpu 251 345 1995 PACKED_TO_PADDED_10_100_300_1_cuda:0 178 262 2806 PACKED_TO_PADDED_10_100_300_16_cpu 2354 2750 213 PACKED_TO_PADDED_10_100_300_16_cuda:0 178 291 2814 PACKED_TO_PADDED_10_100_3000_1_cpu 1519 1786 330 PACKED_TO_PADDED_10_100_3000_1_cuda:0 179 237 2791 PACKED_TO_PADDED_10_100_3000_16_cpu 24705 25879 21 PACKED_TO_PADDED_10_100_3000_16_cuda:0 228 316 2191 PACKED_TO_PADDED_10_1000_300_1_cpu 261 432 1919 PACKED_TO_PADDED_10_1000_300_1_cuda:0 181 261 2756 PACKED_TO_PADDED_10_1000_300_16_cpu 2349 2770 213 PACKED_TO_PADDED_10_1000_300_16_cuda:0 180 256 2782 PACKED_TO_PADDED_10_1000_3000_1_cpu 1613 1929 310 PACKED_TO_PADDED_10_1000_3000_1_cuda:0 183 253 2739 PACKED_TO_PADDED_10_1000_3000_16_cpu 22041 23653 23 PACKED_TO_PADDED_10_1000_3000_16_cuda:0 220 343 2270 PACKED_TO_PADDED_32_100_300_1_cpu 555 750 901 PACKED_TO_PADDED_32_100_300_1_cuda:0 188 282 2661 PACKED_TO_PADDED_32_100_300_16_cpu 7550 8131 67 PACKED_TO_PADDED_32_100_300_16_cuda:0 181 272 2770 PACKED_TO_PADDED_32_100_3000_1_cpu 4574 6327 110 PACKED_TO_PADDED_32_100_3000_1_cuda:0 173 254 2884 PACKED_TO_PADDED_32_100_3000_16_cpu 70366 72563 8 PACKED_TO_PADDED_32_100_3000_16_cuda:0 349 654 1433 PACKED_TO_PADDED_32_1000_300_1_cpu 612 728 818 PACKED_TO_PADDED_32_1000_300_1_cuda:0 189 295 2647 PACKED_TO_PADDED_32_1000_300_16_cpu 7699 8254 65 PACKED_TO_PADDED_32_1000_300_16_cuda:0 189 311 2646 PACKED_TO_PADDED_32_1000_3000_1_cpu 5105 5261 98 PACKED_TO_PADDED_32_1000_3000_1_cuda:0 191 260 2625 PACKED_TO_PADDED_32_1000_3000_16_cpu 87073 92708 6 PACKED_TO_PADDED_32_1000_3000_16_cuda:0 344 425 1455 -------------------------------------------------------------------------------- Benchmark Avg Time(μs) Peak Time(μs) Iterations -------------------------------------------------------------------------------- PACKED_TO_PADDED_TORCH_2_100_300_1_cpu 492 627 1016 PACKED_TO_PADDED_TORCH_2_100_300_1_cuda:0 768 975 652 PACKED_TO_PADDED_TORCH_2_100_300_16_cpu 659 804 760 PACKED_TO_PADDED_TORCH_2_100_300_16_cuda:0 781 918 641 PACKED_TO_PADDED_TORCH_2_100_3000_1_cpu 624 734 802 PACKED_TO_PADDED_TORCH_2_100_3000_1_cuda:0 778 929 643 PACKED_TO_PADDED_TORCH_2_100_3000_16_cpu 2609 2850 192 PACKED_TO_PADDED_TORCH_2_100_3000_16_cuda:0 758 901 660 PACKED_TO_PADDED_TORCH_2_1000_300_1_cpu 467 612 1072 PACKED_TO_PADDED_TORCH_2_1000_300_1_cuda:0 772 905 648 PACKED_TO_PADDED_TORCH_2_1000_300_16_cpu 689 839 726 PACKED_TO_PADDED_TORCH_2_1000_300_16_cuda:0 789 1143 635 PACKED_TO_PADDED_TORCH_2_1000_3000_1_cpu 629 735 795 PACKED_TO_PADDED_TORCH_2_1000_3000_1_cuda:0 812 916 616 PACKED_TO_PADDED_TORCH_2_1000_3000_16_cpu 2716 3117 185 PACKED_TO_PADDED_TORCH_2_1000_3000_16_cuda:0 844 1288 593 PACKED_TO_PADDED_TORCH_10_100_300_1_cpu 2387 2557 210 PACKED_TO_PADDED_TORCH_10_100_300_1_cuda:0 4112 4993 122 PACKED_TO_PADDED_TORCH_10_100_300_16_cpu 3385 4254 148 PACKED_TO_PADDED_TORCH_10_100_300_16_cuda:0 3959 4902 127 PACKED_TO_PADDED_TORCH_10_100_3000_1_cpu 2918 3105 172 PACKED_TO_PADDED_TORCH_10_100_3000_1_cuda:0 4054 4450 124 PACKED_TO_PADDED_TORCH_10_100_3000_16_cpu 12748 13623 40 PACKED_TO_PADDED_TORCH_10_100_3000_16_cuda:0 4023 4395 125 PACKED_TO_PADDED_TORCH_10_1000_300_1_cpu 2258 2492 222 PACKED_TO_PADDED_TORCH_10_1000_300_1_cuda:0 3997 4312 126 PACKED_TO_PADDED_TORCH_10_1000_300_16_cpu 3404 3597 147 PACKED_TO_PADDED_TORCH_10_1000_300_16_cuda:0 3877 4227 129 PACKED_TO_PADDED_TORCH_10_1000_3000_1_cpu 2789 3054 180 PACKED_TO_PADDED_TORCH_10_1000_3000_1_cuda:0 3821 4402 131 PACKED_TO_PADDED_TORCH_10_1000_3000_16_cpu 11967 12963 42 PACKED_TO_PADDED_TORCH_10_1000_3000_16_cuda:0 3729 4290 135 PACKED_TO_PADDED_TORCH_32_100_300_1_cpu 6933 8152 73 PACKED_TO_PADDED_TORCH_32_100_300_1_cuda:0 11856 12287 43 PACKED_TO_PADDED_TORCH_32_100_300_16_cpu 9895 11205 51 PACKED_TO_PADDED_TORCH_32_100_300_16_cuda:0 12354 13596 41 PACKED_TO_PADDED_TORCH_32_100_3000_1_cpu 9516 10128 53 PACKED_TO_PADDED_TORCH_32_100_3000_1_cuda:0 12917 13597 39 PACKED_TO_PADDED_TORCH_32_100_3000_16_cpu 41209 43783 13 PACKED_TO_PADDED_TORCH_32_100_3000_16_cuda:0 12210 13288 41 PACKED_TO_PADDED_TORCH_32_1000_300_1_cpu 7179 7689 70 PACKED_TO_PADDED_TORCH_32_1000_300_1_cuda:0 11896 12381 43 PACKED_TO_PADDED_TORCH_32_1000_300_16_cpu 10127 15494 50 PACKED_TO_PADDED_TORCH_32_1000_300_16_cuda:0 12034 12817 42 PACKED_TO_PADDED_TORCH_32_1000_3000_1_cpu 8743 10251 58 PACKED_TO_PADDED_TORCH_32_1000_3000_1_cuda:0 12023 12908 42 PACKED_TO_PADDED_TORCH_32_1000_3000_16_cpu 39071 41777 13 PACKED_TO_PADDED_TORCH_32_1000_3000_16_cuda:0 11999 13690 42 -------------------------------------------------------------------------------- ``` Reviewed By: bottler, nikhilaravi, jcjohnson Differential Revision: D19870575 fbshipit-source-id: 23a2477b73373c411899633386c87ab034c3702a



Introduction
PyTorch3d provides efficient, reusable components for 3D Computer Vision research with PyTorch.
Key features include:
- Data structure for storing and manipulating triangle meshes
- Efficient operations on triangle meshes (projective transformations, graph convolution, sampling, loss functions)
- A differentiable mesh renderer
PyTorch3d is designed to integrate smoothly with deep learning methods for predicting and manipulating 3D data. For this reason, all operators in PyTorch3d:
- Are implemented using PyTorch tensors
- Can handle minibatches of hetereogenous data
- Can be differentiated
- Can utilize GPUs for acceleration
Within FAIR, PyTorch3d has been used to power research projects such as Mesh R-CNN.
Installation
For detailed instructions refer to INSTALL.md.
License
PyTorch3d is released under the BSD-3-Clause License.
Tutorials
Get started with PyTorch3d by trying one of the tutorial notebooks.
 |
 |
|---|---|
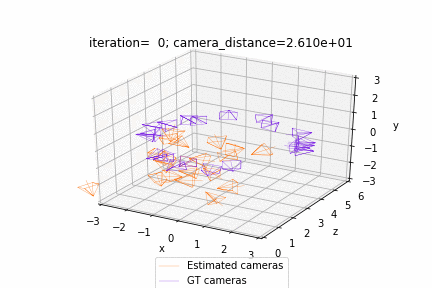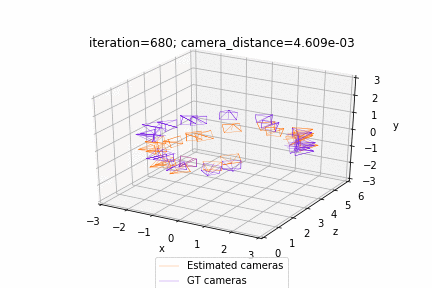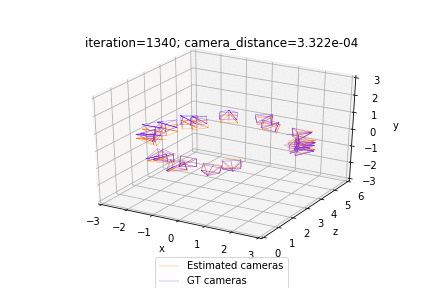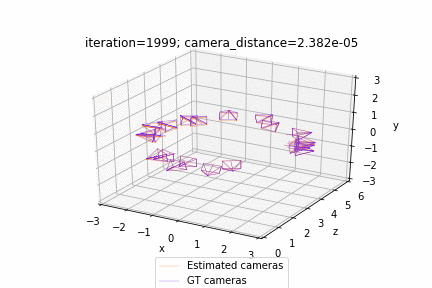
| Deform a sphere mesh to dolphin | Bundle adjustment |
 |
 |
|---|---|
| Render textured meshes | Camera position optimization |
Documentation
Learn more about the API by reading the PyTorch3d documentation.
We also have deep dive notes on several API components:
Development
We welcome new contributions to Pytorch3d and we will be actively maintaining this library! Please refer to CONTRIBUTING.md for full instructions on how to run the code, tests and linter, and submit your pull requests.
Contributors
PyTorch3d is written and maintained by the Facebook AI Research Computer Vision Team.
Citation
If you find PyTorch3d useful in your research, please cite:
@misc{ravi2020pytorch3d,
author = {Nikhila Ravi and Jeremy Reizenstein and David Novotny and Taylor Gordon
and Wan-Yen Lo and Justin Johnson and Georgia Gkioxari},
title = {PyTorch3D},
howpublished = {\url{https://github.com/facebookresearch/pytorch3d}},
year = {2020}
}